


Полная версия
Искусственный интеллект в лучевой диагностике: Per Aspera Ad Astra
Для тестирования и оценки эксплуатационных характеристик СИИ в набор данных целесообразно добавлять тест-случаи (контрольные тесты), соответствующие ситуациям, сложным для классификации экспертами: данные с высоким уровнем шума либо с ухудшенными характеристиками (например, в результате сбоя оборудования), изображения с недостаточной видимостью целевых объектов, изображения нерелевантных анатомических областей или видов исследований. Включение таких данных позволит проверить устойчивость СИИ в дополнение к заявленным эксплуатационным характеристикам61.
Принципы сбора данных для аналитической валидации62:
1. НД пригоден для определения следующих характеристик: производительность (например, время, затрачиваемое на обработку СИИ медицинского исследования при наличии функции автоматического расчета времени и т.д.), точность интерпретации исследований с учетом функциональных возможностей СИИ, повторяемость, воспроизводимость.
2. НД может включать элементы с нарушением технологии (внешние помехи, артефакты, неверное наложение электродов/датчиков, нарушение последовательности регистрации, укладки пациента и т.п.). При этом такие элементы должны быть помечены должным образом (например, посредством меток в метаданных).
3. При формировании использованы данные из разных медицинских организаций и разных моделей/производителей оборудования, обработку данных с которых изготовитель СИИ включает в функциональное назначение.
Принципы сбора данных для клинической валидации:
1. НД должен быть верифицированным.
2. Сбор данных проводится с учетом следующих аспектов63:
– соотношение «норма»/«патология» или разные заболевания в НД определяют областью применения СИИ;
– используют данные из разных медицинских организаций и разных моделей/производителя оборудования;
– демографические, социально-экономические характеристики и основные показатели здоровья пациентов (репрезентативная выборка) должны соответствовать усредненным характеристикам популяции территории, на которой планируется использование СИИ;
– планируемый размер набора данных должен быть обоснован в документации испытаний, исходя из статистических соображений и желаемой точности оценки основных метрик (подробнее см. подпараграф 2.3.1).
NB! Принцип многоцентрового сбора данных особо важен для снижения систематической ошибки, так как невключение в НД элементов, получаемых на некой модели оборудования, может привести к разнообразным ограничениям и рискам. Возможно использовать данные из разных медицинских организаций, но обладающие одинаковой структурой и полученные в результате применения оборудования с одинаковым процессом работы (одинаковая модель/производитель)64.
На первых этапах Московского эксперимента сбор данных производился вручную «на потоке»: врач-рентгенолог при просмотре исследований в ЕРИС ЕМИАС фиксировал номера подходящих исследований, а в дальнейшем они отправлялись на разметку. Далее это процесс был оптимизирован путем автоматизации работы с текстовыми протоколами заключений; для этого был разработан инструмент MedLabel65. Из ЕРИС ЕМИАС выгружались анонимизированные текстовые протоколы заключений, далее проводилась предразметка с помощью MedLabel (формировалась таблица, включающая номер исследования, протокол, разметку), после чего врач-рентгенолог пересматривал заключения и корректировал разметку на основании текста. Это позволило существенно ускорить процесс сбора данных, однако применение разработанного программного обеспечения требовало привлечения дополнительного технического специалиста, а в дальнейшем, при расширении направлений Московского эксперимента, Medlabel потребовал доработки. Тогда был реализован более простой метод отбора исследований по «ключевым словам» и «стоп-конструкциям»: специальный алгоритм анализировал наличие слов, характерных для целевой патологии, а также слов, говорящих об отсутствии патологии (например, «не выявлено», «отсутствуют», «без признаков»), и на основании этого присваивал значение разметки. Этот принцип лег в основу разработки инструмента поиска исследований (рисунок 2.11). Он имеет интуитивно понятный интерфейс и позволяет отбирать исследования путем фильтрации по его модальности, процедуре, датам проведения, возрасту пациента, среди которых происходит поиск целевых патологий по текстовым протоколам (рисунок 2.11а). В результате формируется таблица с номерами исследований, текстовыми протоколами и предварительной разметкой. Далее исследования, если требуется, пересматриваются врачом-рентгенологом в подмодуле пересмотра, в основу которого положен инструмент с открытым кодом LabelStudio (рисунок 2.11б). Результат работы модуля – сформированный список идентификаторов исследований с разметкой по текстовым протоколам.
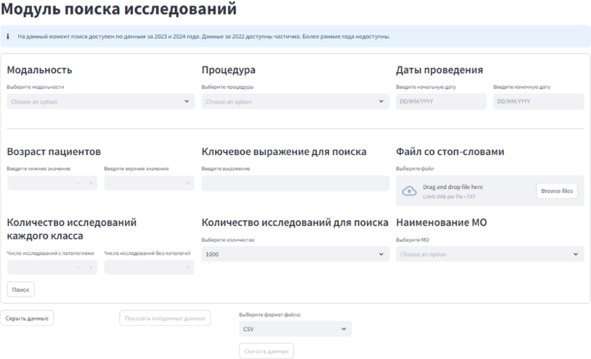
Рисунок 2.11а – Модуль поиска исследований
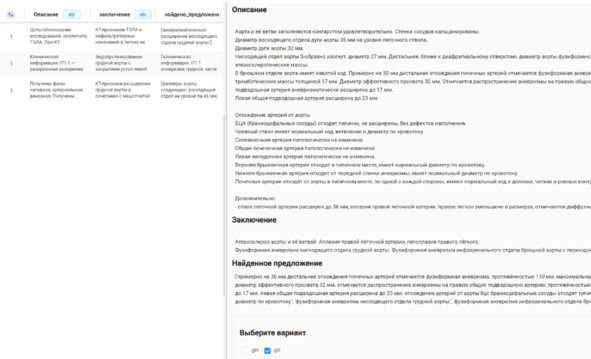
Рисунок 2.11б – Модуль пересмотра исследований (слева фрагмент выгруженной из модуля поиска таблицы с предварительной разметкой с указанием найденной фразы/слов, относящихся к целевой патологии, справа— окно отображения текстового протокола и форма для разметки)
Выгрузка и деидентификация (анонимизация) исследований. Эти два процесса неразрывно связаны между собой, т.к. выгрузка без анонимизации повышает риск утечки персональных данных и нарушает принципы информационной безопасности. В начале Московского эксперимента этот этап следовал после разметки, т.е. разметчики просматривали исследования в ЕРИС ЕМИАС, а процесс выгрузки и анонимизации завершал формирование НД. Выгрузка производилась с помощью специально разработанного кода. На «Платформе подготовки наборов данных» данный функционал реализован в виде специального модуля: загружается таблица из модуля поиска, настраивается ряд параметров (диапазон дат, модальность, кластер) и производятся выгрузка и анонимизация исследований (можно выбрать отдельные серии или исследования из списка) (рисунок 2.12).
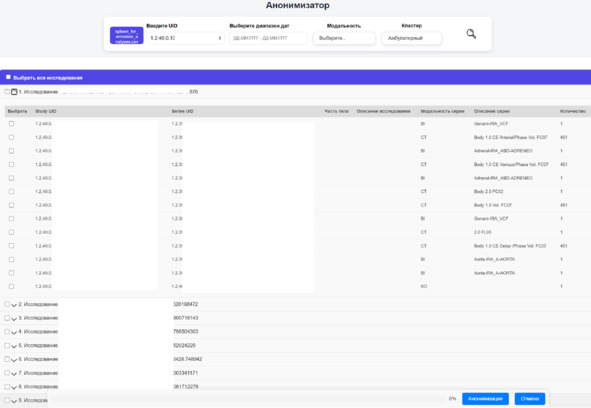
Рисунок 2.12 – Модуль выгрузки и анонимизации исследований из ЕРИС ЕМИАС
Относительно деидентификации необходимо указать, что в целом элементы НД не должны содержать какую-либо персональную информацию согласно действующим нормативно-правовым актам; любая персональная информация должна быть удалена как из метаданных, так и из исходных данных. Также должны быть удалены любые иные идентификаторы, с помощью которых потенциально возможно установить личность пациента. Деидентификация данных должна быть произведена в МО, в которой было проведено медицинское исследование, при условии наличия согласия пациента на обработку его персональных данных, включая деидентификацию (обезличивание)66.
Деидентификация метаданных и изображений в формате DICOM проводится в соответствии с ГОСТ Р 71674—202467.
Разметка (аннотация).
В глобальной перспективе существуют два условно стандартизированных подхода к разметке (аннотированию) медицинских данных68:
1. «Аннотация и разметка изображений» (англ. annotation and image markup (AIM)). Использует три базовых концепта:
1) визуальные наблюдения («масса», «поражение», «очаг»);
2) анатомические объекты («затылочная доля», «теменная доля», «медиальный сегмент средней доли правого легкого»);
3) интерференция (нарушение) (поражение речевого центра», «плевральный выпот», «пневмония»).
Визуальным наблюдениям и анатомическим объектам задают характеристики. Например, характеристики наблюдений – «предполагаемый», «кистозный», объектов – «расширенный», «разорванный». После задания характеристик наблюдений и объектов проводят их количественную оценку. Ее допустимо выражать в терминах «присутствует», «отсутствует», «не применимо» либо квартиль/процентиль, либо в произвольной шкале и др. Проводят совмещение этой описательной информации с графическими символами, располагаемыми экспертами на самом изображении, в единый тип данных.
2. «Состояние представления DICOM» (англ. DICOM Presentation State (PS)). Независимый экземпляр класса типовой инструкции DICOM, который содержит информацию о том, как должно отображаться конкретное изображение с использованием всех возможных параметров и визуальных элементов, определенных в стандарте DICOM. Позволяет без потерь вернуться к оригинальному изображению, поскольку никак не модифицирует пиксельные данные.
В рамках Московского эксперимента были выделены и применялись как основные два иных подхода69:
1. Полуструктурированное текстовое описание визуальных наблюдений с указанием содержащих их анатомических объектов и типов нарушений. В лучевой диагностике вариативность терминологии и структуры описаний результатов исследований, а также ориентировочный характер локализации наблюдений делает крайне сложными и малоэффективными автоматический поиск по таким аннотациям и их применение для обучения или тестирования СИИ.
2. Структурированная аннотация, которая должна использовать согласованный набор терминов для снижения вариабельности интерпретаций визуальных наблюдений. В лучевой диагностике такая аннотация может быть сопровождена конкретизированной информацией о локализации наблюдений, которую могут выполнять с разным уровнем точности и детализации:
– с грубой локализацией – приблизительное обозначение координат объектов интереса, посредством задания ограничивающего параллелепипеда или эллипсоида;
– с полной сегментацией на основе маски минимальных элементов, обозначающей положение объекта интереса на фоне остальной части данных.
В лучевой диагностике целесообразно придерживаться следующей типизации видов разметки:
1. Классификация (общий анализ) – отнесение результатов лучевого исследования к одной из категорий, например, «норма» или «наличие целевой патологии».
2. Детекция или локализация – кластерная разметка, ограничение целевых областей изображения прямоугольниками или иными геометрическими фигурами.
3. Сегментация – выделение целевых областей изображения попиксельной маской.
В целом процесс разметки разделяется на два этапа70:
1. Первичная разметка. В ее процессе выполняются отметка и характеризация всех целевых структур в подготовленном НД с формированием структурированной аннотации, шаблон которой определен техническим заданием на набор данных.
Предварительная разметка выполняется врачами, которые соответствуют следующим критериям71:
– компетентность в области конкретных типов данных: изображения, текстовые данные или сигнальные (ЭКГ, ЭЭГ, спирометрия и т.д.), количественные данные (ЧСС, артериальное давление, спирометрия и др.), бинарные данные (например, да/нет);
– наличие знаний и навыков, соответствующих уровню сложности планируемой разметки и/или аннотирования: первичная разметка (сегментирование) или экспертная; детализация на уровне классов или подклассов, установление связи с метаданными, определение вероятных исходов (прогнозирования);
– успешное прохождение предварительного тестирования.
1. Экспертная валидация. Выполняется с привлечением экспертной группы врачей-специалистов в целях проверки и корректировки результатов первичной разметки. Выделяют две группы экспертных оценок:
1) индивидуальные оценки, основанные на использовании мнения отдельных экспертов, независимых друг от друга;
2) коллективные оценки, основанные на использовании коллективного мнения экспертов.
Основные этапы обработки экспертных оценок72:
– определение компетенции экспертов;
– определение обобщенной оценки;
– построение обобщенной ранжировки объектов в случае нескольких оцениваемых объектов или альтернатив;
– определение зависимостей между ранжировками;
– оценка согласованности мнений экспертов (при отсутствии значимой согласованности экспертов необходимо выявить причины несогласованности (наличие групп) и признать отсутствие согласованного мнения (ничтожные результаты));
– оценка ошибки исследования;
– построение модели свойств объекта (объектов) на основе ответов экспертов (для аналитической экспертизы);
– подготовка отчета (с указанием цели исследования, состава экспертов, полученной оценки и анализа результатов).
В экспертную группу должны входить врачи-специалисты с большим опытом работы с определенным типом наборов данных (видом медицинской информации). Как правило, предъявляют требование к опыту работы от трех лет. Эксперты должны обладать опытом в областях, соответствующих решаемым задачам. При подборе экспертов следует учитывать наличие конфликтов интересов, которые могут стать существенным препятствием для получения объективного суждения73.
В рамках Московского эксперимента процесс разметки изначально происходил следующим образом: врач-разметчик просматривал исследование в ЕРИС ЕМИАС и вносил данные в таблицу разметки, используя внешний редактор электронных таблиц. Однако с ростом количества размечаемых показателей этот процесс стал крайне трудозатратным и часто приводил к появлению ошибок ввода. Кроме того, каждое исследование просматривалось 2-мя врачами-разметчиками и валидировались экспертом, что также довольно неудобно при работе с обычными электронными таблицами. Эта проблема решена на «Платформе подготовки наборов данных» путем объединения DICOM-просмотровщика, формы разметки и назначением ролей врача и эксперта (рисунок 2.13).
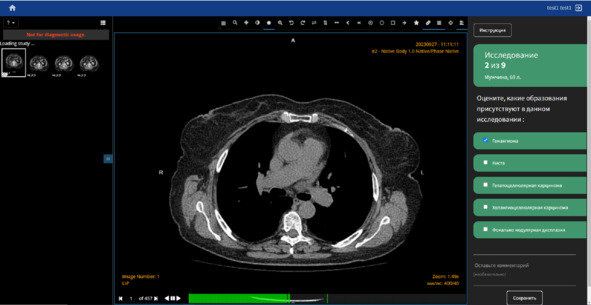
Рисунок 2.13 – Модуль разметки: слева – DICOM-просмотровщик, справа – форма для разметки
Форма разметки находится в одном окне с просмотровщиком, автоматически переключается при переходе к новому исследованию и имеет гибкие возможности настройки полей и ролей, что способствует снижению ошибок ввода данных и ускорению процесса разметки. Форма создается с помощью специального конструктора (рисунок 2.14), где возможны настройка связей между полями, вид полей (поле для ввода, поля с множественным и единичным выбором), формат данных. Простейший пример так называемой динамической формы – это настройка связи при наличии брака: при выставлении галочки в поле «Брак» дальнейшая часть формы не отображается. Это также дает возможность избежать ряда ошибок и повышает качество создаваемого набора данных. Кроме того, назначение роли «Эксперт» позволяет визуализировать форму с данными разметки от врачей-разметчиков для обеспечения удобной валидации.
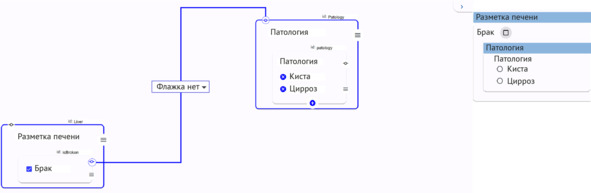
Рисунок 2.14 – Конструктор форм
Необходимо отметить, что вопросу качества НД уделено максимально внимание, и все создаваемые инструменты этому способствуют. Так был разработан модуль контроля качества для результатов рентгенографии органов грудной клетки. В автоматическом режиме он анализирует DICOM-исследования на предмет нарушений качества проведения исследований (обрезка, ротация, нарушения экспозиции дозы) и заполнения DICOM-тегов74.
Структурирование данных. Включает в себя проверку таблиц разметки, балансировку классов и формирование итоговых таблиц разметки. Изначально этот этап проводился аналитиком в полуавтоматическом режиме, однако теперь на «Платформе подготовки наборов данных» основную часть этого этапа, а именно проверку таблиц разметки и формирование итоговых таблиц, «взял на себя» модуль разметки. Теперь правильно сформированная форма разметки делает возможным в автоматическом режиме проводить проверку непосредственно в процессе разметки, не позволяя вводить некорректную информацию.
Формирование файлов с DICOM-изображениями и с разметкой производилось вручную. В таблицах разметки указывалась краткая информация о ее содержимом (название, целевая патология, авторы, год создания, назначение и т.д.). На «Платформе подготовки наборов данных» реализован инструмент, позволяющий формировать и структурировать файлы для тестирований в Московском эксперименте в полуавтоматическом режиме (рисунок 2.15).
Детальная информация об инструментах разметки и их сравнение представлены далее.
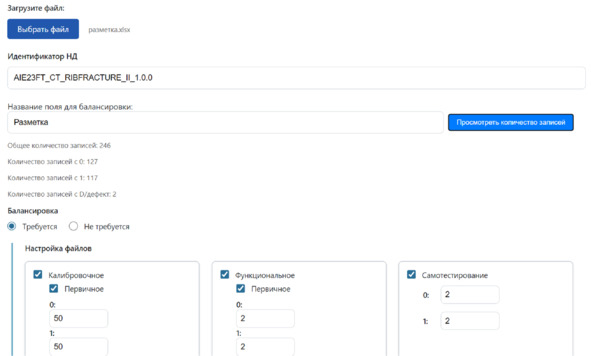
Рисунок 2.15 – Структурирование файла: при введении поля для балансировки инструмент отображает количество размеченных исследований и структурирует их в файлы с заданным названием и составом, а также формирует вкладку с кратким содержимым файла
Регистрация и публикация. В завершение всех процессов непосредственно по формированию набора данных необходимо обозначить этот момент, а также подготовить сопровождающий readme-файл, который содержит основную информацию о НД и будет храниться вместе с ним. Изначально для readme-файла был разработан специальный шаблон, куда вносилась нужная информация. Однако с учетом того, что readme хранится на двух языках (русском и английском) и в двух форматах (PDF и md), его заполнение занимало много времени. Поэтому был разработан специальный программный код, который формировал документ путем извлечения данных из реестра. Код включен в «Платформу подготовки наборов данных» в виде генератора readme на странице НД (рисунок 2.10б). Он позволяет автоматически сформировать документ на двух языках и визуализирует его в корректируемом виде: можно исправить и сохранить все параметры, которые не соответствуют стандартному шаблону. Этап регистрации заключается во внесении всей информации о наборе в реестр и фиксации статуса «Готов».
Публикация НД осуществляется на закрытых или открытых ресурсах. Закрытые наборы данных НПКЦ ДиТ ДЗМ доступны только сотрудникам, задействованным в Московском эксперименте и научных исследованиях; открытые – опубликованы в библиотеке https://mosmed.ai/datasets/ и доступны всем желающим. Данная библиотека разработана в рамках нормативно-правового регулирования общественных отношений, связанных с развитием и использованием технологий искусственного интеллекта, и обеспечения безопасности применения таких технологий, предусмотренных Национальной стратегией развития искусственного интеллекта до 2030 года. В частности, речь идет об установлении правил создания и предоставления наборов данных, основой которых являются обезличенные медицинские данные, а также создании механизмов их распространения, объединения и обмена для выполнения научных исследований в области искусственного интеллекта75. Кроме того, распространение наборов данных соответствует принципу бережливости Национальной стратегии и принципам FAIR (от англ. Findable, Accessible, Interoperable, Reusable – доступные для поиска, доступные к использованию, совместимые, пригодные для повторного использования научные данные)76.
Библиотека mosmed.ai содержит каталог НД с различными фильтрами для удобного поиска (рисунок 2.16).
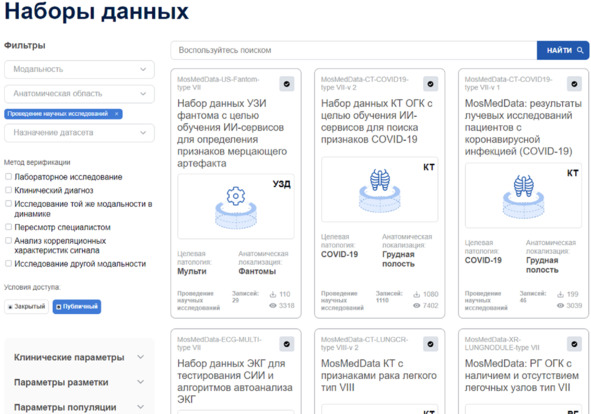
Рисунок 2.16 – Каталог наборов данных библиотеки mosmed.ai
Карточка НД также имеет структурированный вид для оптимального поиска исследователем или разработчиком необходимых параметров (рисунок 2.17). При скачивании загружается архив, содержащий медицинские изображения, файл (ы) разметки и readme на двух языках.
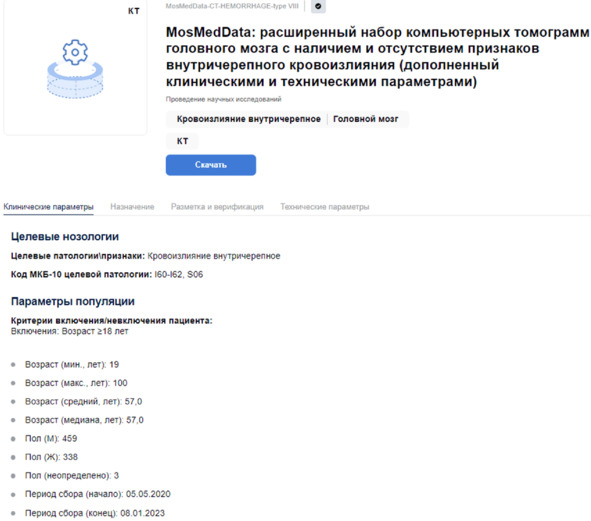
Рисунок 2.17 – Фрагмент карточки набора данных библиотеки mosmed.ai
Библиотека содержит различные категории НД, однако наиболее широко в ней представлены «селф-тесты диагностические», то есть наборы данных для самотестирования ИИ-сервисов. Они активно используются в Московском эксперименте, содержат небольшое количество исследований (от 4 до 10) и предназначены для предварительного самостоятельного тестирования разработчиками своих продуктов. Это позволяет выявить и устранить ошибки до момента подачи заявки на участие в Московском эксперименте. Также для самостоятельной оценки функционирования СИИ на различных диагностических устройствах в библиотеке имеются «селф-тесты технические». Научные исследования представлены в библиотеке несколькими наборами данных разных модальностей (КТ, РГ, УЗИ, ММГ, ЭКГ), в частности, имеются 2 набора данных, обогащенных клинической информацией77.
Использование. После размещения НД в хранилище и внесении в реестр можно приступать к процессу использования. При этом информацию об использовании также необходимо фиксировать, особенно с учетом большого количества НД, создаваемых в НПКЦ ДиТ ДЗМ, а также их всестороннего использования в соответствии с принципом разумной бережливости (принцип повторного использования). Информация об использовании также хранится в реестре в одноименном разделе. В соответствии с задачами были выделены следующие разделы:
– ссылка на хранение НД;
– актуальная версия для Московского эксперимента;
– научное сотрудничество;
– научная статья;
– доступ для разработчиков;
– ссылка для цитирования;
– статус регистрации РИД.
Кроме того, ввиду проведения большого количества тестирований эта информация также фиксируется в специальном журнале на платформе оценки диагностической точности. Ведение такого рода журналов и реестра позволяет отслеживать процессы использования, возвращаться к данным и протоколам при возникновении вопросов, избегать публикации калибровочных наборов данных в публичном пространстве и, наоборот, открывать доступ к НД, которые уже не используются в тестированиях. Это позволяет оценивать и повышать результативность применения наборов данных (следовательно, ресурсов на их создание) и принимать управленческие решения.
Контроль качества при подготовке набора данных (по ГОСТ Р 59921.5—202278).
Под качеством набора данных понимается его структурированность, однородность, репрезентативность, сбалансированность по классам, отсутствие выпадающих значений, наличие разметки, которая соответствует поставленной задаче, наличие описания модели данных и документации79.
В процессе разработки НД целесообразно применять систему менеджмента качества – организационную структуру, функции, процедуры, процессы и ресурсы, необходимые для скоординированной деятельности по руководству и управлению организацией применительно к качеству. Формирование НД должно быть спланировано и подвержено мониторингу и управлению для обеспечения соответствия качества.
Работой группы может руководить сотрудник, назначенный ответственным, который не принимает участие в разметке и/или аннотировании, но будет регулировать срочность, очередность и объем работы между экспертами. Обязанностью данного ответственного также является формирование рабочей группы для обеспечения объективности и достоверности результата.
Должны быть применены методы оценки качества набора данных, по которому будет производиться разметка:
– проверка отсутствия пропусков элементов в наборе данных;
– проверка отсутствия некорректных элементов для решения поставленных задач;
– проверка качества элементов набора данных рекомендованным критериям профессионального медицинского сообщества.
Должны быть подготовлены и внедрены стандартные процедуры применения наборов данных в рамках системы менеджмента качества. Необходимо указать и требования по организации доступа к наборам данных, в том числе реестр лиц, которые получили к нему доступ.
После создания и регистрации набора данных может возникнуть необходимость внести изменения – например, в результате обнаружения ошибок или добавления новых данных. При внесении любых корректировок необходимо документировать изменение версии НД. Эта документация должна быть приложена к набору данных.
2.2.4. Инструменты разметки и работы с данными
В процессе создания сотен наборов данных для решения задач Московского эксперимента, клинических испытаний, собственной разработки ИИ-сервисов и научных задач в НПКЦ ДиТ ДЗМ накоплен практический опыт, позволивший сформировать требования к базовой функциональности программного обеспечения (ПО) для разметки результатов лучевых исследований80:
1. Общие характеристики:
– возможность установки ПО на локальных серверах;
– возможность распределенной работы нескольких экспертов над одним набором данных;
– возможность формирования задач экспертам, отслеживания статусов готовности;