


Полная версия
Искусственный интеллект в лучевой диагностике: Per Aspera Ad Astra
2) характеристику популяции (возрастно-половые показатели, этнический состав, регионы проживания и т.д.); сведения о деидентификации; сведения о медицинских организациях, послуживших источниками для формирования базы данных; сведения о факторах риска;
3) характеристику диагностических исследований: анатомическая область (и), модальность, проекции, типы медицинских изделий – диагностических приборов, виды и характеристики протоколов исследования;
4) целевую патологию согласно Международной классификации болезней 10 версии (либо наименование феноменов в соответствии с клиническими рекомендациями, национальными стандартами, рекомендациями профильных ассоциаций врачей-специалистов);
5) общее количество клинических случаев, исследований, изображений, документов и их распределение по диагностическим группам;
6) соотношение случаев «норма»/«патология» (случаи «патология» могут быть разделены на несколько подклассов);
7) сведения о верификации (патогистологическом или ином окончательном диагнозе);
8) методологию разметки.
На международном уровне сформирован рекомендательный список метаданных для верифицированного набора медицинских изображений46:
1. Тип изображения: вид исследования (компьютерная томография, рентгеновское исследование и т.п.); разрешение; общее число изображений и по сериям.
2. Число исследований.
3. Источники исследований: оборудование; типы оборудования; медицинская организация.
4. Параметры сканирования изображений.
5. Параметры хранения изображений: формат данных; уровень и тип сжатия данных.
6. Аннотация (разметка): тип; что и как описано; привлеченная экспертная группа.
7. Контекст.
8. Как определена истинная разметка и промаркирована.
9. Связанные данные: демографические; клинические; лабораторные; геномные; временные; принимаемые медикаментозные средства; другие.
10. Временной диапазон сбора изображений: дата и время исследования.
11. Использование данных: какое программное обеспечение использовать для просмотра данных.
12. Кому принадлежат данные.
13. Кто ответственен за данные.
14. Допустимое использование.
15. Назначение набора данных.
16. Информация об одобрении комитета по этике.
17. Информация о деидентификации набора данных.
18. Информация о проведенном контроле качества набора данных.
19. Параметры доступа: доступность; цена и лицензионные соглашения.
20. Распределение случаев (если применимо): процент «норма/патология» (код МКБ-10); данные патологии: число исследований с каждой патологией.
Уже на первых этапах Московского эксперимента сформирован общетеоретический подход к классификации, состоящий в выделении трех видов наборов данных, определяемых процессом выполнения разметки (рисунок 2.2). Классификация цитируется по ГОСТ Р 59921.5—202247:
1. Набор данных по ретроспективной разметке. Такая разметка подразумевает сбор данных в соответствии с указанными метаданными, перечень которых выбирают в соответствии с поставленной целью формирования НД. Она выполняется путем выгрузки данных из медицинской информационной системы. Ретроспективная разметка не предполагает выполнение манипуляций или какой-либо обработки элементов. Для каждого элемента НД лишь устанавливают соответствие с медицинской информацией (диагноз, результаты лабораторного тестирования и т.п.). Такой способ разметки не требует участия врача, он может быть реализован на основе технического задания техническим специалистом, который имеет опыт работы с НД.
2. Набор данных по проспективной разметке. Такая разметка подразумевает сбор данных в соответствии с поставленной целью формирования НД, а также проведение дополнительных манипуляций с элементами (например, путем постановки метки начала и окончания события, меток обнаружения признаков, обозначений патологий и т.п.). Такую разметку проводят с участием обученного медицинского персонала путем ручного аннотирования содержания данных или их частей, которое может быть выполнено в графической или текстовой форме, либо в их комбинации.
3. Верифицированный набор данных. Разметка в таком случае подразумевает включение верифицированной (то есть подтвержденной объективными свидетельствами) медицинской информации. Такой НД формируют путем дополнения результатов проспективной разметки данными из медицинской документации. Для верификации можно применять метод «золотого стандарта» для целевой патологии, информацию об окончательном и/или патологоанатомическом диагнозе, повторное исследование пациента через определенное время, результаты патогистологических, иммунологических исследований и др. Отдельным методом верификации служит слепой анализ набора данных экспертами с достижением заданного уровня согласованности их решений.
Сформированы следующие критерии отнесения НД к верифицированному:
– данные получены из реальной практики (не допускается получение синтезированных данных);
– данные получены в «сыром виде» – без применения фильтров и математических средств постобработки;
– структура НД соответствует поставленной цели его формирования (обучение, тестирование, клинические испытания и проч.);
– количество наблюдений (исследований) достаточно для достижения статистической значимости результата;
– разметка и/или аннотирование проведены экспертной группой, соответствующей определенным критериям (см. далее);
– разметка и/или аннотирование проведены с использованием тезауруса (кодированной библиотеки типовых формулировок, соответствующих клиническим рекомендациям, национальным стандартам, рекомендациям ассоциаций специалистов в данной области).
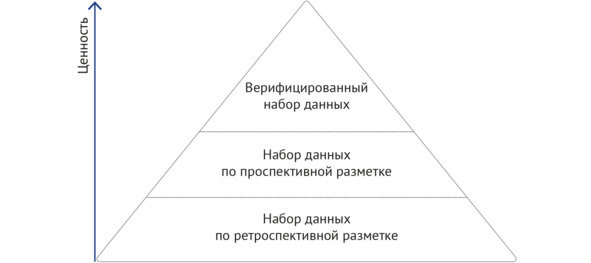
Рисунок 2.2 – Классификация видов разметки по степени общей ценности
Приведенный подход включен в национальный стандарт ГОСТ Р 59921.5—2022 как основополагающий48. В дальнейшем, по мере накопления практического опыта и научных знаний, были разработаны более специализированные классификации наборов данных лучевой диагностики по диагностической ценности (рисунок 2.3) и по целевому назначению (таблица 2.1). Также в дальнейшем были классифицированы методы верификации (рисунок 2.4).
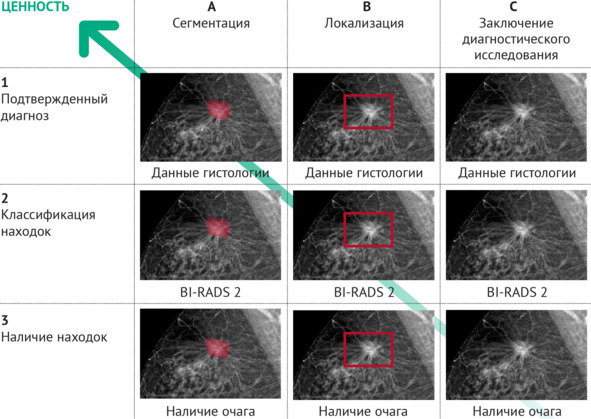
Рисунок 2.3 – Классификация видов разметки данных по диагностической ценности на примере результатов маммографии
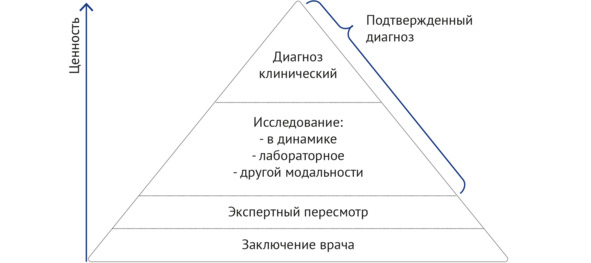
Рисунок 2.4 ‒ Методы верификации данных
Классификация по диагностической ценности предполагает разделение наборов данных на три вида (1, 2, 3) и три класса (A, B, C)49. Вид подразумевает типовой способ верификации:. Бинарная оценка факта наличия или отсутствия целевой патологии.
2. Классификация целевой патологии в соответствии с клиническими рекомендациями, стандартизованными клинико-рентгенологическими классификациями, шкалами, системами описания.
3. Наличие данных о верификации природы целевой патологии.
Класс подразумевает типовой способ отображения патологической находки в результатах лучевого исследования – информация о наличии/отсутствии целевой патологии:
1. Содержится в метаданных, сопроводительных файлах (таблицах), отсутствует на изображении.
2. Представлена в виде координат. Может помещаться в метаданные (аннотация, сводный табличный сопроводительный файл) и/или присутствовать на изображении в виде отметки области расположения простой геометрической фигурой.
3. Представлена на изображении в виде пиксельной маски (оконтуренной области изображения), дополнительно может содержаться в метаданных (в аннотации).
Классификация может применяться в отношении наборов данных для любых задач лучевой диагностики. Она не зависит от типов (модальности) диагностических данных, но вместе с тем четко отображает взаимосвязь между собой:
– объемов и качества исходных данных;
– трудозатрат на подготовку;
– методик разметки и работы с первичными данными;
– диагностической ценности в контексте той или иной медицинской задачи.
Классификация по цели использования с появлением новых задач претерпела значительные изменения и в итоговом варианте содержит 10 типов НД (таблица 2.1).
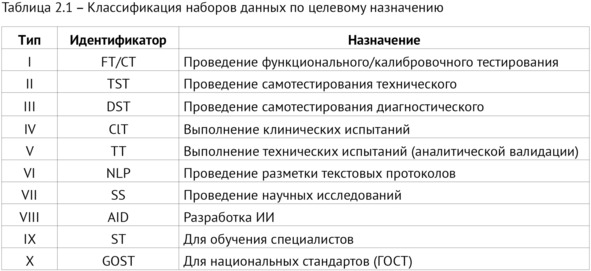
Исторически самым первым и самым разнообразным типом являются наборы данных для научных исследований (VII). Опыт их создания послужил основой для всех остальных типов и для формирования методологии, в процессе которой определился VI тип. На первых этапах исследования НД собирались исключительно вручную на потоке (просматривались все исследования целевой модальности на предмет наличия патологии), однако централизованное хранение всех лучевых исследований в ЕРИС ЕМИАС, включая текстовые протоколы описания и заключения, позволили в дальнейшем автоматизировать этот процесс. Было положено начало направлению работы с медицинскими текстами, которое потребовало создания специальных наборов данных (VI). Большинство наборов данных принадлежит к I типу (минимум 4 НД на каждое направление), так как предназначены для валидационных тестирований ИИ-сервисов в Московском эксперименте, а также к III и IV типу – для самотестирования (самостоятельной проверки корректности диагностической оценки ИИ-сервисами и их работоспособности на разных диагностических устройствах). Отдельные типы (IV и V) НД созданы для клинических испытаний. На более поздних этапах при разработке собственных ИИ-сервисов потребовались наборы данных для обучения (VIII). Накопленный научный и практический опыт позволил разрабатывать национальные стандарты, в рамках которых также требовались эталонные НД (тип X). Деятельность ГБУЗ «НПКЦ ДиТ ДЗМ» включает самые разные направления, например, образовательную работу, в рамках которой создаются НД для обучения и тестирования врачей (тип IX). По-видимому, список типов наборов данных в дальнейшем также будет претерпевать изменения с еще большим расширением возможностей и появлением новых задач.
Также опыт показал, что количество исследований (единиц НД) не определяется типом набора. Расчет объема выборки является нетривиальной задачей и зависит от множества факторов (подробнее см. 2.3.1).
Одной из первых задач, которую решали ИИ-сервисы в Московском эксперименте, стало определение на результатах лучевого исследования наличия признаков, характерных для целевой патологии. В рамках данной задачи валидационные НД (те, которые использовались при тестировании ИИ-сервисов) преимущественно относились к С-классу разметки (рисунок 2.3); при разметке в этом случае прежде всего требовалось отнести исследование к верному классу (как правило, с наличием/отсутствием патологии, реже – ее классификация по степени тяжести). В дальнейшем, в ходе анализа результатов работы ИИ-сервисов, возникали новые задачи, требующие более сложных НД. Так, отмечалась некорректная работа ИИ-сервисов в исследованиях с артефактами, дефектами укладки или некорректно заполненной метаинформацией. В результате были созданы соответствующие НД и впервые разработан ИИ-сервис для определения их качества50.
С развитием Московского эксперимента расширялись требования к результатам работы ИИ-сервисов, в ходе накопления практического опыта и при проведении научных исследований возникали новые задачи и стратегии применения СИИ в медицине. Так, появилось новое направление – автоматизация рутинных измерений (морфометрия) и соответствующие ему наборы данных. В дальнейшем обозначилась потребность в динамических НД, а также в наборах изображений, обогащенных клинической информацией. Поэтому возникла новая классификация наборов данных по решаемой задаче:
1. Диагностические (оценка качественных признаков: наличие/отсутствие, степень выраженности, классификация признака).
2. Морфометрические (оценка количественных признаков: измерение линейных размеров, площадей, углов, объемов, коэффициентов).
3. Для контроля качества (с артефактами и дефектами укладки, ошибками DICOM-тегов и т.д.).
4. Динамические (оценка исследований в динамике, прогностические задачи).
5. Обогащенные клинической информацией (НД с дополнительной клинической информацией для разработки СППВР и прогностических задач).
6. Комбинированные (сочетающие в себе вышеперечисленные данные).
Отдельное внимание заслуживают синтетические НД (см. параграф 2.2.5). Такое обилие классификаций обусловлено большим количеством наборов данных, созданных в ГБУЗ «НПКЦ ДиТ ДЗМ» за 5 лет (более 600!) и разнообразием решаемых задач, в том числе перспективных. Все разработанные принципы классификации и организации метаданных реализованы в виде реестра НД.
Реестр наборов данных – это перечень всех созданных в учреждении НД, содержащий структурированную информацию о них. Потребность в таком инструменте возникла с первых дней Московского эксперимента, в частности, для выбора НД при проведении функциональных и калибровочных тестирований. Первоначально это был простой список названий НД, однако с увеличением количества направлений возникла потребность в дополнении списка различными параметрами, а также в унификации названий и создании идентификаторов, кодирующих базовую метаинформацию. Примеры структуры названия и идентификатора приведены на рисунках 2.5 и 2.6.

Рисунок 2.5 – Структура и пример названия набора данных
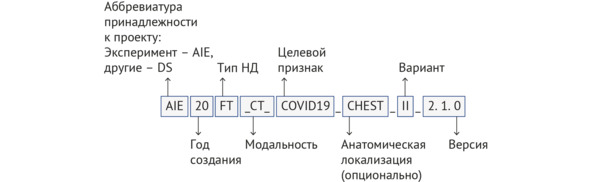
Рисунок 2.6 – Структура и пример идентификатора набора данных
К сожалению, с появлением новых задач, разработанные правила наименования не всегда позволяют создавать релевантные названия, однако при этом структура названия гибкая и может меняться (дополняться) в зависимости от требуемых для внесения параметров. Полная форма названия чаще используется для регистрации результатов интеллектуальной деятельности или упоминания НД в публикациях, документах и в устной речи. Идентификатор необходим для наименования файла, так как длина названия ограничена, а также в нем зашифрованы дополнительные данные, необходимые в контексте выполняемых задач. Например, на рисунке 2.6 идентификатор читается как: «Набор данных для Эксперимента, созданный в 2020 году, для функционального тестирования по направлению ″компьютерная томография органов грудной клетки″ с наличием и отсутствием признаков коронавирусной инфекции COVID-19, вариант 2, версия 2.1.0». Вариативность создана с целью тестирования ИИ-сервисов на разных НД с одинаковой спецификацией, а версионность разрешает отслеживать изменения, вносимые в набор. Идентификатор позволяет однозначно определить НД, который отправлялся ИИ-сервису для тестирования, для дальнейшей корректной (в т.ч. автоматизированной) оценки результатов обработки и обеспечения прозрачности процесса тестирования.
Реестр наборов данных как полноценный инструмент был сформирован в 2022 году и содержал в себе порядка 100 полей. Их количество и названия незначительно колебались в процессе совершенствования инструмента, однако принципы организации оставались общими:
1. НД имеют унифицированные названия и идентификаторы.
2. Метаинформация структурирована и классифицирована согласно российским и международным медицинским справочникам (ФСИДИ51, Международная классификация болезней 10-й версии, справочник ЕРИС ЕМИАС, справочник анатомических локализаций, RadLex52, LOINC53), а также разработанным классификациям (классы разметки, методы верификации, характер и уровень разметки, источник данных, направление Московского эксперимента и т.д.).
3. Реестр имеет разделы, синхронизированные с жизненным циклом набора данных. Его заполнение происходит на каждом этапе, включая использование, и продолжается до момента утилизации НД (если такой наступает).
4. Описательная информация (карточка НД) составлена с учетом как собственного опыта использования метаинформации, так и чек-листов описания НД и СИИ в научных публикациях в мировых рецензируемых изданиях54. Она организована по разделам: клинические, популяционные, технические параметры, назначение, параметры разметки.
Благодаря всему перечисленному реестр выполняет следующие функции:
1. Обеспечение процессов управления: контроль сроков и порядка выполнения работ по созданию НД, оценка результативности использования, оптимизация ресурсов (повторное использование данных).
2. Доступ к данным: единое место хранения всей информации, включая ссылки на хранение, указание ответственных за НД, удобное формирование библиотеки.
3. Контроль качества данных: проверка параметров НД на соответствие техническому заданию, базовым диагностическим требованиям, отслеживание внесения изменений (смена версионности).
4. Автоматизация процессов создания НД: генератор readme-файла, автоматическая проверка данных на соответствие техническому заданию.
Реестр представляет собой практическое внедрение научно обоснованного стандарта набора данных для лучевой диагностики.
2.2.3. Жизненный цикл и алгоритм создания набора данных
Важнейшим результатом, полученным в ходе создания и использования наборов данных, стала описанная методология, включающая в себя жизненный цикл НД (рисунок 2.7) и непосредственно алгоритм его создания (рисунок 2.8).
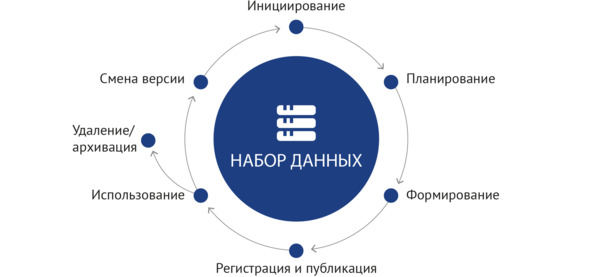
Рисунок 2.7 – Жизненный цикл набора данных
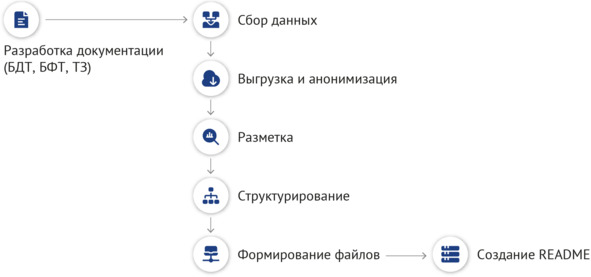
Рисунок 2.8 – Алгоритм создания набора данных
Сформированная методология позволяет регламентировать все процессы, связанные с наборами данных, описывает все действия, которые необходимо совершить разработчику или исследователю, начиная от идеи/потребности создания НД, заканчивая его использованием, сменой версии и утилизацией. Это позволяет наладить четкие процессы выполнения работ, а также не упустить важные аспекты, в т.ч. связанные с безопасностью данных и регламентированные законодательством, что в свою очередь минимизирует вероятность возникновения ошибок, повышает качество и снижает сроки создания наборов.
Кроме того, сформулированная этапность всех действий позволила автоматизировать эти процессы. На первых этапах Московского эксперимента, когда методика только начинала формироваться, большая часть работ выполнялась вручную. В дальнейшем внедрялась автоматизация отдельных процессов: как правило, это были разрозненные программы, не имеющие интерфейса. Для их использования требовалась помощь разработчика и/или научного сотрудника, который адаптировал код под конкретную задачу и запускал процесс обработки данных. Для оформления сопроводительной документации также разрабатывались специальные шаблоны для заполнения. Объединить весь накопленный опыт удалось в оригинальном программном продукте «Платформа подготовки наборов данных»55. Он имеет удобный интерфейс и модульную структуру, при этом модули можно использовать последовательно, согласно алгоритму создания НД, или изолированно. Далее описаны этапы жизненного цикла и алгоритма создания НД от первых шагов до единой платформы подготовки.
Подготовка набора данных в общем виде состоит из набора процедур, выполнение которых позволяет достигнуть цели обучения и тестирования системы искусственного интеллекта (СИИ) с обеспечением качества набора данных56.
Инициирование. Первый этап жизненного цикла наступает с момента появления идеи создания конкретного НД и определения его цели. Формирование цели НД включает оценку того, является ли доступ к данным или другая деятельность по их обработке допустимыми57:
– какие данные допустимо собирать;
– как их следует использовать (применительно к каким задачам);
– кому их следует раскрывать (доступ третьим лицам);
– в течение какого времени они должны быть доступны.
Цели формирования НД разнообразны, наиболее типичны следующие58:
– разработка СИИ, включающая этап обучения алгоритма искусственного интеллекта и выполнение внутреннего тестирования;
– научная независимая оценка СИИ;
– выполнение аналитической или клинической валидации СИИ, в том числе в рамках клинических испытаний.
Как оформленный этап инициирования появился при внедрении в работу реестра наборов данных? До этого момента, информация о них хранилась разрозненно и не структурированно, иногда не фиксировалась вовсе. С появлением реестра возникла возможность вносить информацию о НД еще на этапе идеи, что позволило эти идеи организовать, отслеживать и развивать. На платформе для инициирования необходимо заполнить ключевую информацию (предварительное название, Ф. И. О. ответственного, ключевая информация в свободной форме), после чего НД появится в реестре и будет доступен для дальнейших манипуляций (рисунок 2.9).
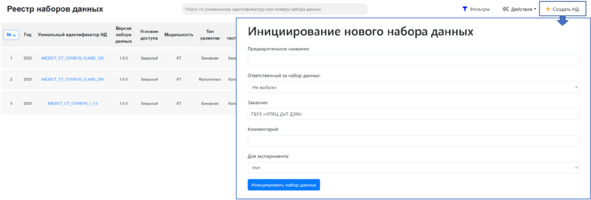
Рисунок 2.9 – Инициирование нового НД на «Платформе подготовки наборов данных»
Планирование. Этап предполагает детальную проработку сформулированной ранее идеи.
На этом этапе осуществляется постановка задачи подготовки НД, включающая определение предметной области и выбор методов обработки. Задача должна быть определена проблемой, на решение которой направлено создание СИИ, ее классом, задачей или целью проведения тестирования59.
Исходя из задачи определяются:
1. Размер набора данных (размер выборки для его формирования). Подробнее этот вопрос рассмотрен в подпараграфе 2.3.1.
2. Баланс данных и распределение классов. Сбалансированный набор данных должен содержать одинаковое количество примеров различных категорий (классов) объектов интереса, включая примеры нормы. При условии бинарной классификации это может соответствовать распределению 50/50 для случаев «патология»/«норма».
Вся информация о будущем НД фиксируется в техническом задании (ТЗ), которое составляется, в том числе с учетом базовых диагностических и функциональных требований Московского эксперимента.
Изначально ТЗ формулировалось в свободной форме, со временем был разработан структурированный шаблон и, наконец, в составе платформы ТЗ реализовано в виде структурированной формы для заполнения. Для удобства часть полей предварительно заполнена, подгружены используемые справочники, настроены связи между ними, реализовано автоматическое формирование названия НД согласно описанным выше правилам, имеются справочные вкладки, поясняющие, какую информацию необходимо внести. Это позволяет тщательно продумать все аспекты будущего НД и, возможно, обратить внимание исследователя на те моменты, которые на первый взгляд могли показаться неважными. Фактически платформа осуществляет обучение процессу создания НД. На основании введенной информации генерируется таблица разметки, если это необходимо.
После утверждения ТЗ вся информация выносится в карточку НД, где она структурирована по разделам: клинические, популяционные, технические параметры, назначение, параметры разметки, ответственные (рисунок 2.10г). В дальнейшем на этапах регистрации и использования эта информация дополняется.
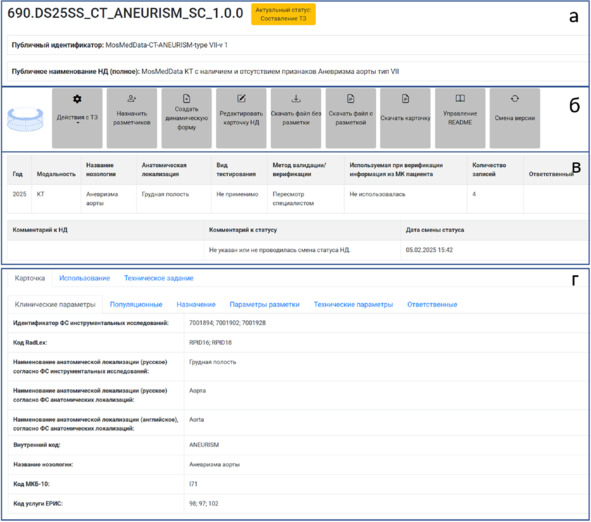
Рисунок 2.10 – Страница набора данных: а – идентификаторы, статус готовности; б – инструменты работы с НД (инструмент работы с ТЗ, инструмент назначения разметчиков, конструктор динамической формы, редактор карточки, ссылки на хранение таблиц с разметкой и без, генератор readme, смена версионности); в – краткая сводная информация о НД и его карточка (полная структурированная информация о наборе)
Формирование. Сбор данных. Первым шагом является непосредственно работа с данными, которая начинается с их поиска и отбора.
Здесь возможны два подхода – для НД представление медицинских данных (феноменов, синдромов, заболеваний, исходов) происходит60:
1) с отражением максимальной вариативности (то есть и частые, и редкие случаи представлены в одинаковом объеме);
2) согласно их частоте встречаемости, предтестовой вероятности, заболеваемости, распространенности в популяции.
Первый подход должен применяться при подготовке НД аналитической валидации СИИ, второй – для клинической (см. подпараграф 2.9.2).