


Полная версия
Искусственный интеллект в лучевой диагностике: Per Aspera Ad Astra
В. Я. Пропп
2.1. Внедрение систем искусственного интеллекта: принципы, этапы, стандартизация требований к результатам работы
Национальная стратегия развития искусственного интеллекта на период до 2030 года27 предусматривает следующее определение: искусственный интеллект – комплекс технологических решений, позволяющий имитировать когнитивные функции человека (включая поиск решений без заранее заданного алгоритма) и получать при выполнении конкретных задач результаты, сопоставимые с результатами интеллектуальной деятельности человека или превосходящие их. Комплекс технологических решений включает в себя информационно-коммуникационную инфраструктуру, программное обеспечение (в том числе то, в котором используются методы машинного обучения), процессы и сервисы по обработке данных и поиску решений.
В здравоохранении «искусственный интеллект» целесообразно рассматривать как очередное поколение инструментов автоматизации трудовых операций и производственных процессов. Только такой материалистический взгляд позволяет трезво и рационально подойти к внедрению и применению соответствующих технологий. В действительности, автоматизация в отдельных медицинских отраслях чрезвычайно высока и давно стала рутиной. Машинный анализ данных с оценкой физиологических и морфологических показателей, определением патологических проявлений уже на протяжении десятилетий является составной частью многих медицинских приборов. Самый «древний» пример – это электрокардиография, более «современный» – лабораторная диагностика.
Безусловно, актуальные технологии («компьютерное зрение, обработка естественного языка, распознавание и синтез речи, интеллектуальная поддержка принятия решений и перспективные методы искусственного интеллекта»28) открывают принципиально новые возможности, по сравнению с уже реализованными решениями. Однако принципы их изучения и внедрения в практическое здравоохранение остаются прежними: системный научный подход, Noli Nocere, методология доказательной медицины.
Искусственный интеллект – это инструменты автоматизации трудовых операций и производственных процессов в здравоохранении, применение которых осуществляется в определенном клиническом контексте, на принципах материализма, доказательности, эффективности, осознанности, объяснимости, прозрачности.
Клинический контекст – единый дискретный комплекс информации о цели, задачах, конкретных процессах и операциях, нозологиях, видах биомедицинских и иных данных, функциях медицинского персонала и технических устройств, связанных с организацией и оказанием медицинской помощи.
Принцип материализма – отказ от гуманизации технологий искусственного интеллекта в здравоохранении, отказ от стереотипов и предубеждений, связанных с отождествлением разума человека и математического аппарата электронно-вычислительной машины.
Принцип доказательности – разработка, апробация, внедрение и применение технологий искусственного интеллекта осуществляются только на научной основе, с использованием подходов и методик доказательной медицины. Носит сквозной характер, так как все элементы и этапы проектирования, разработки, применения, оценки эффектов и проч. технологий ИИ в здравоохранении базируются исключительно на научном подходе – хайпу нет места в медицине.
Принцип эффективности – применение технологий искусственного интеллекта для достижения конкретной измеримой цели; научное обоснование результативности такого применения.
Принцип осознанности – адаптация применения технологий искусственного интеллекта к конкретному клиническому контексту, понимание возможностей и ограничений таких технологий, научное формирование показаний и противопоказаний к их применению.
Принцип объяснимости – функциональная возможность программного обеспечения на основе ИИ объяснить человеку свое решение, процесс его достижения и степень уверенности в нем.
Принцип прозрачности – недискриминационный доступ пользователей продуктов, которые созданы с использованием технологий искусственного интеллекта, к информации о применяемых в этих продуктах алгоритмах работы искусственного интеллекта.
Отдельно выводить принцип безопасности и качества не имеет смысла, так как любое медицинское изделие или применяемое в медицине средство должно ему соответствовать. Каких-либо особенностей и исключения для ИИ здесь нет. В этом контексте попытки этически ограничить «автономность» технологий искусственного интеллекта выглядят довольно натянуто, так как, например, при объективном рассмотрении довольно трудно проследить грани автономности и неавтономности при проведении клинико-лабораторных исследований в современной автоматизированной лаборатории.
Клинический контекст представляет собой комплекс специфической базовой информации, необходимой для эффективного применения искусственного интеллекта в практическом здравоохранении на основе перечисленных принципов.
Другим критичным аспектом является адекватное, обоснованное целеполагание в соответствии с принципами осознанности и эффективности.
В период подготовки Московского эксперимента в 2019 г. были осуществлены действия для целеполагания.
На первом этапе изучены запросы системы здравоохранения Российской Федерации с позиций того, что перспективное становление технологий искусственного интеллекта должно быть согласовано с общим направлением развития отечественной системы охраны здоровья, целями и задачами национальных проектов в данной области. При этом учтены также эпидемиологический и социальные аспекты в плане борьбы с социально значимыми заболеваниями, состояния и проблематики массовых профилактических осмотров, основных проблем служб лучевой диагностики и т. д. Также с социологической точки зрения изучены ожидания врачебного сообщества от внедрения технологий ИИ. Определены наиболее перспективные направления для масштабного внедрения искусственного интеллекта:
– анализ результатов массовых профилактических осмотров лучевыми методами;
– выявление признаков онкологических заболеваний, особенно – на ранних стадиях;
– поддержка врачебных решений по оптимальной, предписанной маршрутизации пациентов;
– оппортунистический поиск предикторов или проявлений особо значимых патологий;
– влияние на производительность труда врача-рентгенолога путем автоматизированного формирования проектов описаний с использованием стандартизированных систем протоколирования и классификаций.
Установлено требование по точности и сбалансированности технологий искусственного интеллекта; категорической недопустимости создания дополнительной необоснованной нагрузки на систему здравоохранения (за счет избыточной генерации ложноположительных или клинически нецелесообразных результатов).
Подробно эти материалы изложены в монографии о результатах первого года Эксперимента29.
На втором этапе стандартизирован, описан и проанализирован основной производственный процесс службы лучевой диагностики, включающий взаимодействие лечащего врача, пациента, рентгенолаборанта, врачей-рентгенологов, экспертов посредством общей информационной системы. Выявлены ключевые проблемы и риски процесса; соответственно установлены конкретные трудовые операции в его составе, автоматизация которых потенциально позволит снизить риски дефектов и ошибок, повысить производительность труда, увеличить скорость постановки диагноза и начала специального лечения30.
Детально проработан актуальный на момент начала Московского эксперимента (2019—2020 гг.) клинический контекст, в котором осуществляется основной производственный процесс.
На третьем этапе введено понятие «направление», по сути, представляющее собой конкретную клинико-диагностическую задачу – выявление на результатах определенного вида лучевого исследования рентгенологических признаков, ассоциируемых с конкретным синдромом или заболеванием, с учетом клинического контекста. Среди критичных факторов клинического контекста, прежде всего, выделяли вид, форму и условия оказания медицинской помощи, а также характер исследования – профилактическое или диагностическое. Очевидно, что таких задач может быть множество, поэтому была осуществлена приоритизация по следующему алгоритму:
1. Анализ частоты выполнения исследований в сети медицинских организаций государственной системы здравоохранения г. Москвы за год.
2. Определение наиболее часто выполняемых видов исследований (как модальностей, так и конкретных медицинских услуг).
3. Определение наиболее часто выявляемых патологий на результатах этих исследований.
4. Исключение патологий с нетипичной (неспецифичной) рентгенологической картиной и/или не имеющих четких клинических рекомендаций по дальнейшей маршрутизации пациента.
5. Формирование клинико-диагностической задачи – конкретного направления Московского эксперимента.
По этому принципу первыми направлениями стали выполняемые в амбулаторных условиях диагностическая компьютерная томография органов грудной клетки для выявления признаков пневмонии (в том числе вирусной), злокачественных новообразований; профилактическая рентгенография (флюорография) органов грудной клетки для выявления туберкулеза, воспалительной и онкологической патологии и т. д. Именно массовость и социально значимый характер этих и ряда иных исследований обусловили их лидерство среди направления Московского эксперимента, тем самым технологиям ИИ были «гарантированы» не только медицинская результативность, но и масштабность применения (таким образом заложены еще и основы нового сегмента рынка).
Из клинического контекста проистекают стандартизированные требования к способам применения конкретной технологии искусственного интеллекта, видам и формам представления результатов ее работы, измеримым метрикам качества.
Поэтому на четвертом этапе концептуально определено, что программное обеспечение на основе технологий ИИ при обработке результатов лучевых исследований должно осуществлять 3 основные функции:
1. Приоритизировать в рабочем списке врача-рентгенолога результаты исследований, содержащих признаки патологии.
2. Маркировать патологические находки на диагностическом изображении, предоставленном в виде дополнительной серии (не изменяя и не влияя при этом на исходное изображение).
3. Предоставлять проект текстового описания результатов исследования и обнаруженных патологических проявлений.
Для развития этих концептуальных положений на пятом этапе разработаны базовые диагностические требования (БДТ) – стандартизированные требования к результатам работы ИИ при решении данной клинико-диагностической задачи (то есть при работе по конкретному направлению Московского эксперимента). Требования включают:
1) вид лучевого исследования (модальность, анатомическая область, проекция и т.д.);
2) клиническую задачу для ИИ (целевой синдром или заболевание);
3) рентгенологические признаки целевого патологического состояния, для которых ожидается положительный и/или отрицательный ответ ИИ;
4) содержание ответа ИИ – форма (терминология, классификации, системы репортировния, единицы измерений и т.д.) и структура (обязательные и опциональные компоненты);
5) формат ответа (каждому элементу содержания ответа соответствует определенный формат: число, контур/маска, текст и т.д.);
6) техническая форма ответа (Apache Kafka Message, DICOM, DICOM SR и т.д.).
Подчеркнем, что БДТ прямо проистекают из клинического контекста: ИИ должен предоставить врачу-рентгенологу тот результат, которые необходим именно в конкретной ситуации. Например, при интерпретации профилактического рентгеновского исследования молочных желез (маммографии) результат работы ИИ должен представлять собой не абстрактную тепловую карту или дифференциальную диагностику выявленных образований, а классификацию по стандартизированной системе BI-RADS.
В основе БДТ лежат клинические рекомендации Министерства здравоохранения Российской Федерации, а также иные научные и методические материалы с высоким уровнем достоверности и убедительности. Ссылки на использованные при подготовке документы и публикации обязательно размещаются в БДТ по каждому направлению Московского эксперимента.
Разработка и периодическая актуализация базовых диагностических требований ведется группой врачей-экспертов с последующим их утверждением научно-проблемной комиссией НПКЦ ДиТ ДЗМ. БДТ публикуются на сайте Московского эксперимента (https://mosmed.ai/ai/docs/) и периодически издаются в формате методических рекомендаций, утвержденных Департаментом здравоохранения Москвы31.
Для медицинского работника – непосредственного пользователя технологий искусственного интеллекта – именно благодаря базовым диагностическим требованиям реализуется принцип объяснимости ИИ.
Также на данном этапе установлены единые требования к скорости машинной обработки данных. Определено и включено в правила Московского эксперимента максимальное время, которое ИИ-сервис может затратить на прием, анализ и обратную передачу результатов. Методически требовалось, чтобы результат работы ИИ-сервиса оказывался в ЕРИС ЕМИАС до того, как врач начнет работу с данным исследованием. Очевидно, что выполнение требований к скорости описаний зависит не только от характеристик и возможностей серверного обеспечения ИИ-сервиса, но и от каналов связи. Однако предоставление результатов от СИИ во время или, тем более, после описания исходного изображения снижает шансы их использования врачом-рентгенологом до нуля. Поэтому требования были установлены достаточно жесткие, впрочем, как показала дальнейшая практика, они оказались полностью выполнимыми. Более того, длительность обработки стала одним из параметров технологического мониторинга (см. параграф 2.6). Стандартизация длительности обработки данных СИИ предотвратила как изменения временных норм по оказанию медицинских услуг, так и негативное влияние на упорядоченные рабочие процессы врача-рентгенолога.
Шестой этап был связан с решением технических задач. При изучении запросов системы здравоохранения Российской Федерации было установлено, что в соответствии с действующим законодательством программное обеспечение на основе технологий ИИ должно быть интегрировано с информационными системами в сфере здравоохранения субъектов РФ и/или медицинскими информационными системами32. Поэтому в рамках Московского эксперимента была изначально предусмотрена бесшовная интеграция искусственного интеллекта. Это означает, что соответствующее программное обеспечение должно быть интегрировано с государственной информационной системой в сфере здравоохранения субъекта РФ, вести обмен данными с централизованным архивом медицинских изображений, получать и направлять данные в электронную карту пациента. Медицинский работник при этом должен работать с одним, привычным интерфейсом медицинской информационной системы. Для реализации сказанного проводится интеграция программного обеспечения на основе технологий искусственного интеллекта с Единым радиологическим информационным сервисом автоматизированной информационной системы города Москвы «Единая медицинская информационно-аналитическая система города Москвы» (ЕРИС ЕМИАС). Соответствующие технические положения и стандарты обобщены в базовых функциональных требованиях (БФТ). Они содержат унифицированную терминологию, технические требования к передаваемым данным (прежде всего – к ответу с результатами работы ИИ), к документированию, форматам и содержанию сообщений, маркировки изображений, описания тегов, положения по стандартизации и управлению рисками. БФТ также доступны на официальном сайте Московского эксперимента (https://mosmed.ai/ai/docs/).
Отдельным важнейшим аспектом технической и методической подготовки, тесно связанным с предыдущими этапами, стала стандартизация настроек диагностических устройств. В тесном взаимодействии с производителями оборудования унифицированы номенклатура, протоколы, заполнение DICOM-тегов. Тем самым обеспечен единый стандарт лучевых исследований в сети медицинских организаций ДЗМ.
Первые версии БФТ и БДТ опубликованы в монографии с обобщением результатов первого года Московского эксперимента33.
Таким образом, основным методологическим подходом при внедрении ИИ в практическое здравоохранение служит триада стандартизированных документов:
1. Перечень обоснованных клинико-диагностических задач (направлений), решаемых в рамках стандартизированного производственного процесса в актуальном клиническом контексте.
2. Базовые диагностические требования.
3. Базовые функциональные требования.
Надо подчеркнуть, что решение каждой клинико-диагностической задачи представляет собой автоматизацию определенной трудовой операции в рамках стандартизированного производственного процесса, а также дает измеримый результат, пригодный для интегральной оценки результативности и эффективности внедрения технологий искусственного интеллекта.
Процесс практического использования ИИ должен сопровождаться тестированием и мониторингом безопасности и качества; подробно эти вопросы изложены далее, в параграфе 2.4.
2.2. Методология создания наборов данных
2.2.1. Определения и общие положения
Набор данных – состав данных, которые структурированы или сгруппированы по определенным признакам, соответствуют требованиям законодательства Российской Федерации и необходимы для разработки программ для электронных вычислительных машин на основе искусственного интеллекта34.
Разметка данных – этап обработки структурированных и неструктурированных данных, в процессе которого данным (в том числе текстовым документам, фото- и видеоизображениям) присваиваются идентификаторы, отражающие тип данных (классификация данных), и (или) осуществляется интерпретация данных для решения конкретной задачи, в том числе с использованием методов машинного обучения35.
Наборы данных (НД)36 – основа функционирования искусственного интеллекта. Они необходимы при создании моделей (обучение, тестирование, дообучение), на этапе использования (клинические испытания, внешняя валидация, первичные и повторные тестирования), а также в научных исследованиях. В Национальной стратегии развития искусственного интеллекта на период до 2030 года наборам данных уделено особое внимание37:
– формирование НД определено одним из направлений повышения доступности инфраструктуры для СИИ;
– регламенты работы с наборами данных выбраны одними из основных направлений внедрения доверенных технологий искусственного интеллекта в органах публичной власти и организациях;
– законодательное обеспечение возможности доступа разработчиков технологий искусственного интеллекта к различным видам данных указано одним из основных направлений создания комплексной системы нормативно-правового регулирования общественных отношений, связанных с развитием и использованием технологий искусственного интеллекта, и обеспечения безопасности применения таких технологий;
– создание библиотек наборов данных входит в основные направления оказания поддержки организациям – разработчикам технологий искусственного интеллекта, а также в основные направления укрепления международного сотрудничества в области использования ТИИ.
С 2015 г. в НПКЦ ДиТ ДЗМ начаты системные научные исследования в области создания и применения наборов данных для обучения и тестирования искусственного интеллекта. Для научного тестирования СИИ эмпирически сформирован и размечен ряд наборов данных, четыре из которых получили официальное свидетельство о государственной регистрации базы данных. К 2018 г. научно обоснован оригинальный метод разметки очагов в легких сферическими кластерами; созданы алгоритмическая основа и программный комплекс, позволяющие проводить разметку компьютерных томограмм ОГК; подготовлен набор данных деперсонализированных размеченных компьютерных томограмм органов грудной клетки CTLungCa-500. Для помощи многочисленным разработчикам этот набор данных впервые в Российской Федерации размещен в свободном доступе. Он был скачан несколько десятков раз и использован для самотестирования и обучения несколькими научными группами разработчиков и компаниями38.
В ходе подготовки и реализации Московского эксперимента потребовалось создание большого количества эталонных (валидированных) наборов данных, поэтому был организован непрерывный процесс их формирования (рисунок 2.1), в первую очередь для тестирования ИИ-сервисов, а также для научных исследований, нацеленных на изучение качества работы и потенциала развития СИИ, поиск новых направлений их применения39.
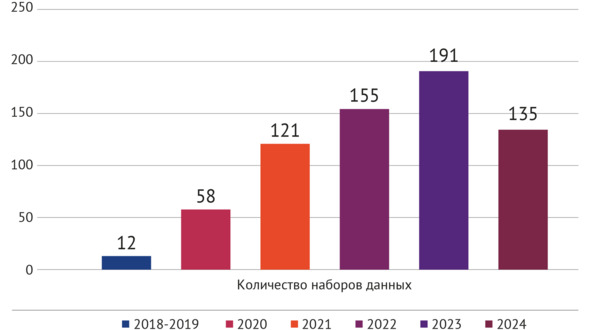
Рисунок 2.1 – Динамика количества наборов данных, созданных в ГБУЗ «НПКЦ ДиТ ДЗМ» в 2018—2024 гг.
В процессе накопления опыта возникали новые задачи, и наборы данных создавались уже для обучения собственных моделей ИИ. Так были созданы инструменты контроля качества рентгенографии органов грудной клетки40, анализа результатов компьютерной томографии печени CT HepatoScan Наличие богатого опыта формирования НД позволило сделать их самих объектом научного интереса и сформировать методологию их создания41, принципы организации42 и инструменты работы с данными43.
Путем систематизации эмпирического опыта и результатов экспериментально-лабораторной работы научно обоснованы и реализованы на практике:
– унифицированные основные характеристики наборов данных для разработки и тестирования СИИ в здравоохранении;
– понятие и требования к эталонным наборам данных;
– практико- и клинически ориентированная классификация наборов данных;
– обобщенная методология формирования наборов данных;
– мероприятия по организации разметки и контролю ее качества;
– формализованный производственный процесс создания наборов данных.
Все перечисленные разработки носят универсальный характер и могут применяться в разных клинических направлениях.
Научно-практическая ценность методологии описания, сбора и разметки данных, разработанной коллективом авторов, была подтверждена оценке независимыми группами исследователей. В первую волну пандемии COVID-19 по оригинальной методологии создан крупнейший в мире набор данных результатов компьютерной томографии органов грудной клетки у пациентов с ПЦР-подтвержденной новой коронавирусной инфекцией («MosMedData: результаты исследований компьютерной томографии органов грудной клетки с признаками COVID-19» (MosMedData-CT-COVID19-type VII-v 2)44). Этот набор был размещен в открытом доступе, благодаря чему использован для обучения и тестирования алгоритмов ИИ учеными из разных стран мира. Данное утверждение подтверждается 11 статьями, индексируемыми системой Pubmed (в т.ч. авторских коллективов из Китая – 3, США – 2, Ирана – 1, международных групп ученых – 5)45.
Благодаря Московскому эксперименту впервые в Российской Федерации реализована библиотека наборов данных для сферы здравоохранения (https://mosmed.ai/datasets/). В библиотеке размещены свыше 250 наборов данных, по состоянию на 01.01.2025 зафиксировано 4709 скачиваний и десятки тысяч просмотров конкретных наборов. В пятерке лидеров по используемости – «MosMedData-CT-COVID19-type VII-v 2» (1093 скачиваний), «MosMedData-CT_XR_MMG-MULTI-type II» (481 скачивание), «MosMedData-CT-HEMORRHAGE-type VIII» (364 скачивания), «MosMedData-ECG-MULTI-type VII» (311 скачиваний), «MosMedData-MRI-MS-type II» (284 скачивания). Разработанные методологии целеполагания, стандартизации, работы с данными используются при создании технологий искусственного интеллекта, а также стали основой национальных стандартов.
2.2.2. Принципы классификации и организации наборов данных в лучевой диагностике
В лучевой диагностике набор данных представляет собой упорядоченную совокупность:
– диагностических изображений одной модальности и/или однотипных медицинских документов (например, протоколов описаний результатов исследований);
– сведений о наличии, характере и локализации патологических изменений на изображениях; для текстовых документов – библиотеки ключевых слов, словосочетаний и их критичных сочетаний;
– сведений о верификации диагноза (опционально).
В ходе Московского эксперимента установлено, что набор данных должен содержать следующие сведения описательного характера:
1) номер свидетельства о государственной регистрации базы данных в качестве результата интеллектуальной деятельности (рекомендательно);