


Полная версия
Искусственный интеллект в лучевой диагностике: Per Aspera Ad Astra
– расширяемость ПО, возможность добавления новых модулей.
2. Загрузка и сохранение. Поддерживаемые форматы:
– поддержка основных форматов медицинских изображений;
– возможность загрузки иерархической структуры папок DICOM, загрузки нескольких файлов с сегментациями и исходными изображениями, одновременной работы с несколькими сегментациями;
– возможность просматривать теги DICOM;
– сохранение векторных данных при ручной разметке полилиниями, полигонами и другими фигурами и возможность их дальнейшего изменения.
3. Возможности визуализации медицинских изображений:
– наличие 3D-визуализации исходного изображения и сегментации;
– наличие стандартных окон преобразования из HU-интенсивностей в интенсивность цвета;
– возможность менять расположение окон просмотра;
– возможность менять направления осей проекции;
– возможность управления контрастом (по области, на основе гистограммы интенсивности);
– отображение информации о номере среза, HU-плотности, позиции курсора;
– наличие крестового курсора для ориентации в нескольких проекциях.
4. Ручные и дополнительные инструменты:
– стандартные ручные инструменты, наличие ручных инструментов редактирования в 3D-окне;
– логические операции со слоями сегментации;
– возможность отменить последнее действие;
– определение диапазона интенсивностей по области;
– работа с областью сегментации как с графом (удаление/выделение компоненты/главной компоненты, удаление определенных по размеру компонент);
– сглаживание полученной области (удаление полостей, выпуклостей и др.);
– расширение/сужение области на определенную величину.
5. Полуавтоматические инструменты:
– наиболее эффективные методы – Thresholds, SurfaceCut, Fill between slices, Region Growing 2D, Intelligent Scissors и RITM Interactive.
Существуют три основных подхода к техническому обеспечению разметки результатов лучевых исследований:
1. Применение стандартного DICOM-просмотровщика и электронных таблиц из пакета офисных программ.
2. Применение специального разработанного оригинального программного обеспечения.
3. Применение программного обеспечения с открытым исходным кодом.
Первый подход максимально широко доступен, вместе с тем он имеет ряд принципиальных ограничений:
– позволяет выполнять только самые простые виды разметки (например, фиксировать в таблице координаты очагов или некие размеры);
– возможна только ручная разметка;
– крайне сложно организовать и управлять работой команды врачей-разметчиков.
Второй подход оптимален с точки зрения обеспечения максимально релевантной функциональности. Подобные программные продукты обычно содержат модули собственно разметки с различными инструментами работы с изображениями (измерений, оконтуривания и проч.), управления работой команды (так называемые «оркестраторы»), а также единую базу данных. Возможно проведение как ручной, так и полуавтоматической или автоматической разметки. К ограничениям подхода можно отнести высокие финансовые затраты на разработку собственного решения, сложность масштабирования в силу лицензионных ограничений и изначального создания программного обеспечения для решения узких задач конкретной группы разработчиков СИИ.
Третий подход оптимален с точки зрения баланса сильных и слабых сторон. В настоящее время он приобрел значительную популярность. В силу активного конкурентного развития бесплатное программное обеспечение с открытым исходным кодом зачастую не уступает коммерческому или проприетарному.
Далее приводится описание и специально проведенное сравнение программного обеспечения для разметки результатов лучевых исследований с открытым исходным кодом, впервые опубликованное в статье «Обзор современных средств разметки цифровых диагностических изображений»81.
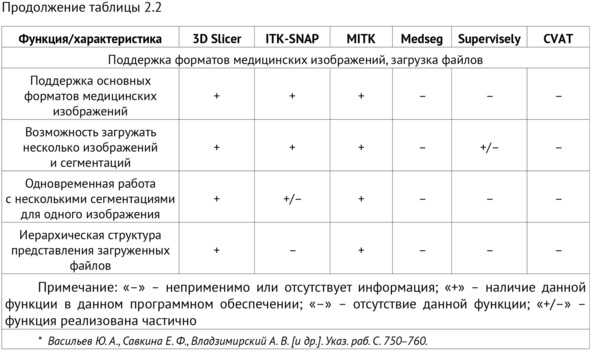
Свод характеристик, включенных в обзор программных решений представлен в таблице 2.2.
3D Slicer82. Модульный продукт широкого профиля, позволяющий обрабатывать многомерные изображения и обладающий наиболее обширным функционалом, по сравнению с аналогами, в области сегментации, регистрации, фильтрации и других областях обработки медицинских и других биологических изображений.
ITK-SNAP83. Программный продукт, специализирующийся на сегментации структур в многомерных диагностических изображениях.
MITK84. Программный продукт на основе библиотеки c открытым исходным кодом Medical Imaging Interaction Toolkit.
Medseg85. Программный продукт с базовой функциональностью и инструментами ручной разметки. Содержит ряд автоматических и полуавтоматических методов на основе нейронных сетей для сегментации различных органов и некоторых видов патологии.
CVAT86. Веб-платформа с открытым исходным кодом для ручной и полуавтоматической разметки изображений и видео. Требует преобразования медицинских изображений в графические форматы.
Supervisely87. Коммерческая веб-платформа для осуществления всех этапов обучения моделей компьютерного зрения, включая задачи организации, разметки (аннотации) и аугментации данных, обучения моделей, обеспечения качества и многие другие. Добавлена в обзор для наглядности сравнения (непосредственно в НПКЦ ДиТ ДЗМ данный продукт не применяется).
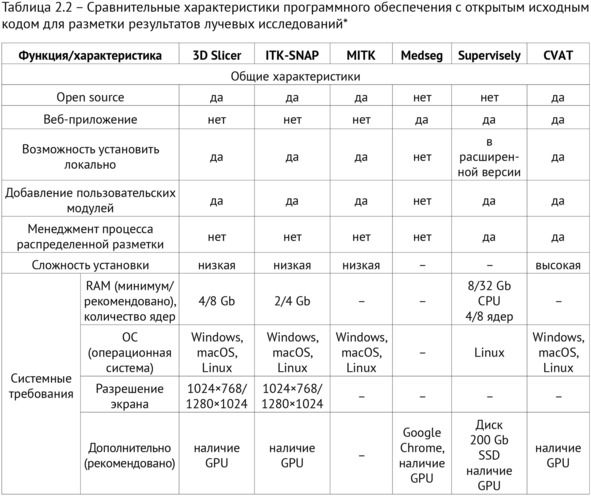
Функционал организации и управления процессом разметки имеется только у CVAT и Supervisely. В частности, CVAT позволяет хранить изображения на локальном сервере и осуществлять распределенную работу нескольких экспертов. У Supervisely присутствует обширная функциональность по управлению, включая экзамены для экспертов по разметке, онлайн-проверки разметки одних экспертов другими, расчет метрик согласованности разметки и др.
Возможностью расширять функциональность и добавлять новые пользовательские модули обладают 3D Slicer, MITK, Supervisely, CVAT; все перечисленные решения снабжены развернутым руководством для программирования и сопроводительной документацией.
В последних версиях ITK-SNAP появилась возможность удаленного подключения к дополнительным сервисам обработки изображений (DDS) и создания собственного сервиса.
Наибольшее разнообразие форматов обрабатываемых исходных изображений и форматов областей сегментации имеется у 3D Slicer. Основные форматы (DICOM, NRRD, NIfTI) и некоторые другие поддерживаются MITK, ITK-SNAP. Supervisely работает только с форматами DICOM, NRRD; Medseg – c форматом NIfTI, DICOM.
На этом фоне CVAT «не умеет» работать с медицинскими изображениями в традиционных форматах, необходимо предварительно конвертировать изображения в графические форматы с помощью поставляемой разработчиками утилиты. Следует отметить, что конвертация медицинских изображений влечет за собой риск неверной интерпретации данных. Например, при преобразовании КТ-изображений в графические форматы происходит потеря точности из-за более узкого диапазона дискретных значений интенсивностей цвета по сравнению с исходным диапазоном, теряется информация о параметрах протокола сканирования и т. д.
Наиболее удобная загрузка файлов реализована в 3D Slicer. Этот модуль поддерживает загрузку нескольких сегментаций и изображений в различных форматах, а также изображений формата DICOM из иерархической структуры папок. В MITK и 3D Slicer загруженные файлы представлены в виде иерархической структуры, отображающей связь между сегментациями и исходными изображениями.
Можно гибко менять видимость различных изображений и сегментаций в окне просмотра, сравнивать несколько сегментаций между собой. Дополнительно в 3D Slicer существует возможность просматривать и синхронизировать несколько серий изображений одновременно.
Относительно представления и сохранения данных сегментации следует сказать, что у MITK, 3D Slicer и Medseg каждая сегментация представлена слоями для каждого класса разметки. В CVAT и Supervisely принципиально другое представление разметки – в виде объектов: полигонов, прямоугольников, растровых объектов и др. В CVAT объекты сгруппированы по изображениям, к которым они относятся. В Supervisely формируются классы разметки на основе различных типов (прямоугольник, полигон, маска, любая форма). Создаются объекты на основе классов разметки, включающие фигуры только указанного типа. Благодаря такой структуре в CVAT и Supervisely полигоны и другие векторные фигуры можно редактировать после создания.
Сохранение разметки удобно реализовано в 3D Slicer. Можно выборочно сохранять произвольные наборы исходных изображений и областей сегментации в отличие от другого ПО (MITK, ITK-SNAP), где можно сохранить или все рабочее пространство, или каждую сегментацию по отдельности. В Supervisely и СVAT присутствует возможность сохранения векторных объектов в векторном виде для последующей коррекции, что делает данное ПО объектом выбора, когда разметка требует сохранения векторной информации для полигонов, прямоугольников, например, в случае аннотаций прямоугольниками для задачи детекции.
Отдельный вопрос – возможности визуализации медицинских изображений в программном обеспечении для разметки. Для определения минимальной функциональности проведен специальный опрос врачей-рентгенологов, участвующих в разметке наборов данных, и трех специалистов по подготовке наборов данных НПКЦ ДиТ ДЗМ. Решение о включении каждой из функций в анализ принимали на основании большинства голосов опрошенных экспертов (таблица 2.3).

CVAT не обладает средствами визуализации медицинских изображений, так как работает уже с графическими форматами. Возможность 3D-отображения исходного изображения есть только в MITK, ITK-SNAP и 3D Slicer. Наличие настраиваемых и стандартных окон преобразования HU-интенсивностей в интенсивности цвета есть в большинстве программ, кроме ITK-SNAP, где контрастность и окно преобразования настраиваются по гистограмме HU-интенсивности. В 3D Slicer доступна автонастройка контраста по выбираемому региону.
Инструменты ручной сегментации и дополнительные возможности корректировки области сегментации в целом идентичны в различных программах. В CVAT, Supervisely доступна посткоррекция вручную созданных векторных объектов. В 3D Slicer есть удобная возможность редактировать области сегментации в 3D-окне, а также инструмент «Ножницы», позволяющий вырезать подпространства, ограниченные цилиндрической поверхностью в срезах и в 3D-окне.
В 3D Slicer, а также в MITK существует множество дополнительных инструментов для коррекции сформированной области сегментации: логические операции со слоями, расширение/сужение области сегментации на некоторую величину, работа с областями как с элементами графа (выделение главной компоненты, удаление маленьких по размеру компонент, выделение/удаление выбранной компоненты), сглаживание различными методами (заливка полостей, удаление выпуклостей и др.).
Инструменты полуавтоматической сегментации. Полуавтоматическая сегментация служит одной из самых важных частей ПО для разметки. Она предполагает ввод определенных данных человеком, например, области интереса или ключевых точек, либо требует дополнительной ручной настройки параметров. Алгоритмы, лежащие в основе полуавтоматических методов, способны реализовать различные подходы. Это могут быть классические подходы или же подходы на основе методов машинного обучения (нейронные сети, классические алгоритмы машинного обучения).
Автоматическая сегментация. Только небольшая часть рассмотренного ПО (3D Slicer, Medseg) содержит готовые модули для автоматической сегментации. Большинство модулей являются моделями глубокого обучения и связаны с сегментацией различных органов. Так, например, в 3D Slicer есть плагины по сегментации височной кости, дыхательных путей, опухолей молочной железы, печени и ее сосудов, других сосудов, мозга, сердца и других структур по КТ/МРТ-изображениям. В программе Medseg есть модели, сегментирующие легкие, печень, почки, поджелудочную железу и другие органы, и виды патологии по КТ/МРТ-снимкам. Недостаток Medseg, ограничивающий возможность применения моделей, – невозможность локальной установки.
Проведенный обзор может быть использован при принятии решений относительно выбора программного обеспечения с открытым исходным кодом для разметки результатов лучевых исследований.
2.2.5. Специальные и перспективные наборы данных
Сложные наборы данных. Любому практикующему врачу знакомо выражение «студенческий случай», означающее проявление данного заболевания в максимальном соответствии классическому его описанию. В этой ситуации семиотика и симптоматика настолько типичны, что требуются лишь элементарные знания в предметной области для точной диагностики. Вместе с тем в реальной медицинской практике такие случаи не слишком распространены, чаще всего врач вынужден проводить сложный аналитический процесс и глубокую дифференциальную диагностику. Подавляющее большинство современных медицинских СИИ обучают именно на «студенческих случаях». С одной стороны, это представляет собой закономерный этап развития, с другой – создает значительные ограничения для масштабирования применения соответствующих технологий. Требуется создание наборов данных, содержащих клинические случаи со сложными, нетипичными, неочевидными проявлениями патологического процесса. В НПКЦ ДиТ ДЗМ ведутся соответствующие научные исследования.
Морфометрические наборы данных. В контексте расширения возможностей СИИ и использования их не только в качестве классификаторов важнейшую роль играет морфометрия (автоматизация рутинных измерений). Будучи весьма перспективным, это направление одновременно является и одним из наименее изученных: в мировой практике крайне мало опыта по применению таких технологий, а обоснованные методики подготовки НД и тестирования ИИ-сервисов вовсе отсутствуют. Тем более сложной и вместе с тем интересной становится задача подготовки морфометрических наборов данных88. Среди нерешенных вопросов – оценка выбросов в измерениях, обоснование количества разметчиков и стратегии разметки данных, стандартизация методик измерений, стратегии применения морфометрии. Данное направление появилось в Московском эксперименте в конце 2023 года, и на сегодняшний день немногие ИИ-сервисы смогли решить отдельные задачи измерения анатомических структур. Методологии создания морфометрических наборов данных и оценки качества соответствующих ИИ-сервисов – предмет текущих научных исследований НПКЦ ДиТ ДЗМ.
Обогащенные наборы данных. Обогащенные клинической информацией наборы данных – одно из перспективных направлений развития СИИ, потенциально реализующих типичный именно для практического здравоохранения комплексный подход к диагностике заболеваний. Объединение максимально возможного количества данных из медицинской документации пациента может не только расширить возможности диагностики и прогнозирования течения заболевания, но и позволит искать новые зависимости, совершать открытия в области медицины и развивать профилактическое направление. Основные препятствия при создании обогащенных НД: неструктурированное представление информации в медицинской документации; ограничение доступа к документации, сформированной в разных медицинских организациях; отсутствие единых стандартов, в том числе в части терминологии, величин измерений и т. д. Благодаря наличию и возможностям ЕРИС ЕМИАС перечисленные препятствия медленно, но верно преодолеваются89. Разработаны стратегии (создание НД «с нуля» или обогащение уже готового набора изображений) и подходы к определению объема выборки, уточнены особенности работы с литературой и медицинской информационной системой при выборе и внесении клинических параметров. Научно-практическая работа в данном направлении активно продолжается. Обеспечивается автоматизация процессов работы с клиническими данными, ведется совершенствование алгоритмов работы с неструктурированными данными, разработка методик сбора и обработки данных и т. д.
Динамические наборы данных. Оценка динамических изменений в состоянии здоровья пациента по результатам серии лучевых исследований – актуальная и весьма распространенная практическая задача. Для ее решения с помощью СИИ требуются специальные динамические НД, отражающие, например, рост новообразований, прогрессирование демиелинизации, течение репаративных процессов и т. д. Практическое развитие соответствующих ИИ-сервисов сталкивается с проблемами технического характера на этапе организации их работы с действующими информационными системами в сфере здравоохранения. Эти проблемы еще предстоит решить. В рамках решения методологических задач в НПКЦ ДиТ ДЗМ ведутся научные исследования по анализу ошибок в динамическом ряду изображений, а также осуществляется доработка программы «Платформа подготовки наборов данных» для поиска и сбора данных в динамике90. Представляет значительный интерес комбинация динамических и обогащенных наборов данных.
Наборы данных для оценки технического качества. Автоматизация оценки качества результатов лучевых исследований актуальна для двух направлений:
1. Непрерывное повышение качества работы рентгенолаборантов (в том числе путем выявления типичных ошибок при выполнении исследования, определения и устранения их причин), устранение необходимости повторных исследований одного и того же пациента с соответствующим снижением затрат и недопущением конфликтных ситуаций.
2. Снижение числа ложных срабатываний СИИ путем предварительной оценки и исключения из анализа результатов исследований, выполненных с технологическими дефектами. К нарушениям технического качества относятся некорректные DICOM-теги, нарушения укладки, инородные тела, нарушения экспозиции дозы, «обрезка» областей изображения, артефакты различного происхождения и проч.91 Перспективно формирование соответствующих наборов данных по видам исследований и анатомическим областям.
«Умение» ИИ-сервисов обнаруживать исследования с дефектами и исключать их из анализа обязательно проверяется в рамках Московского эксперимента. Случаи с техническими дефектами обязательно входят в наборы данных, применяемые для функционального тестирования (см. параграф 2.6). В НПКЦ ДиТ ДЗМ разработан оригинальный ИИ-сервис для анализа технологического качества результатов рентгенографии органов грудной клетки92. Очевидно, что создание и тестирование этого инструмента потребовало формирования соответствующего набора данных93. ИИ-сервис интегрирован в программу «Платформа подготовки наборов данных» для внутреннего контроля качества создаваемых НД, а также тестируется в рамках пилотного проекта в медицинских организациях г. Москвы.
Синтетические наборы данных. В настоящее время генеративный ИИ рассматривается как универсальное средство синтеза необходимых визуальных данных.
Большие генеративные модели – модели искусственного интеллекта, способные интерпретировать (предоставлять информацию на основании запросов, например, об объектах на изображении или о проанализированном тексте) и создавать мультимодальные данные (тексты, изображения, видеоматериалы и тому подобное) на уровне, сопоставимом с результатами интеллектуальной деятельности человека или превосходящем их94.
В глобальной перспективе методы и инструменты синтеза результатов лучевых исследований и связанных с ними данных потенциально позволяют95:
– генерировать новые изображения для обогащения наборов данных;
– создавать дополнительные изображения других модальностей: КТ из МРТ, ПЭТ из МРТ, контрастно-усиленные исследования из бесконтрастных;
– улучшить качество изображений путем шумоподавления, удаления артефактов и реконструкции изображений;
– предсказывать динамику патологии.
Проблематика синтетических наборов данных в текущий момент времени рассматривается преимущественно в рамках сугубо научных исследований. В подавляющем большинстве таковых в качестве визуальной генеративной модели применяются генеративно-состязательные сети – GAN (от англ. Generative adversarial network). GAN состоят из двух противоборствующих сверточных сетей: генератора, который пытается сгенерировать реалистичные изображения, и дискриминатора, который определяет, является ли изображение реальным или синтетическим. Именно данный подход применяется в указанных выше научных исследованиях. Вместе с тем известны общие недостатки GAN-подхода. Во-первых, для GAN, как и для ИИ в целом, характерна зависимость результата от качества и объема обучающих данных. Во-вторых, для GAN-моделей актуальна проблема сходимости и коллапса модели, вызывающих появление одного и того же результата при различных входных данных. В рамках проведения научно-исследовательских и опытно-конструкторских работ научным коллективом НПКЦ ДиТ ДЗМ был разработан подход к синтезу бесконтрастных КТ-изображений сосудов из контрастно-усиленной фазы КТ-ангиографического исследования. В качестве решения предложен альтернативный подход к преобразованию размеченных контрастированных КТ-изображений в бесконтрастные с сохранением корректной экспертной разметки. Разработанное для данных целей программное обеспечение не использует машинное обучение и основано на специально разработанном математическом алгоритме подавления контрастирования. Разработанный подход позволяет подавлять контраст-индуцированную детерминированную компоненту сигнала рентгеновской плотности в области брюшного отдела аорты на КТ-изображениях; получать КТ-изображения брюшного отдела аорты, статистически значимо не отличающегося от окружающих мышечных тканей по величине рентгеновской плотности. Главным отличием предложенного подхода от существующих решений является то, что предложенный подход не использует методы синтетической генерации и машинного обучения. Разработанный алгоритм основан на математическом анализе исходных данных, используемая модель позволяет выделить детерминированную компоненту сигнала рентгеновской плотности, что дает возможность получать исходные данные бесконтрастной фазы вместо их синтетической генерации. Таким образом, создание бесконтрастных изображений происходит автоматически и лишено характерных для GAN-подхода недостатков96.
Синтетические наборы данных, несомненно, относятся к перспективным и требуют дальнейшего научного изучения. Многие аспекты их создания и применения при обучении СИИ сталкиваются с серьезными ограничениями, включающими вопросы качества и правдоподобия, этики, безопасности, применимости. В последнее время особое значение приобретает возможность генерировать новые изображения для обогащения наборов данных. По мере развития СИИ в задачи для автоматизированного анализа включается выявление патологии с низкой и крайне низкой распространенностью в популяции. Даже на фоне существования колоссальных централизованных архивов медицинских изображений, как, например, московский ЕРИС ЕМИАС, формирование набора данных из сотен и тысяч случаев конкретного редкого заболевания представляет собой трудноразрешимую задачу. Также крайне проблематично сформировать сбалансированный, например, по полу и возрасту, набор данных из случаев редкого патологического состояния. Дальнейшее научно-практическое развитие синтетических наборов данных потенциально позволит устранить этот барьер.
2.3. Математические и статистические методы при оценке качества систем искусственного интеллекта: проблемные вопросы, унификация подходов
2.3.1. Определение размера выборки при формировании набора данных
Наборы данных формируют для обучения и тестирования СИИ на этапах жизненного цикла. В процессе разработки обычно используют один или несколько наборов данных, которые делят на обучающую, тестовую и в некоторых случаях проверочную выборки. Важно, чтобы тестирование СИИ проводилось на наборе данных, не использовавшемся для обучения. Это позволяет исключить явление переобучения, при котором в итоге тестирования получается смещенная оценка. Обучающая и тестовая выборки должны быть независимы для получения несмещенной оценки при тестировании СИИ. В некоторых случаях используют проверочный набор данных для выбора оптимальной модели в процессе разработки СИИ97.
В общем виде под обучающей выборкой понимают такую, по которой производится настройка (оптимизация) параметров СИИ; под проверочной – предназначенную для проверки применимости параметров системы искусственного интеллекта для отличных от обучающей выборки наборов данных. Тестовая или контрольная выборка – это полностью уникальная выборка, на которой проводят объективную оценку качества параметров обученной системы искусственного интеллекта98.