


Полная версия
The Creativity Code: How AI is learning to write, paint and think
This flood of data is the main catalyst for the new age of machine learning. Before now there just wasn’t enough of an environment for an algorithm to roam around in and learn. It was like having a child and denying it sensory input. We know that children who have been trapped indoors fail to develop language and other basic skills. Their brains may have been primed to learn but didn’t encounter enough stimulus or experience to develop properly.
The importance of data to this new revolution has led many to speak of data as the new oil. If you have access to data you are straddling the twenty-first-century’s oilfields. This is why the likes of Facebook, Twitter, Google and Amazon are sitting pretty – we are giving them our reserves for free. Well, not exactly for free as we are exchanging our data for the services they provide. When I drive in my car using Waze, I have chosen to exchange data about my location in return for the most efficient route to my destination. The trouble is, many people are not aware of these transactions and give up valuable data for little in return.
At the heart of machine learning is the idea that an algorithm can be created that will find new questions to ask if it gets something wrong. It learns from its mistake. This tweaks the algorithm’s equations such that next time it will act differently and won’t make the same mistake. This is why access to data is so important: the more examples these smart algorithms can train on the more experienced they will become, and the more each tweak will refine them. Programmers are essentially creating a meta-algorithm which creates new algorithms based on the data it encounters.
People in the field of AI have been shocked at the effectiveness of this new approach. Partly this is because the underlying technology is not that new. These algorithms are created by building up layers of questions that can help reach a conclusion. These layers are sometimes called neural networks because they mimic the way the human brain works. If you think about the structure of the brain, neurons are connected to other neurons by synapses. A collection of neurons might fire due to an input of data from our senses. (The smell of freshly baked bread.) Secondary neurons will then fire, provided certain thresholds are passed. (The decision to eat the bread.) A secondary neuron might fire if ten connected neurons are firing due to the input data, for instance, but not if fewer are firing. The trigger might depend also on the strength of the incoming signal from the other neurons.
Already in the 1950s computer scientists created an artificial version of this process, which they called the perceptron. The idea is that a neuron is like a logic gate that receives input and then, depending on a calculation, decides either to fire or not.
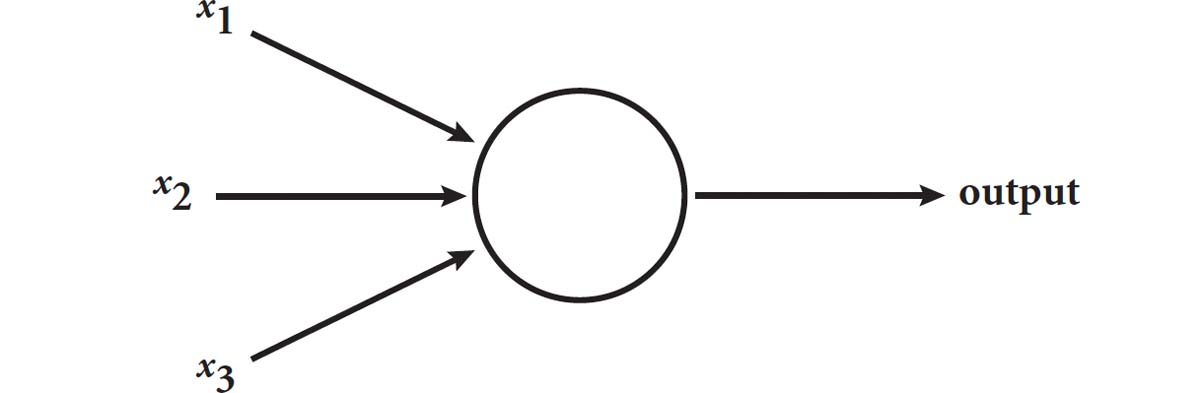
Let’s imagine that the perceptron receives three input numbers. It weights the importance of each of these. In the diagram here, perhaps x1 is three times as important as x2 and x3. It would calculate 3x1 + x2 + x3 and then, depending on whether this fell above or below a certain threshold, it would fire an output or not. Machine learning hinges on reweighting the input if it gets the answer wrong. For example, perhaps x3 is more important in making a decision than x2, so you might change the equation to 3x1 + x2 + 2x3. Or perhaps we simply need to tweak the activation level so the threshold can be dialled up or down in order to fire the perceptron. We can also create a perceptron such that the degree to which it fires is proportional to by how much the function has passed the threshold. The output can be a measure of its confidence in the assessment of the data.
Let’s cook up a perceptron to decide whether you are going to go out tonight. It will depend on three things: (1) is there anything good on TV; (2) are your friends going out; (3) what night of the week is it? Give each of these variables a score between 0 and 10, to indicate your level of preference. For example, Monday will get a 1 score while Friday will get a 10. Depending on your personal proclivities, some of these variables might count more than others. Perhaps you are a bit of a couch potato, so anything vaguely decent on TV will cause you to stay in. This would mean that the x1 variable scores high. The art of this equation is tuning the weightings and the threshold value to mimic the way you behave.
Just as the brain consists of a whole chain of neurons, perceptrons can be layered, so that the triggering of nodes gradually causes a cascade through the network. This is what we call a neural network. In fact, there is a slightly subtler version of the perceptron called the sigmoid neuron that smoothes out the behaviour of these neurons so that they aren’t just simple on/off switches.
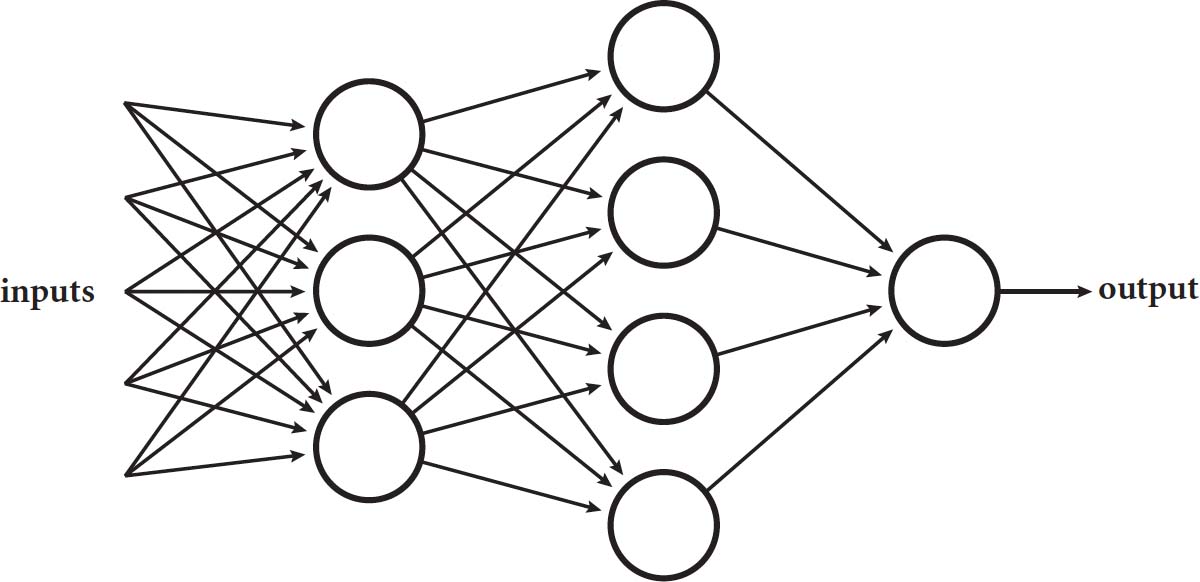
Given that computer scientists had already understood how to create artificial neurons, why did it take so long to make these things work so effectively? This brings us back to data. The perceptrons need data from which to learn and evolve; together these are the two ingredients you need to create an effective algorithm. We could try to program our perceptron to decide when we should go out by assigning weights and thresholds, but it is only by training it on our actual behaviour that it will have any chance of getting it right. Each failure to predict our behaviour allows it to learn and reweight itself.
To see or not to see
One of the big hurdles for AI has always been computer vision. Five years ago computers were terrible at understanding what it was they were looking at. This is one domain where the human brain totally outstrips its silicon rivals. We are able to eyeball a picture very quickly and say what it is or to classify different regions of the image. A computer could analyse millions of pixels, but programmers found it very difficult to write an algorithm that could take all this data and make sense of it. How can you create an algorithm from the top down to identify a cat? Each image consists of a completely different arrangement of pixels and yet the human brain has an amazing ability to synthesise this data and integrate the input to output the answer, ‘cat’.
This ability of the human brain to recognise images has been used to create an extra layer of security at banks, and to make sure you aren’t a robot trawling for tickets online. In essence you needed to pass an inverse Turing Test. Shown an image or some strange handwriting, humans are very good at saying what the image or script is. Computers couldn’t cope with all the variations. But machine learning has changed all that.
Now, by training on data consisting of images of cats, the algorithm gradually builds up a hierarchy of questions it can ask an image that, with a high probability of accuracy, will identify it as a cat. These algorithms are slightly different in flavour to those we saw in the last chapter, and violate one of the four conditions we put forward for a good algorithm. They don’t work 100 per cent of the time. But they do work most of the time. The point is to get that ‘most’ as high as possible. The move from deterministic foolproof algorithms to probabilistic ones has been a significant psychological shift for those working in the industry. It’s a bit like moving from the mindset of the mathematician to that of the engineer.
You may wonder why, if this is the case, you are still being asked to identify bits of images when you want to buy tickets to the latest gig to prove you are human. What you are actually doing is helping to prepare the training data that will then be fed to the algorithms so that they can try to learn to do what you do so effortlessly. Algorithms need labelled data to learn from. What we are really doing is training the algorithms in visual recognition.
This training data is used to learn the best sorts of questions to ask to distinguish cats from non-cats. Every time it gets it wrong, the algorithm is altered so that the next time it will get it right. This might mean altering the parameters of the current algorithm or introducing a new feature to distinguish the image more accurately. The change isn’t communicated in a top-down manner by a programmer who is thinking up all of the questions in advance. The algorithm builds itself from the bottom up by interacting with more and more data.
I saw the power of this bottom-up learning process at work when I dropped in to the Microsoft labs in Cambridge to see how the Xbox which my kids use at home is able to identify what they’re doing in front of the camera as they move about. This algorithm has been created to distinguish hands from heads, and feet from elbows. The Xbox has a depth-sensing camera called Kinect which uses infrared technology to record how far obstacles are from the camera. If you stand in front of the camera in your living room it will detect that your body is nearer than the wall at the back of the room and will also be able to determine the contours of your body.
But people come in different shapes and sizes. They can be in strange positions, especially when playing Xbox. The challenge for the computer is to identify thirty-one distinct body parts, from your left knee to your right shoulder. Microsoft’s algorithm is able to do this on a single frozen image. It does not use the way you are moving (which requires more processing power to analyse and would slow the game down).
So how does it manage to do this? The algorithm has to decide for each pixel in each image which of the thirty-one body parts it belongs to. Essentially it plays a game of twenty questions. In fact, there’s a sneaky algorithm you can write for the game of twenty questions that will guarantee you get the right answer. First ask: ‘Is the word in the first half of the dictionary or the second?’ Then narrow down the region of the dictionary even more by asking: ‘Is it in the first or second half of the half you’ve just identified?’ After twenty questions this strategy divides the dictionary up into 21820 different regions. Here we see the power of doubling. That’s more than a million compartments – far more than there are entries in the Oxford English Dictionary, which roughly come to 300,000.
But what questions should we ask our pixels if we want to identify which body part they belong to? In the past we would have had to come up with a clever sequence of questions to solve this. But what if we programmed the computer so that it finds the best questions to ask? By interacting with more and more data – more and more images – it finds the set of questions that seem to work best. This is machine learning at work.
We have to start with some candidate questions that we think might solve this problem so this isn’t completely tabula rasa learning. The learning comes from refining our ideas into an effective strategy. So what sort of questions do you think might help us distinguish your arm from the top of your head?
Let’s call the pixel we’re trying to identify X. The computer knows the depth of each pixel, or how far away it is from the camera. The clever strategy the Microsoft team came up with was to ask questions of the surrounding pixels. For example, if X is a pixel on the top of my head, then if we look at the pixels north of pixel X they are much more likely not to be on my body and thus to have more depth. If we take pixels immediately south of X, they’ll be pixels on my face and will have a similar depth. But if the pixel is on my arm and my arm is outstretched, there will be one axis, along the length of the arm, along which the depth will be relatively unchanged, but if you move out ninety degrees from this direction it quickly pushes you off the body and onto the back wall. Asking about the depth of surrounding pixels could cumulatively build up to give you an idea of the body part that pixel belongs to.
This cumulative questioning can be thought of as building a decision tree. Each subsequent question produces another branch of the tree. The algorithm starts by choosing a series of arbitrary directions to head out from and some arbitrary depth threshold: for example, head north; if the difference in depth is less than y, go to the left branch of the decision tree; if it is greater, go right – and so on. We want to find questions that give us new information. Having started with an initial random set of questions, once we apply these questions to 10,000 labelled images we start getting somewhere. (We know, for instance, that pixel X in image 872 is an elbow, and in image 3339 it is part of the left foot.) We can think of each branch or body part as a separate bucket. We want the questions to ensure that all the images where pixel X is an elbow have gone into one bucket. That is unlikely to happen on the first random set of questions. But over time, as the algorithm starts refining the angles and the depth thresholds, it will get a better sorting of the pixels in each bucket.
By iterating this process, the algorithm alters the values, moving in the direction that does a better job at distinguishing the pixels. The key is to remember that we are not looking for perfection here. If a bucket ends up with 990 out of 1000 images in which pixel X is an elbow, then that means that in 99 per cent of cases it is identifying the right feature.
By the time the algorithm has found the best set of questions, the programmers haven’t really got a clue how it has come to this conclusion. They can look at any point in the tree and see the question it is asking before and after, but there are over a million different questions being asked across the tree, each one slightly different. It is difficult to reverse-engineer why the algorithm ultimately settled on this question to ask at this point in the decision tree.
Imagine trying to program something like this by hand. You’d have to come up with over a million different questions. This prospect would defeat even the most intrepid coder, but a computer is quite happy to sort through these kinds of numbers. The amazing thing is that it works so well. It took a certain creativity for the programming team to believe that questioning the depth of neighbouring pixels would be enough to tell you what body part you were looking at – but after that the creativity belonged to the machine.
One of the challenges of machine learning is something called ‘over-fitting’. It’s always possible to come up with enough questions to distinguish an image using the training data, but you want to come up with a program that isn’t too tailored to the data it has been trained on. It needs to be able to learn something more widely applicable from that data. Let’s say you were trying to come up with a set of questions to identify citizens and were given 1000 people’s names and their passport numbers. ‘Is your passport number 834765489?’ you might ask. ‘Then you must be Ada Lovelace.’ This would work for the data set on hand, but it would singularly fail for anyone outside this group, as no new citizen would have that passport number.
Given ten points on a graph, it is possible to come up with an equation that creates a curve which passes through all the points. You just need an equation with ten terms. But, again, this has not really revealed an underlying pattern in the data that could be useful for understanding new data points. You want an equation with fewer terms, to avoid this over-fitting.
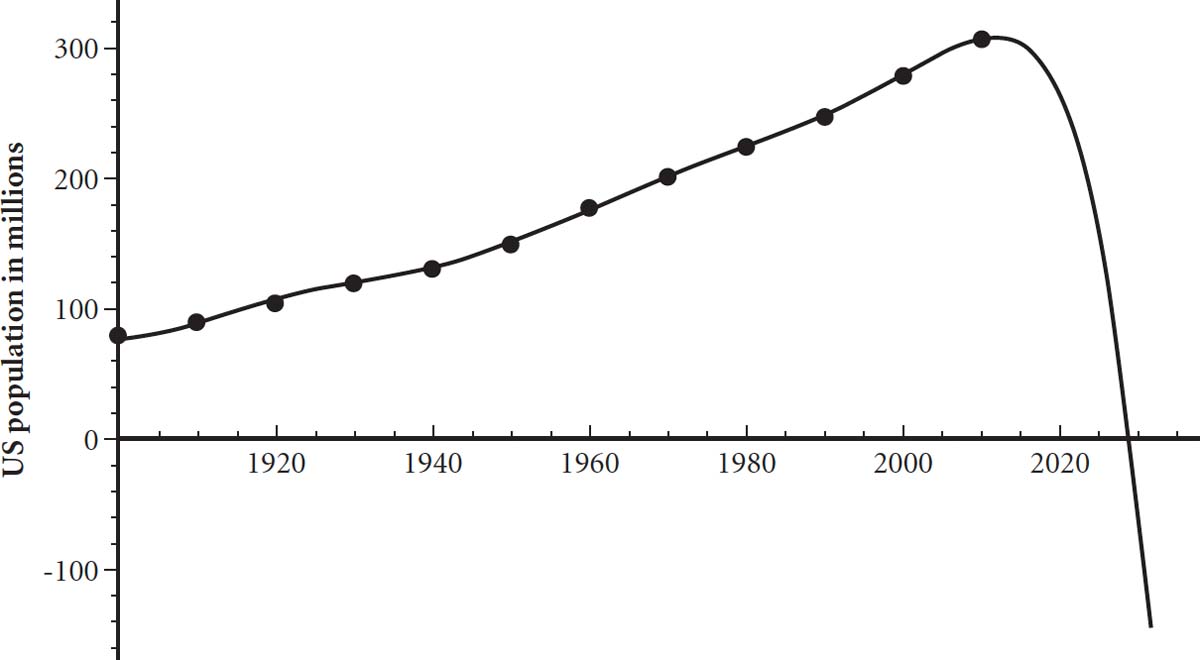
Over-fitting can make you miss overarching trends by inviting you to model too much detail, resulting in some bizarre predictions. Here is a graph of twelve data points for population values in the US since the beginning of the last century. The overall trend is best described by a quadratic equation, but what if we used an equation with higher powers of × than simply x2? Taking an equation with powers all the way up to x11 actually gives a very tight fit to the data, but extend this equation into the future and it takes a dramatic lurch downwards, predicting complete annihilation of the US population in the middle of October in 2028. Or perhaps the maths knows something we don’t!
Algorithmic hallucinations
Advances in computer vision over the last five years have surprised everyone. And it’s not just the human body that new algorithms can navigate. To match the ability of the human brain to decode visual images has been a significant hurdle for any computer claiming to compete with human intelligence. A digital camera can take an image with a level of detail that far exceeds the human brain’s storage capacity, but that doesn’t mean it can turn millions of pixels into one coherent story. The way the brain can process data and integrate it into a narrative is something we are far from understanding, let alone replicating in our silicon friends.
Why is it that when we receive the information that comes in through our senses we can condense it into an integrated experience? We don’t experience the redness of a die and its cubeness as two different experiences. They are fused into a single experience. Replicating this fusion has been one of the challenges in getting a computer to interpret an image. Reading an image one pixel at a time won’t tell us much about the overall picture. To illustrate this more immediately, take a piece of paper and make a small hole in it. Now place the paper on an A4 image of a face. It’s almost impossible to tell whose face it is by moving the hole around.
Five years ago this challenge still seemed impossible. But that was before the advent of machine learning. Computer programmers in the past would try to create a top-down algorithm to recognise visual images. But coming up with an ‘if …, then …’ set to identify an image never worked. The bottom-up strategy, allowing the algorithm to create its own decision tree based on training data, has changed everything. The new ingredient which has made this possible is the amount of labelled visual data there is now on the web. Every Instagram picture with our comments attached provides useful data to speed up the learning.
You can test the power of these algorithms by uploading an image to Google’s vision website: https://cloud.google.com/vision/. Last year I uploaded an image of our Christmas tree and it came back with 97 per cent certainty that it was looking at a picture of a Christmas tree. This may not seem particularly earth-shattering, but it is actually very impressive. Yet it is not foolproof. After the initial wave of excitement has come the kickback of limitations. Take, for instance, the algorithms that are now being trialled by the British Metropolitan Police to pick up images of child pornography online. At the moment they are getting very confused by images of deserts.
‘Sometimes it comes up with a desert and it thinks it’s an indecent image or pornography,’ Mark Stokes, the department’s head of digital and electronics forensics, admitted in a recent interview. ‘For some reason, lots of people have screen-savers of deserts and it picks it up, thinking it is skin colour.’ The contours of the dunes also seem to correspond to shapes the algorithms pick up as curvaceous naked body parts.
There have been many colourful demonstrations of the strange ways in which computer vision can be hacked to make the algorithm think it’s seeing something that isn’t there. LabSix, an independent student-run AI research group composed of MIT graduates and undergraduates, managed to confuse vision recognition algorithms into thinking that a 3D model of a turtle was in fact a gun. It didn’t matter at what angle you held the turtle – you could even put it in an environment in which you’d expect to see turtles and not guns.
The way they tricked the algorithm was by layering a texture on top of the turtle that to the human eye appeared to be turtle shell and skin but was cleverly built out of images of rifles. The images of the rifle are gradually changed over and over again until a human can’t see the rifle any more. The computer, however, still discerns the information about the rifle even when they are perturbed, and this ranks higher in its attempts to classify the object than the turtle on which it is printed. Algorithms have also been tricked into interpreting an image of a cat as a plate of guacamole, but LabSix’s contribution is that it doesn’t matter at what angle you showed the turtle, the algorithm will always be convinced it is looking at a rifle.
The same team has also shown that an image of a dog that gradually transforms pixel by pixel into two skiers on the slopes will still be classified as a dog even when the dog had completely disappeared from the screen. Their hack was all the more impressive, given that the algorithm being used was a complete black box to the hackers. They didn’t know how the image was being decoded but still managed to fool the algorithm.
Researchers at Google went one step further and created images that are so interesting to the algorithm that it will ignore whatever else is in the picture, exploiting the fact that algorithms prioritise pixels they regard as important to classifying the image. If an algorithm is trying to recognise a face, it will ignore most of the background pixels: the sky, the grass, the trees, etc. The Google team created psychedelic patches of colour that totally took over and hijacked the algorithm so that while it could generally recognise a picture of a banana, when the psychedelic patch was introduced the banana disappeared from its sight. These patches can be made to register as arbitrary images, like a toaster. Whatever picture the algorithm is shown, once the patch is introduced it will think it is seeing a toaster. It’s a bit like the way a dog can become totally distracted by a ball until everything else disappears from its conscious world and all it can see and think is ‘ball’. Most previous attacks needed to know something about the image it was trying to misclassify, but this new patch had the virtue of working regardless of the image it was seeking to disrupt.
Конец ознакомительного фрагмента.
Текст предоставлен ООО «ЛитРес».
Прочитайте эту книгу целиком, купив полную легальную версию на ЛитРес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.


