


Полная версия
Новое SEO-2.0 без ключевых слов. Как вывести сайт на вершину поисковой выдачи?
когда человек вводит или произносит запрос, он или она пытается что-то сделать. Назовём эту цель намерением пользователя. Намерение пользователя:
стандарт: все запросы имеют языковой стандарт, то есть язык и страна для решения определенной задачи. Страны представлены двухбуквенным кодом страны, например, «Россия» в локали «ru». Иногда место выполнения задачи называют локалью. Языковой
: иногда предоставляется более конкретная информация о местоположении ищущего человека, обычно это город или район. Местоположение пользователя
страница, которую поисковая система показывает после того, как пользователь вводит запрос в поле поиска. SERP состоит из . Страница результатов поисковой системы (SERP): различных блоков результатов
для сокращения будем использовать слово «результат» для обозначения блока результатов и целевой страницы. Блок результата:
· Блок результатов: это отдельный «блок», который появляется на устройстве пользователя в ответ на запрос. Блок результатов может отображать информацию в самом блоке или содержать ссылки, или может выполнять и то, и другое.
· Целевая страница (LP) – это страница, которую вы видите после нажатия ссылки в блоке результатов.
Как подготовиться к анализу?
Перед изучением этой подготовки вспомните главу «10 причин, по которым результаты поиска Google сильно различаются».
Требования к браузеру
Вы можете использовать полезные надстройки или расширения браузера, но, пожалуйста, не используйте надстройки или расширения, которые мешают или изменяют работу пользователя со страницей. При сканировании страницы поисковиками с веб-страницы снимается всё что на ней имеется. Всякие же надстройки обозревателя, которые могут помогать пользователю улучшить восприятие контента должны быть отключены.
Расширения для блокировки рекламы
Не используйте надстройки или расширения, которые блокируют рекламу для оценки соответствия требованиям или оценки качества страницы. Эти надстройки или расширения могут привести к тому, что вы получите неправильные оценки. Дело в том, что поисковики наказывают сайты за избыточное количество рекламы, а у пользователей реклама может вызывать отрицательные эмоции, а это, ваши исследование сайта, может пропустить. Так вы не получите объективную оценку сайта и его страницам.
Информация о безопасности в Интернете
Выполняя анализ, вы посетите множество различных веб-страниц. Некоторые из них могут нанести вред вашему компьютеру, если вы не будете осторожны. Не загружайте исполняемые файлы, приложения или другие потенциально опасные файлы и не переходите по ссылкам, которые вам неудобны.
Настоятельно рекомендуется, чтобы на вашем компьютере была установлена антивирусная и антишпионская защита. Это программное обеспечение необходимо часто обновлять, иначе ваш компьютер не будет защищен. В Интернете доступно множество бесплатных и платных антивирусных и антишпионских продуктов. Не стесняйтесь ими пользоваться.
Предлагаем открывать только те файлы, с которыми вам удобно работать. Перечисленные ниже форматы файлов обычно считаются безопасными, если установлено антивирусное программное обеспечение.
●.txt (текстовый файл);
●.ppt или. pptx (Microsoft PowerPoint);
●.doc или. docx (Microsoft Word);
●.xls или. xlsx (Microsoft Excel);
● файлы. pdf (PDF).
Если вы столкнулись со страницей с предупреждающим сообщением, например «Предупреждение – посещение этого веб-сайта может нанести вред вашему компьютеру», или если ваше антивирусное программное обеспечение предупреждает вас о странице, вам не следует пытаться посетить эту страницу, чтобы оценить её. Если такая страница оказалась на первой странице результатов поиска, то она скоро покинет ее, и в лучшем случае надолго.
Понимание запросов пользователей и результатов поиска
Почему люди ищут в Интернете?
Люди используют поисковые системы в Интернете для выполнения множества различных задач в различных средах с использованием различных типов устройств, таких как мобильные телефоны, планшеты, ноутбуки или компьютеры. Имейте ввиду, что поиск может быть простым или сложным, а базовая задача, которую пытается выполнить человек, может выполняться в несколько шагов.
Например, простой задачей может быть поиск режиссера фильма.
Сложная задача может состоять в том, чтобы найти ближайший сеанс, купить билеты и проложить маршрут до кинотеатра. В целом, поисковые системы должны облегчать людям выполнение задач, сразу же выдавая полезные результаты.
В далёкие времена пользователи вводили определенные слова, чтобы увидеть эти слова в результатах поиска. Но оптимизаторы сайтов стали злоупотреблять этими словами, и напихивали их, чтобы быть на вершине поиска.
Потом поисковики стали регламентировать количество упоминаний ключевой фразы в тексте на основании высококачественных текстов. Это число составляло от 3 до 7%.
В последние годы произошла революция в поисковой выдаче. Поисковики воспринимают введенные или озвученные фразы как вопрос, на который пользователь желает получить ответ.
Понимание запроса – это стремление понимать, чего желает получить пользователь. Помните, что запрос – это то, что пользователь вводит или говорит на своем устройстве.
Подумайте, для начала, о пользователях в вашем регионе, которые набирают или произносят следующие запросы в свой телефон. И что они предполагают увидеть.
Запрос
[население Пекина],
Вероятное намерение пользователя
Пользователь желает узнать сколько человек сейчас проживает в Пекине, Китай.
Более сложный
Запрос
[пятерка рядом со мной],
Вероятное намерение пользователя
Найдите ближайший магазин Пятерочка рядом с местом нахождения пользователя.
Заметьте,
что поисковики понимают, что пользователь ищет магазин пятерочка рядом с его местоположением. А в самом запросе пользователя нет ни одного слова, которое бы фигурировало на искомой веб-странице.
Запрос
[погода],
Вероятное намерение пользователя
Найти информацию о погоде в местоположении пользователя прямо сейчас.
Заметьте,
В запросе пользователя только одно слово, но поисковики понимают, где находится человек, и что его интересует прогноз погоды здесь и сейчас.
Как видите, в намерениях пользователя набранные слова не всегда подразумевают слова в желаемом ответе. Но поисковики понимают по набранным словам какую информацию желает получить пользователь. В Google за понимание текстов в основном отвечают алгоритмы: RankBrain, Google BERT, PASSAGE RANKING, Google MUM.
Далее на примере их работы рассмотрим, как искусственный интеллект помогает пользователям находить желаемую информацию.
Как понимаете, теперь SEO оптимизация – это не набор ключевых фраз, повторенных несколько раз, а полезный контент, который приятно читать, и получать желаемую информацию конечному пользователю.
Хотя сейчас мало вероятно, но если случайно слабая статья приблизится к вершине поиска по еще не идеальным алгоритмам, то впоследствии голос пользователя поставит её на место, а алгоритм искусственного интеллекта усовершенствуется.
Голос же пользователя – это набор сигналов: время, потраченное на изучение контента, а также перейдя на веб-страницу из поиска, вернулся ли человек в поисковую систему, чтобы продлить поиск.
Искусственный интеллект уже достаточно хорошо «понимает» тексты, и достаточно точно выполняет сортировку для поисковой выдачи.
По сути искусственный интеллект уже знает, как и в каком виде пользователи желают получать информацию. По этим критериям и работают алгоритмы. Поэтому зная принцип работы, составители текстов могут использовать знания, которые предоставляет Google, и целенаправленно работать над написанием текстов, чтобы максимально удовлетворить пользователя.
Исходя из этого, на сколько возможно, предлагаю детально разобрать работу этих алгоритмов ранжирования для поисковой выдачи.
Не забывайте и о другой, не менее важности понимания алгоритмов. Просматривая контент конкурентов, вы будите понимать на что следует обращать внимание, чтобы оценить качество предоставляемых материалов.
RANKBRAIN (искусственный интеллект)
RankBrain – так назвал Google системы искусственного интеллекта с машинным обучением, которая помогает Google понять смысл запросов и предоставлять наиболее подходящие результаты поиска в ответ на эти запросы сообщило агентство Bloomberg. Это подтвердил и Google.
Машинное обучение – это компьютерная программа, которая учит саму себя.
Истинный искусственный интеллект, – это то, где компьютерная программа пополняет свою базу знаний, как от обучения, так и от накопления знаний и создания новых связей.
Чтобы у вас не было иллюзий о бескрайних возможностях искусственного интеллекта, рассмотрим простые примеры.
Классический пример, чем отличается кошка от собаки.
Как искусственный интеллект по картинке отличит кошку от собаки? Первоначально создается база из десятка тысяч изображений кошек и собак. Затем, каждое изображение делится на фрагменты:
нос, рот, уши, лапы, и т. д. и т. п.
Каждому такому фрагменту присваивается кодовое число, которое относится к группе кошек, и группе собак.
При определении кошка или собака изображены на исследуемой картинке, изображение делится на такие же фрагменты. Полученные фрагменты сравниваются с теми, что в базе, и подбираются наиболее похожие.
Из ста анализируемых фрагментов оказалось, что 89 похожи на собаку, а 11 – на кошку. Искусственный интеллект выдает решение, что это – собака.
Если искусственный интеллект определил вид животного правильно, то всем фрагментам присваивается кодовое число, данные заносятся в базу данных, и вся система этого интеллекта – обучилась.
Но не всегда проходит так гладко, поэтому перед запуском систему проходят проверку.
Если искусственный интеллект ошибся, то системе «говорят», что она ошиблась. Новые данные заносятся с правильными кодовыми числами.
В Google тестированием работы интеллекта занимаются специально обученные люди, которые проверяют работу алгоритма. Поэтому иногда можно видеть, что вдруг какой-то непонятный сайт оказался выше хороших сайтов. Но как правило это временно. Ручная проверка сайтов происходит постоянно, и в результате всегда слабые сайты занимают в конечном итоге соответствующее место.
О методики ручного тестирования сайтов, и как этот метод применить к оценке сайтов конкурентов читайте в книге «5000+ сигналов ранжирования в поисковиках». Эта книга – прекрасное руководство оценки сайтов с целью понять, что нужно сделать своему сайту, чтобы обойти конкурентов в поисковой выдаче.
Но продолжим о работе искусственного интеллекта.
Разберем еще одну несложную задачу. Предположим, что в базе данных есть сто авторов, и каждого автора имеется в базе данных по десятку книг. Требуется по тексту, или фрагменту из книги неизвестного автора определить, кто же написал этот текст. Разумеется, исследуемого фрагмента текста нет в базе данных.
Здесь в программе подготовлено, какими словами, как часто, и в каких сочетаниях пользовался каждый автор. Анализируя тестируемый текст, программа определяет, к какому автору ближе всего это сочетание. К кому ближе, того и называет эта программа.
По этому же принципу Google определяет качество текста.
Поисковик имеет базу данных слов (из самых авторитетных сайтов в этой отрасли), которые должны быть в тексте по этой теме, и ищет их в исследуемом тексте.
Чем больше совпадений, по словам, употреблённых в текстах, с самыми лучшими веб-страницами, тем выше качество исследуемой.
И ещё.
Представьте, что компьютерная программа поможет вам выбрать фильм, который понравится вам. Первоначально программа на вашем экране показывает названия всех имеющихся у неё фильмов.
Программа еще не знает ваших предпочтений, и вы отмечаете, из уже виденных фильмов какие вам не нравятся, перетягивая их в левую сторону. Те же фильмы, которые вы видели, и они вам понравились – в правую. Так фильмы условно распределяются по виртуальной шкале от не понравившихся фильмов к тем, которые понравились.
Чем больше фильмов вы расставите на виртуальной шкале, тем более точным будет предложение о новом просмотре. С каждой новой отметкой программа, самообучаясь, дает более точное предсказание.
Так и искусственный интеллект Google и других поисковиков помнит, что прежде искал пользователь, оценивает, и предлагает наиболее подходящее.
Это особенно полезно, когда пользователь вводит не конкретный запрос.
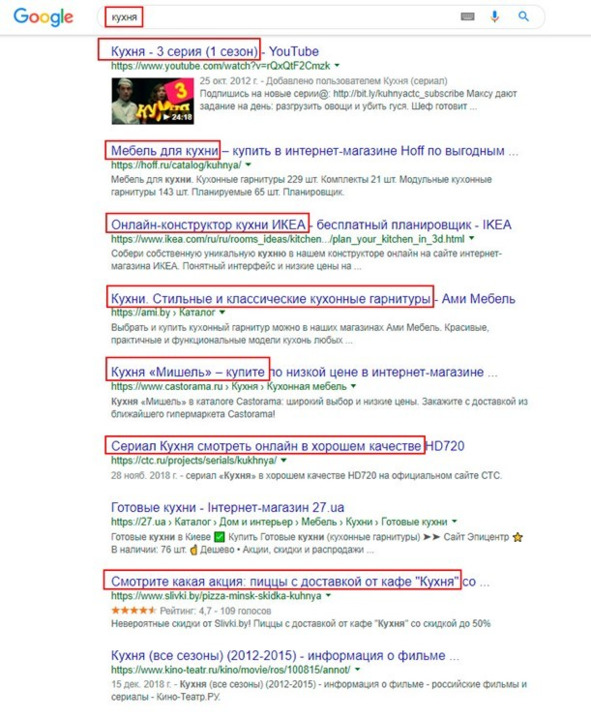
Например, пользователь в строке поиска ввел одно слово: «кухня». Что он имел ввиду?
Сериал Кухня, мебель для кухни, или кухни народов мира?
Если пользователь прежде искал сериалы, то первыми в поиске будут сериалы. Если искал рецепты, то будут – рецепты…
Сейчас уже искусственный интеллект способен, по сотни отметок нравится узнать, о вас больше, чем ваш сосед. По 200 лайкам узнает о вас больше, чем ваш (а) спутник (ца) жизни. Проанализировав 500 лайков, программа узнает о ваших предпочтениях лучше, чем вы сами. А сколько вы уже поставили лайков?
RankBrain – это часть общего поискового «алгоритма» Google, компьютерной программы, которая используется для сортировки миллиардов страниц, о которых она знает, и поиска наиболее подходящих для конкретных запросов.
RankBrain является частью алгоритма поиска Hummingbird от Google.
Hummingbird – это общий алгоритм поиска. Так же, как у автомобиля есть двигатель. Сам двигатель может состоять из различных частей, таких как масляный фильтр, топливный насос, радиатор и так далее. Так, Hummingbird включает в себя различные части, причем RankBrain является одним из новейших.
Потому что RankBrain не обрабатывает весь поиски, как это делает общий алгоритм. Он берет уже подготовленные для него сигналы, и только с ними работает.
Дэнни Салливан журналист и аналитик, который занимается исследованием в области цифрового и поискового маркетинга утверждает, что RankBrain является третьим по важности сигналом при ранжировании сайтов в ответах на запросы пользователей.
Первым пока остаются ссылки, которые Google подсчитывает в виде голосов. Яндекс же стал намного меньше выделять веса под ссылки.
Вторым сигналом он предполагает – «слова», где слова охватывают все – от слов на странице до того, как Google интерпретирует слова, которые люди вводят в окно поиска вне анализа RankBrain.
Третьим по значимости сигналам считается RankBrain, который в основном используется для интерпретации запросов. Люди вводят фразы в строку поиска, чтобы найти страницы, которые могут не содержать точных слов, которые искали.
Использование LSI-терминологии.
Например, если прежде человек в строке поиска вводил «Обувь», то Google отбирал на веб-страницах не только «Обувь», но и обуви, обувью, и подобные.
Теперь если пользователь ввел, «Обувь», то поисковик предложит и другие варианты: «туфли», «ботинки», «сапоги», «босоножки» и многое другое.
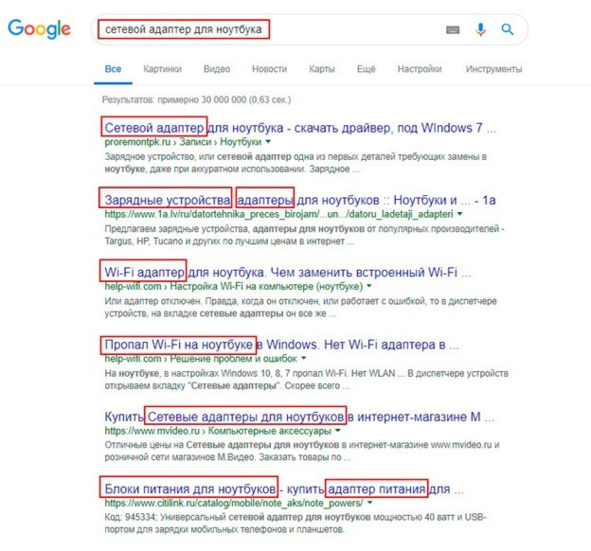
Люди часто сетевой адаптер для ноутбука называют зарядным устройством, зарядкой, и т. п. Google знает все варианты, и в результатах поиска выводит все варианты. Смотрите скриншот.
Как видите, Google понял, что пользователь хочет найти, и предложил лучшие ответы, не взирая, на введенные слова.
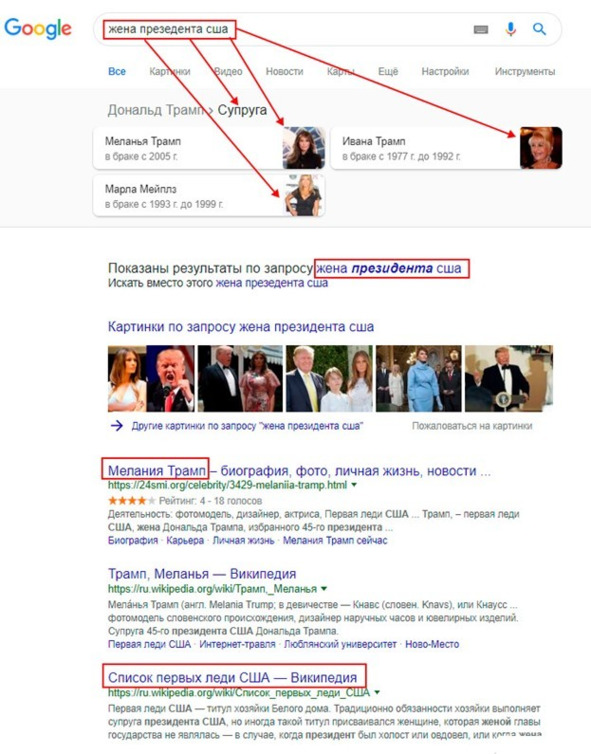
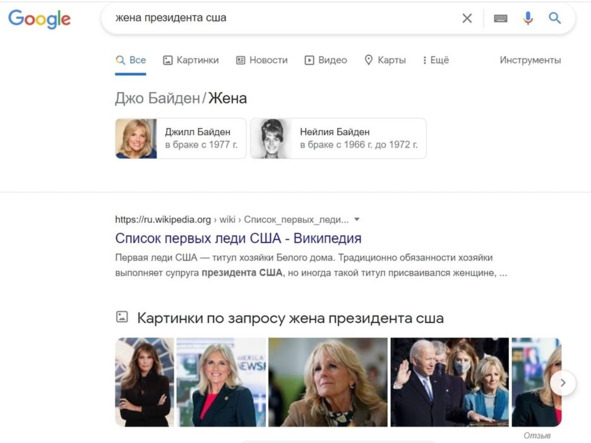
Или более интеллектуальный поиск. Я ввел фразу «жена президента сша» с ошибкой
Но Google понял, что я имел ввиду. Google знает, что жена и супруга – слова синонимы. Google предположил наиболее вероятно, что меня интересуют супруги действующего президента, и вывел их первыми. Следующим результатом показал Меланью Трамп. И только после этого вывел список первых леди США.
Прошло время после первого издания этой книги, президент поменялся, и поисковик на это правильно отреагировал.
Не правда ли, замечательная работа Google RankBrain? Так работает искусственный интеллект Google.
Как RankBrain помогает честным авторам?
Некоторое время назад одному заводу мы создавали 2 сайта: для главного завода и его филиала, территориально расположенные неподалёку друг от друга. Для главного завода главный инженер, доктор наук изъявил желание написать несколько ключевых текстов. Филиалу мы писали статьи сами. Получилось некоторое соревнование: чьи статьи Google будет позиционировать выше.
Как вы думаете, кто победил: первоклассный копирайтер, использующий во всей мощи LSI-терминологию, или доктор наук?
Победил доктор наук.
При всех равных условиях его статьи в подавляющем большинстве позиционировались первыми, а статьи копирайтера – вторыми. Почему?
Потому что доктор наук знал лучше терминологию и описываемый процесс, чем копирайтер. Доктор наук использовал большее количество синонимом, и связанных с ними слов. Правда, я лично проконсультировал главного инженера по основным положениям написания высоко ранжируемых статей, и потом мы расставили все теги и атрибуты, в соответствии с требованием поисковиков.
Поясню на примере. Предположим, нужно написать статью, в которой рассказывается о демонстрации нового фильма в кинотеатре. Google мало иметь в статье слова кинотеатр и фильм. Ему нужны и сопутствующие слова, например, билеты, аншлаг, цена, и другие слова, которые обычно употребляются в обычной речи.
Чем больше таких слов, тем Google считает, что тема раскрыта более полно.
Законный вопрос: откуда Google знает, какие синонимы, термины и сопутствующие слова соответствуют не только всей теме, но и конкретному запросу. Не забывайте, что есть искусственный интеллект, со своей первоначальной базой.
И далее в Google индексе сотни миллиардов страниц (а может и больше), и, анализируя эти страницы, искусственный интеллект постоянно пополняет эту базу данных.
Если Google видит, что с набором определенных групп слов станица пользуется у посетителей популярностью, её цитируют, то из таких страниц и выбираются дополнительно LSI-фразы, и пополняют базу данных.
Более сложный процесс ранжирования сайтов, когда длинный запрос (такие запросы называются запросами с длинным хвостом), и никогда прежде не вводился.
Проблема в том, что Google обрабатывает почти четыре миллиарда запросов в день. В 2007 году Google заявил, что до 25 процентов этих запросов никогда раньше не видел. В 2013 году эта цифра снизилась до 15 процентов, о чем сообщал Bloomberg, и Google подтвердил это. А к концу 2021 года таких запросов осталось 13%.
Но 13 процентов из 4 миллиардов – это по-прежнему огромное количество запросов, которые никогда не вводил ни один человек. Это почти пол миллиарда новых запросов в день.
Среди них могут быть сложные запросы, состоящие из нескольких слов, которые также называются «длинными хвостами».
RankBrain разработан, чтобы помочь лучше интерпретировать эти запросы, чтобы найти лучшие страницы для поисковика.
Как утверждает Google, он может улавливать закономерности между, казалось бы, не связанными сложными запросами, чтобы понимать, насколько они на самом деле похожи друг на друга. Это самообучающая программа, в свою очередь, позволяет лучше понять будущие сложные поиски, и их связь с конкретными темами. Самое главное, исходя из того, что Google сообщил нам, он может затем связать эти группы поиска с результатами, которые, по его мнению, понравятся пользователям.
Google не предоставляет примеры групп поиска и не даёт подробных сведений о том, как RankBrain угадывает, какие страницы являются лучшими. Но последнее, вероятно, объясняется тем, что, если он может перевести неоднозначный поиск во что-то более конкретное, он может затем ранжировать и выводить лучшие ответы.
Я сделал такое длинное описание, что бы было понятно, что какой-то прыщавый копирайтер не получит высокой оценки за свою работу после анализа его статьи Google RankBrain, если в ранжировании учувствуют специалисты из области, в которой мальчик написал статью.
Но хорошо подготовленный специалист в своей статье раскроет тему так, что его статья будет высоко позиционироваться по нескольким ключевым фразам. Google RankBrain, как хороший специалист видит уровень написанного текста. Да он не понимает текст, а поэтому прыщавый копирайтер уже не может навешать ему лапшу на уши.
Алгоритм Google BERT
BERT: Сравнительно новый алгоритм Google, который обещает революцию в поисковой выдаче
Google уже стал настолько сложной частью жизни людей, что многие из нас общаются непосредственно с ним.
Пользователи делают запросы: «как мне попасть на рынок» или «когда начнется весна», как будто они естественно разговаривают с человеком. Но стоит помнить: Google состоит из алгоритмов, которые упакованы в фильтры.
И это один из тех алгоритмов – Google BERT – который помогает поисковой системе понять, о чем просят люди, и дает ответы, которые они хотят.
Правильно: боты не люди, но технологии настолько продвинулись вперед, что могут понимать человеческий язык, включая сленг, ошибки, синонимы и языковые выражения, присутствующие в нашей речи, а мы даже не замечаем.
Этот новый поисковый алгоритм был создан Google, чтобы лучше понимать поисковые намерения пользователей и содержание веб-страниц.
Но как это работает? И как это влияет на ваши стратегии SEO?
Давайте все сейчас разберемся:
Что такое Google BERT?
Google BERT – это алгоритм, который улучшает понимание человеческого языка поисковой системой.
Это важно во вселенной поиска, поскольку люди спонтанно выражают себя в поисковых запросах и содержании страниц, а Google работает над тем, чтобы найти правильное соответствие между одним и другим.
BERT – это аббревиатура от Bidirectional Encoder Representations from Transformers (двунаправленных представлений кодировщика от трансформеров). Сбивает с толку? Давайте объясним это лучше!
Чтобы понять, что такое BERT, нам нужно разобраться с некоторыми техническими терминами, хорошо?
Во-первых, BERT – это нейронная сеть.
Вы знаете, что это такое?
Нейронные сети – это компьютерные модели, вдохновленные центральной нервной системой животных, которые могут обучаться и распознавать закономерности. Они являются частью машинного обучения.
В случае BERT нейронная сеть способна изучать формы выражения человеческого языка. Он основан на модели обработки естественного языка (NLP), называемой Transformer, которая понимает отношения между словами в предложении, а не просматривает их по очереди.
BERT – это предобучающая модель обработки естественного языка. Это означает, что набор данных модели обучается в текстовом корпусе (например, в Википедии) и может использоваться для разработки различных систем.
Например, можно разработать алгоритмы, ориентированные на анализ вопросов, ответов или настроений.
Все это находится в области искусственного интеллекта. То есть все делают боты!
После программирования алгоритм непрерывно изучает человеческий язык, обрабатывая миллионы получаемых данных.
Но помимо мира искусственного интеллекта, который больше похож на научную фантастику, важно знать, что BERT понимает весь контекст слова – термины, которые идут до и после, и отношения между ними – что чрезвычайно полезно для понимания содержания сайтов и намерения пользователей при поиске в Google.
Когда был выпущен BERT?
В ноябре 2018 года Google запустила BERT с открытым исходным кодом на платформе GitHub.
С этого момента каждый может использовать предварительно обученные коды и шаблоны BERT для быстрого создания собственной системы.
Сам Google использовал BERT в своей поисковой системе. В октябре 2019 года Google объявил о своем самом большом обновлении за последнее время: внедрении BERT в алгоритм поиска на английском языке.
Google уже принял модели для понимания человеческого языка, но это обновление было объявлено одним из самых значительных скачков в истории поисковых систем.







