

 полная версия
полная версияМоделирование рассуждений. Опыт анализа мыслительных актов
Но в любом случае остается проблема выбора продукции из готового фронта. Психологов весьма интересует вопрос, как это делают люди. К сожалению, однозначного ответа на этот вопрос пока нет. При экспериментах с программой «Логик-теоретик» ее авторы проводили сравнение работы программы с тем, как ведут себя в многочисленных возникающих по ходу доказательства случаях альтернативного выбора люди. В частности, последовательность, в которой перечислены различия в формулах, используемая для выбора преобразований в программе «Логик-теоретик», отражает экспериментально наблюдаемые приоритеты, демонстрируемые людьми.
Отсутствие точных психологических данных о способах выбора продукций из фронта людьми привело к тому, что в интеллектуальных системах стали использовать эвристические соображения, которые могут и не отражать особенности человеческих рассуждений. Так, весьма популярной стратегией выбора является принцип «стопки книг». Этот принцип описывает процедуру наиболее быстрого (в среднем) способа поиска нужной книги в стопке книг. Если каждый раз, использовав некоторую книгу, класть ее в стопку сверху, то часто используемые книги постепенно сосредоточатся в ее верхней части, а внизу будут лежать те, которые почти никогда не требовались. Если при поиске очередной нужной книги начинать просмотр стопки сверху, то она, как правило, встретится довольно скоро. Если продукции во фронте будут упорядочены по частоте их предшествующего успешного использования и активизироваться будет первая продукция этого фронта, то принцип стопки книг будет реализован.
У этого принципа есть определенный аналог в процедурах работы с информацией у человека. Если потребовать от испытуемых «не задумываться», говорить первое, что «приходит в голову», то на просьбу «Назовите поэта XIX века», как правило, будет дан ответ «Пушкин», а на просьбу «Назовите плодовое дерево» в подавляющем большинстве случаев ответ «Яблоня». Это, конечно, справедливо для испытуемых, живущих в средней полосе СССР. В других местах и социо-культурах возникнут свои приоритетные ответы. Человек как бы всегда имеет наготове, «на языке», подходящие отклики на часто встречающиеся ситуации.
Другой эвристический прием, заставляющий вспомнить герменевтические рассуждения, состоит в проверке в первую очередь продукции с самым длинным условием А. Такой прием обосновывается принципом «частное важнее общего» или «исключение важнее правил».
Но такие априорные внешние способы задания продукций, выбираемых из фронта, не всегда оправданы. В большинстве случаев тот или иной выбор зависит от текущего состояния базы знаний dt и того реального набора продукций, который образует в этот момент времени фронт. Для описания выбора при таких условиях в интеллектуальных системах часто используют так называемые метапродукции. Они вводятся в систему продукций специально для того, чтобы осуществлять приоритетный выбор тех или иных продукций из фронта в зависимости от предыстории развития процесса рассуждений, состава фронта и состояния базы знаний. Вот пример такой метапродукции, используемой в американской экспертной системе MYCIN – TEIRESIAS, диагностирующей инфекционные заболевания.

Мы специально не расшифровываем латинские термины, так как они совершенно не мешают понять суть работы метапродукции в данной экспертной системе.
Довольно часто возможность применения той или иной продукции зависит не только от того, какие именно продукции входят во фронт (как в только что приведенном примере метапродукции), но и от того, какие продукции в этот фронт не вошли. Другими словами, влияние может оказывать как «положительный», так и «отрицательный» контекст, в котором происходит выбор продукции из фронта готовых продукций.
Когда имеется выбор из нескольких продукций, то их можно выполнять последовательно, альтернативно или параллельно. Если считать, что в период реализации продукций из фронта время как бы останавливается (т.е. сохраняется неизменной база знаний со своим состоянием di), а влияния действий продукций друг на друга нейтрализуются тем, что все они работают в автономных участках памяти, не искажая информации в базе знаний, то порядок их выполнения роли не играет. Лишь после реализации всех продукций надо выбрать те из них, которые сформируют новый фронт (с учетом их возможного взаимодействия). Однако и эта задача оказывается весьма непростой и требует каких-то эвристических соображений.
Другой проблемой управления реализацией системы продукций является поиск наиболее эффективных способов проверки выполнения условий А в множестве продукций на текущем состоянии базы знаний di. При большой базе знаний эта переборная процедура весьма неэффективна. Каков аналог данного процесса у человека?
У психологов бытует термин «поле активного внимания». В это поле попадает та часть хранимой в памяти человека информации, которая обусловливает его текущие размышления или рассуждения. Как бы лучом прожектора эта информация выхватывается из огромного хранилища всевозможных знаний. Поле активного внимания скользит по памяти, не всегда подчиняясь нашему желанию. Как порой мучительно трудно выудить нужную информацию (например, вспомнить фамилию человека, лицо которого вам явно знакомо), как, отчаявшись, мы перестаем об этом думать, а оно «само, без видимых усилий» как бы всплывает из темных, неосвещенных глубин памяти.
Нечто аналогичное применяют специалисты в области баз знаний, вводя механизм окна активизации знаний. С помощью этого «окна» активизируются определенные фрагменты базы знаний. Эти фрагменты используются для проверки условий в продукциях. Для вычленения фрагментов удобно воспользоваться условиями Р, активизирующими ту область продукционной системы, которая оказывается тесно связанной с фрагментом знаний, попавшим в окно активизации знаний. Постусловия позволяют управлять перемещением окна по полю памяти, а также его размерами. Управлять «окном» могут и специальные метапродукции, подобные тем, которые используются для приоритетного выбора из фронта готовых продукций.
Мы рассматривали до сих пор лишь такие продукции, в которых В обязательно следовало при активизации продукции. Однако весьма часто продукции приходится использовать в условиях правдоподобного вывода. Собственно говоря, правдоподобные схемы рассуждений из четвертой главы уже демонстрируют продукции такого сорта. Тем не менее, приведем еще один пример, взяв его из уже упоминавшейся экспертной системы MYCIN. Поскольку в ряде случаев система не может выдать рекомендацию со стопроцентной уверенностью, то она выдает ее с оценкой правдоподобности, о которой мы говорили в предшествующей главе.

При работе с правдоподобными продукциями применяются приемы, аналогичные описанным в четвертой главе. Вместо числового значения оценки правдоподобия в таких продукциях могут встречаться нечеткие квантификаторы, как в D-силлогизмах.
Кроме обычных приемов вывода (как достоверного, так и правдоподобного) для систем продукций могут использоваться и иные способы получения результатов рассуждений. Один из них – это получающий в последнее время распространение вывод на семантической сети.
Вывод на семантической сети
Семантические сети – это наиболее общая модель представления знаний об окружающем интеллектуальную систему мире и способах действий в нем. В самом общем виде семантическая сеть есть множество вершин, каждая из которых соответствует определенному понятию, факту, явлению или процессу, а между вершинами заданы различные отношения, изображаемые дугами. Дуги снабжены именами или описаниями, задающими семантику отношений. Вершины также помечены именами или описаниями, содержащими нужную для понимания семантики вершины информацию.
Прибегнем, как всегда, к наглядному примеру. Известный роман Э. Хемингуэя «Острова в океане» начинается так:
«Дом был построен на самом высоком месте узкой косы между гаванью и открытым морем. Построен он был прочно, как корабль, и выдержал три урагана. Его защищали от солнца высокие кокосовые пальмы, пригнутые пассатами, а с океанской стороны крутой спуск вел прямо от двери к белому песчаному пляжу, который омывался Гольфстримом».
Попробуем отобразить информацию, содержащуюся в этом отрывке, в виде семантической сети. Введем систему понятий, которым для удобства присвоим имена по первым буквам соответствующего слова текста: Д – дом, СВМ – самое высокое место, К – коса, Г – гавань, ОМ – открытое море, КП – кокосовые пальмы, С – солнце, КС – крутой спуск, ДВ – дверь, П – пляж, Г – Гольфстрим. Теперь будем постепенно строить семантическую сеть, вводя нужные отношения и описания. На рис. 33, а показан фрагмент семантической сети, соответствующей первым двум фразам текста. Отношение R1 есть тернарное отношение «быть между». Двойная дужка на нашем рисунке объединяет между собой обе части этого соотношения. «Узкая» входит в описание понятия «коса». Отношение R2 есть отношение «принадлежать». Таким образом фиксируется тот факт, что СВМ принадлежит «косе». Отношение R3 интерпретируется как «находиться на», а текст около вершины, соответствующей понятию «дом», принадлежит описанию этой вершины. На рис. 33, б показан фрагмент сети, соответствующий остальной части текста. Отношения, использованные здесь, интерпретируются следующим образом: R4 – «защищать от», R5 – «соединять», R6 – «омывать». Полное описание текста в виде семантической сети получится, если в построенных двух фрагментах объединить вершины, соответствующие понятию «дом».
Рис. 33.
При переходе имеется определенный произвол в представлении текста, касающийся формирования описаний. Те или иные сведения можно отражать прямо в структуре сети, а можно и в описаниях. Например, в нашем случае не было введено понятие «ураган» или понятие «пассат». Сведения о них содержатся в описаниях. Но можно было бы ввести для них специальные вершины и отразить эти понятия в структуре семантической сети.
В зависимости от того, какую смысловую нагрузку несут отношения в семантической сети, их можно классифицировать по различным типам. Если они, например, отражают каузальные отношения, то мы имеем дело с семантическими сетями, называемыми сценариями, а если эти отношения отражают связи по включению (родовидовые, отношения «состоять из», отношения «элемент-класс» и т.п.), то такие семантические сети будут задавать классификации. Если же, наконец, интерпретация отношений в сети такова, что они связывают между собой аргументы и значения функции, вычисляемые при задании значений аргументов, то такие семантические сети принято называть вычислительными моделями. В последнем разделе третьей главы мы также говорили о семантических сетях, выделив из них тот класс сетей, который связан с задачей вывода. Именно о таких сетях и будем говорить далее, а интересующихся аппаратом семантических сетей в более широком объеме отсылаем к источникам, которые указаны в комментарии к последнему разделу третьей главы.
Вывод на семантической сети можно представить в продукционной системе, в которой каждая продукция имеет вид Fr1
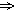
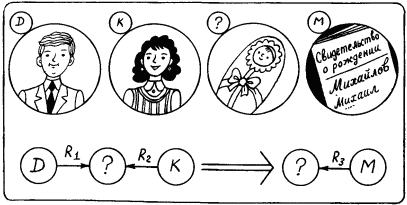
Рис. 34.
На рис. 34 показана такая продукция. Знак вопроса означает, что в качестве имени вершины может выступать любое из тех, которые имеются в базе знаний. Но если знак вопроса заменен какой-то вершиной, то в правой части продукции появляется такое же имя. Исходное состояние базы знаний показано на рис. 35, а. Для облегчения дальнейших рассуждений будем считать, что вершины семантической сети соответствуют некоторым персонажам, отношение R1 имеет смысл «быть отцом», отношение R2 – «быть матерью», а отношение R3 – «носить фамилию». Тогда продукция, показанная на рис. 34, может интерпретироваться следующим образом: «Если в базе знаний есть сведения о детях, для которых D является отцом, а К – матерью, то эту информацию из базы надо убрать, добавив в нее информацию о том, что все эти дети носят фамилию М».
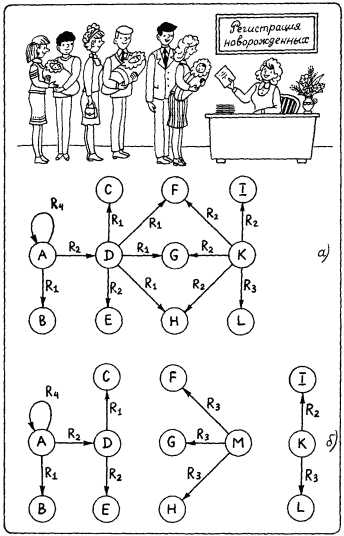
Рис. 35.
Обработка продукции идет следующим образом. В семантической сети, показанной на рис. 35, а, ищутся вершины с именами D1 и К. Если таких вершин (или одной из них) в базе нет, то поиск прекращается и выдается сигнал о неудаче поиска. Если вершины найдены, то из вершины D возбуждаются все отношения с именем R1, а из вершины К – все отношения с именем R2. Так возникают две волны возбуждения. Первая волна возбуждает вершины С, F, G и H, а вторая – вершины F, G, Н и I. Волны встречаются лишь в вершинах F, G и H. В вершинах C и I возбуждение угасает. На замещение знака «?» в продукции претендуют вершины с именами F, G и H. Эти же имена возникают в правой стороне продукции. На рис. 35, б показано результирующее состояние базы знаний после того, как продукция завершила свою работу.
В более сложно организованных образцах для поиска могут присутствовать условия применимости продукций, о которых говорилось при обсуждении общей формы продукции. Например, образец мог бы иметь вид «Если имеет место Fr1, то Fr2, иначе Fr3». Образцы такого типа задают альтернативные выводы в базах знаний. О них упоминалось в конце третьей главы.
Если при выводе на семантической сети фрагмент Fr2 добавляется в базу знаний без выбрасывания Fr1, то говорят о процедурах пополнения знаний. Человек в своей жизнедеятельности часто выполняет подобные процедуры, используя те знания о закономерностях внешнего мира, которые ему известны. Если, например, имеется текст «Поезд подошел к перрону. Через несколько минут Андрей уже обнимал Татьяну. Такси быстро домчало их до дома, и Татьяна почувствовала, что длительное путешествие ушло в прошлое», то человеку весьма нетрудно пополнить его событиями, которые в явном виде в этом тексте отсутствуют. Ясно, например, что между событием, описанным в первом предложении, и тем, которое зафиксировано как второе, имеется пропуск. Второе событие произойдет, если Андрей и Татьяна окажутся в одном месте. Один из них должен был войти в вагон или другой – выйти из вагона. (При чтении текста последовательно пока неясно, кто приехал и кто ожидал на перроне.) Поэтому восстановление пропущенных событий напоминает вывод с некоторыми оценками правдоподобия. Третье событие, зафиксированное в тексте, не может непосредственно следовать за вторым. Для его реализации надо, чтобы Андрей и Татьяна сели в такси, а если предположить, что Андрей обнимал Татьяну на перроне (что весьма правдоподобно), то надо было еще дойти до места посадки в такси. Наконец, четвертое событие, связанное с ощущением, охватившим Татьяну, увеличивает правдоподобность того, что из путешествия вернулась именно Татьяна, а не Андрей (хотя стопроцентно этого утверждать на основании текста нельзя). Кроме того, либо время четвертого события совпадает с временем третьего события, либо четвертое событие происходит позже третьего, когда Татьяна уже вышла из такси, а возможно, и вошла в свой дом.
Читатель должен почувствовать, что пополнение знаний – процедура весьма непростая. Приведенный простенький пример уже продемонстрировал необходимость в альтернативном выборе при пополнении, а также в правдоподобных рассуждениях.
Но самое главное – этот альтернативный выбор может оказаться источником всевозможных неверных выводов при дальнейшей работе с базой знаний.
Остановимся лишь на одном случае такой опасности, который среди специалистов по интеллектуальным системам получил название эффекта немонотонных рассуждений. Поясним его на популярном примере. До того, как европейцы узнали, что в Таиланде водятся белые слоны (так называемые королевские слоны), они были уверены, что все слоны серые. Это означало, что в модели знаний о слонах имел место фрагмент, показанный на рис. 36, а. В этом фрагменте R есть отношение, a Q – отношение «быть серого цвета». Если Тони – имя некоторого конкретного слона, то из информации, отраженной в данном фрагменте знаний, следует, что «Тони имеет серый цвет». Но при условии, что слон Клайд является королевским, для него такой вывод будет неверным. Это означает, что при появлении нового знания о том, что «Клайд – королевский слон», ранее сделанный относительно него вывод «Клайд имеет серый цвет» становится ложным. В этом и состоит немонотонность вывода.
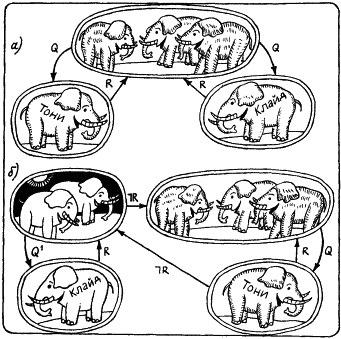
Рис. 36.
В обычной логике вывод всегда бывает монотонным. Если из множества утверждений {Fi} следует утверждение F*, то как бы ни расширилось множество {Fi}, истинность утверждения F* не может измениться. А у нас имеется прямо противоположная ситуация. Появление нового утверждения «Клайд – королевский слон» отменяет истинность утверждения «Клайд имеет серый цвет».
На рис. 36, б показана семантическая сеть, в которой учтен новый факт, касающийся королевских слонов. Дуга

Возможность неоднозначного доопределения сетей, хранящихся в памяти, приводит к тому, что после доопределения выводиться могут различные утверждения, зависящие от сделанного пополнения. Поэтому проблема пополнения непроста. Поэтому переход к построению выводов, опирающихся на знания (а именно они активно используются в современных интеллектуальных системах), вызывает к жизни многие новые и не совсем привычные для традиционных логиков проблемы.
Спрашивай – Отвечаем
Одним из нетрадиционных видов человеческих рассуждений (нетрадиционных для классической логики, а не для человека) является поиск ответа на вопрос. Развитие баз знаний стимулировало интерес к тому, как могут формулироваться запросы к хранящейся в них информации и как могут формироваться ответы на эти вопросы. Другими словами, внимание логиков стали привлекать процедуры построения вопросно-ответных отношений.
Давно известно, что правильно сформулированный вопрос во многом содержит в себе информацию о возможном ответе на него. Но остается неясным, что значит «правильно сформулированный». В рассказе известного американского писателя-фантаста Р. Шекли «Верный вопрос» эта проблема находится в центре внимания. В рассказе говорится о поставленном в глубинах Космоса универсальном Ответчике, созданном некоторой сверхцивилизацией. Ответчик способен дать исчерпывающий ответ на любой вопрос, если он сформулирован правильно. Но оказывается, что этого никто из людей не может сделать. Все живые существа живут в мирах, которые состоят из частностей. Поясняя этот факт очередному претенденту на получение ответа, Ответчик говорит: «Положим, ты спрашиваешь: „Почему я родился под созвездием Скорпиона при проходе через Сатурн?“. „Я не сумею ответить на твой вопрос в терминах зодиака, потому что зодиак тут совершенно не при чём“». И постепенно автор рассказа приводит читателя к мысли о том, что в условиях работы Ответчика есть явный парадокс: правильно поставить вопрос можно только тогда, когда ответ на него известен.
Существует несколько типов вопросов, которые мы часто задаем другим людям или самим себе. Специалисты до сих пор не пришли к единому мнению о классификации всех возможных вопросов. Условно их пока делят на шесть типов в зависимости от того, какие процедуры требуются при ответе на них.
1. ЧТО-вопросы. Это вопросы типа «Что ты знаешь о сотруднике Иванове?» или «Сообщи все, что тебе известно о малярии». ЧТО-вопросы для ответа на них требуют просмотра базы знаний и извлечения из нее всей информации, относящейся к тому, о чем спрашивается в вопросе. При реализации такой процедуры возникает немало сложностей. Информация в базе знаний хранится так, что между информационными единицами имеется немало разнообразных связей. Эту ситуацию мы описали, когда говорили о семантических сетях. «Вытаскивая» ответ на ЧТО-вопрос, надо решить проблему остановки, прекращения движения по связям. Надо уметь определять релевантное окружение той информации, которая является прямым ответом на поставленный вопрос.
2. ЛИ-вопросы. Такие вопросы подразумевают конечное множество альтернативных ответов при условии, что сами ответы как бы присутствуют в вопросе. Вот примеры ЛИ-вопросов: «Петя ходит в школу или он еще дошкольник?», «Что мы будем делать после обеда: отдыхать, гулять или работать в саду?», «Перестала Маша по утрам ходить на музыку?».
Для формирования ответов на ЛИ-вопросы необходима процедура проверки истинности альтернатив, перечисленных в них, и выбора той альтернативы, которая является истинной. Конечно, в базе знаний может не оказаться нужных данных. Это приводит к тому, что в качестве ответа на ЛИ-вопрос может быть выдано: «Не знаю» или «Не имею необходимой информации».
Возможен и другой крайний случай (к сожалению, весьма часто встречающийся в больших информационных системах), когда возникает известная позиция Ходжы Насреддина в разрешении спора двух сторонников взаимно исключающих альтернатив. Выслушав первого, он сказал: «Ты прав», выслушав второго он снова сказал: «Ты прав», а на замечание прохожего, что так быть не может, Насреддин сказал и ему: «Ты прав». При заполнении баз знаний (особенно из различных источников) в них одновременно могут храниться взаимоисключающие факты. При обнаружении такого положения ответ на ЛИ-вопрос должен звучать примерно так: «Однозначного ответа дать не могу, верно и одно и другое».
3. КАКОЙ-вопросы. Эти вопросы похожи на ЛИ-вопросы, но отличаются от них тем, что либо множество альтернатив является бесконечным, либо определяется не по самому вопросу, а требует выполнения специальных процедур по его нахождению. Типичными примерами КАКОЙ-вопросов могут служить: «Какие сотрудники института имеют детей в возрасте до пяти лет?» или «Какие следствия могут возникнуть из того, что министром обороны станет Д. Смит?». Ответ на первый из приведенных вопросов требует специального просмотра содержимого памяти системы, использующего атрибут «наличие детей до пяти лет». Такой поиск характерен для современных реляционных баз данных. Поэтому в литературе подобные КАКОЙ-вопросы часто называют типовыми запросами к реляционным базам данных или просто реляционными вопросами.
Ответ на второй КАКОЙ-вопрос требует не только поиска, но и процедуры логического вывода следствий из того, что в множество истинных формул в качестве посылки включается новая формула, связанная с утверждением о том, что Д. Смит является министром обороны. Как и для ЛИ-вопросов, в этом случае возможно незнание ответа или неоднозначность его. КАКОЙ-вопросы второго типа есть вопросы о следствиях из принятия некоторого факта в базу знаний, что принципиально отличает их от КАКОЙ-вопросы первого типа.