


Полная версия
SEOBOOK
Рассмотрим создание карты сайта на примере xml-sitemaps.com:
1. Вводим адрес сайта в первую строку, сразу после http:// . Выглядеть должно примерно так: http://1ps.ru/
2. Во второй строке выбираем частоту обновления страниц сайта. Возможные значения – каждый час («Hourly»), день («Daily»), раз в неделю («Weekly»), раз в месяц («Monthly»), раз в год («Yearly»). Если выбрать «None», частота обновления не будет прописана в Sitemap. Рекомендуем выбирать Weekly или Daily.
3. В третьей строке назначаем дату последнего обновления страниц сайта. Удобнее всего выбрать текущую дату, которая отражается в последнем пункте выбора.
4. Выставляем приоритет для страниц сайта: «None» – означает, что приоритет не принципиален, «Automatically Calculated Priority» – программа автоматически определит приоритетные страницы и составит карту сайта с их учётом.
5. Жмём кнопку «Start».
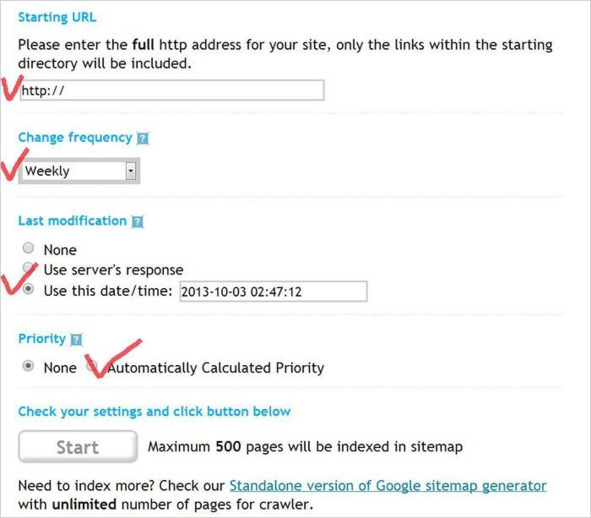
Рис.296. Создание Sitemap. xml
Генерирование карты займёт некоторое время, после появится вот такой текст:
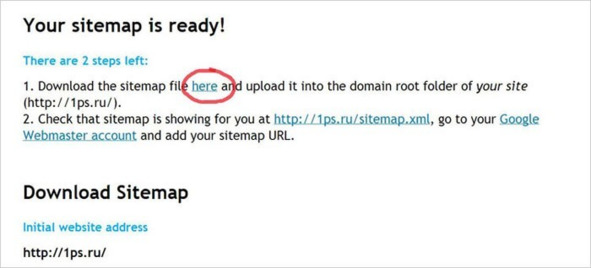
Рис.297. Создание Sitemap. xml
Он сообщает вам о том, что карта успешно создана, и всё, что вам осталось сделать, это:
1. Загрузить файл с картой в корневую директорию вашего сайта (скачать файл можно по ссылке here).
2. После размещения проверить наличие карты по адресу http://ваш_сайт/sitemap.xml, добавить её в robots.txt и в панели вебмастеров Яндекса и Гугла, чтобы поисковые роботы начали ориентироваться на неё.
Всё, дело сделано – карта xml готова! Только помните, что карта xml – для поисковых роботов. А для пользователей не помешает создать обычную карту сайта в формате HTML. Для оптимизации, кстати, она тоже лишней не будет.
5.2.3. Основное зеркало
Зеркало сайта (Mirror Site) – сайт, являющийся полной или частичной копией другого сайта (совпадение от 80%).
Зеркала обнаруживаются поисковыми роботами при анализе содержания страниц с совпадающими адресами. Чаще всего ими являются site.ru и www.site.ru – ничем не отличающиеся друг от друга страницы, на которые можно попасть по адресам с www и без.
Как правило, для человека нет разницы, зашел он на сайт www.site.ru или site.ru, httpS://site.ru или http://site.ru. Однако для поисковой системы это все – четыре разных ресурса, которые, имея абсолютно одинаковый контент, борются между собой за позиции по одним и тем же запросам. Поэтому не забывайте указывать основное зеркало сайта, которое для нового сайта можно определить самостоятельно, а для уже «опытного» ресурса лучше проверить выдачу – какое зеркало индексируется сейчас: с www или без. Такое зеркало указываем основным, а с неосновного настраиваем 301-й редирект для всех версий.
Если вам надо сделать переадресацию с сайта без www на сайт с www (или наоборот), нужно настроить SEO-редирект. Такой тип редиректа используется для настройки главного зеркала, чтобы не рассеивать усилия по продвижению на несколько доменов.
При переносе с домена с www на домен без www:
Options +FollowSymLinks
RewriteEngine On
RewriteCond %{HTTP_HOST} !^www\.(.*) [NC]
RewriteRule ^(.*)$ http://www.%1/$1 [R=301,L]
При переносе с домена без www на домен с www:
Options +FollowSymLinks
RewriteEngine On
RewriteCond %{HTTP_HOST} ^www.domain\.com$ [NC]
RewriteRule ^(.*)$ http://domain.com/$1 [R=301,L]
Важно! Перед этим кодом обязательно надо прописать правило, по которому мы исключим файл robots.txt для редиректа. Это можно сделать так:
RewriteEngine off
Это важно, потому что файл robots.txt управляет поисковыми роботами. К примеру, прописывается основное зеркало для робота Яндекса и ответ http-заголовка от данного файла должен быть HTTP/1.1 200 OK. Если правило не указать, то индексация и склейка главного зеркала будет проходить медленнее.
Также важно настроить редирект при переносе сайта на защищенный протокол с зеркал http://site.ru на httpS://site.ru. И для HTTPS также проверить зеркала httpS://www.site.ru и httpS://site.ru. Не забудьте добавить основное зеркало в панели Вебмастеров и отслеживать его показатели.
5.2.4. Дубли
В 19 пункте раздела Тексты мы уже рассказывали, что такое дубли и как их можно обнаружить на своем сайте. Сейчас наша задача понять, какими способами можно устранить дублированный контент на сайте. Существует три основных способа, чтобы обезвредить сайт от дублей:
1. 301-й редирект. Редиректы нужно настраивать не только на основное зеркало сайта, но и в принципе с дублирующихся страниц, которые могут возникать из-за особенностей CMS (например, часто главная страница сайта доступна по адресам site.ru и site.ru/index.php). Суть метода заключается в переадресации поискового робота со страницы-дубля на основную. Таким образом, робот проскакивает дубль и работает только с нужной страницей сайта. Со временем, после настройки 301-ого редиректа, страницы дублей склеиваются и выпадают из индекса.
2. Disallow в robots.txt. Файл robots.txt – своеобразная инструкция для поискового робота, в которой указано, какие страницы нужно индексировать, а какие нет. Для запрета индексации и борьбы с дублями используется директива Disallow. Здесь, как и при настройке 301-го редиректа, важно правильно прописать запрет.
3. Тег . Здесь мы указываем поисковой системе, какая страница у нас основная, предназначенная для индексации. Для этого на каждом дубле надо вписать специальный код для поискового робота , который будет содержать адрес основной страницы. Чтобы не делать подобные работы вручную, существуют специальные плагины.
Бывают такие ситуации, когда страницы с точки зрения человека не дублируют друг друга, но с точки зрения робота – увы. Например, страницы одного и того же товара, размещенного в разных категориях интернет-магазина. В таком случае Вам поможет атрибут rel="canonical" на более предпочтительный URL. Также атрибут rel="canonical" рекомендуется настраивать для страниц пагинации в каталоге интернет-магазина. Рассмотрим эти случаи подробнее далее.
5.2.5. Атрибут rel="canonical"
Канонический URL (canonical) позволяет указать поисковой системе, какая ссылка является предпочтительной для индексации. Настройкой canonical необходимо заниматься, если у вас на сайте имеются страницы с одинаковым содержанием. Ввиду особенностей CMS сайта могут автоматически создаваться страницы с одним и тем же контентом по разным адресам URL (более подробно читайте ниже). Появление подобных страниц возможно вследствие таких причин:
Если вы написали одно и то же сообщение в разных темах блога, то есть вероятность автоматического создания еще одной страницы сайта.
Например, у вас есть несколько доменов: http://article.example.com и http://blogs.example.com. И вы планируете размещать информацию сразу на обоих ресурсах. В таком случае размещаемый контент будет дублированным.
Если была обновлена структура вашего сайта, после чего URL страниц сайта могли быть изменены.
Чтобы не допустить дублирования страниц сайта в поисковой выдаче, необходимо настроить канонические URL, после чего поисковик сможет определить, какую страницу нужно индексировать. Рассмотрим причины, из-за которых важно заниматься настройкой canonical:
Если на разных страницах вашего сайта публикуется частично или полностью идентичная информация, то следует указать, какую страницу следует считать основной.
Одна и та же информация, размещенная на разных страницах, затрудняет получение статистики о данных страницах.
Как настроить канонические адреса
Рассмотрим способы настройки «канонических» URL:
Следует указать, какой URL считается основным. Сделать это можно при помощи атрибута rel=«canonical» тега link. Например, на сайте присутствует несколько страниц с идентичным содержимым. Для того чтобы задать URL https://example.com/buyingcar в качестве основного, указываем на страницах с дублируемым контентом в блоке head кода страницы тег вида . В данной ситуации вы задаете главный URL, который в дальнейшем будет использован для просмотра сообщения о покупке автомобилей. Также эта страница будет показываться в результатах поисковой выдачи. Предпочтительнее задавать адрес сайта в абсолютном виде (https://example.com/buyingcar), избегайте относительных путей (/buyingcar).
В карту сайта добавляем только канонические URL, в таком случае вы сможете сообщить поисковому роботу, какие страницы сайта вы считаете основными. При индексировании сайта поисковый робот не будет заходить на неканонические страницы, тем самым быстрее индексируя сайт.
Для различных CMS существуют различные плагины, которые позволяют настроить канонические URL, например, для WordPress можно воспользоваться Yoast SEO.
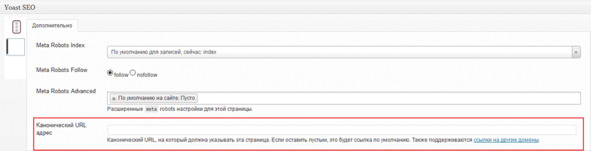
Рис.298. Настройка канонических страниц через плагин Yoast SEO
Для OpenCart настройка атрибута canonical производится средствами CMS. Необходимо зайти в настройки товара и задать параметр SEO URL.

Рис.299. Настройка канонических страниц в OpenCart
Для настройки canonical в Joomla нужно включить в настройках CMS функцию SEF. После включения для технических страниц вида /index.php? option будет добавлен атрибут rel=«canonical» (с указанием URL на страницу с настроенным ЧПУ).
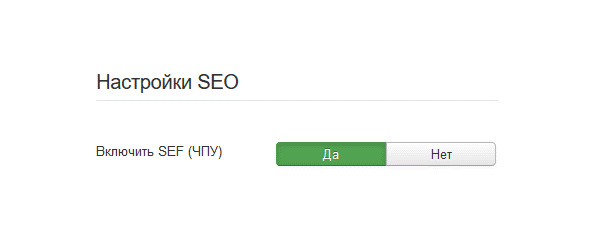
Рис.300. Настройка канонических страниц в Joomla
Как проверить дублированный контент
Проверить, настроен canonical для страниц вашего сайта или нет, можно с помощью следующих инструментов:
1. Для проверки настройки canonical, открываем html-код страницы и проверяем наличие атрибута canonical у тега link (в блоке
кода страницы).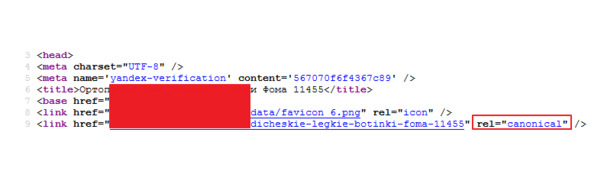
Рис.301. Проверка канонических страниц в коде сайта
2. Плагин для браузеров RDS Bar позволит просмотреть эту информацию без совершения лишних действий. Включаем данную опцию в настройках плагина (Параметры – SEO – теги – Canonical), после чего при переходе на страницы, где canonical настроен, будет отображаться следующая информация:

Рис.302. Проверка канонических страниц через RDS bar
3. Проверить наличие дублируемого контента можно с помощью Расширенного поиска Яндекса. Для этого указываем адрес сайта и часть текста со страницы, контент которой будем проверять на дублирование. В результатах поиска будет указано, нашлись точные совпадения или нет. Если дублирование отсутствует, то будут предложены варианты по запросу.
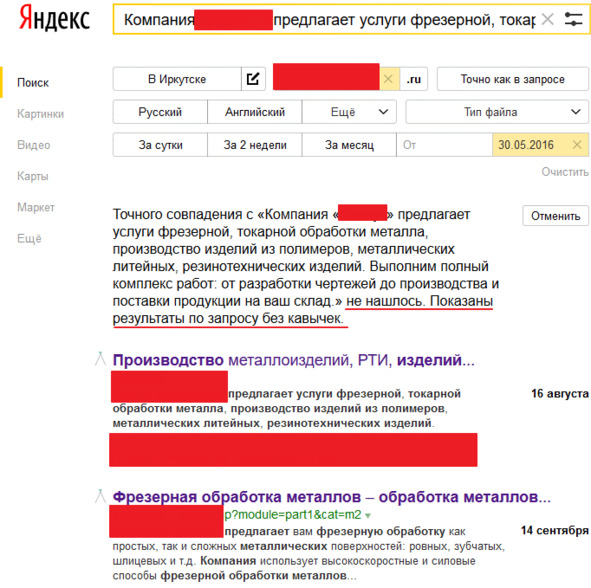
Рис.303. Проверка дублированных страниц через поиска Яндекса
4. Также проверить контент на наличие дублей можно с помощью операторов поиска, рассмотрим на примере Google. Для этого нужно ввести в поисковую строку site: имя_домена «запрос», в итоге аналогично поиску от Яндекса по результатам поисковой выдачи делаем вывод о наличии дублированного контента.
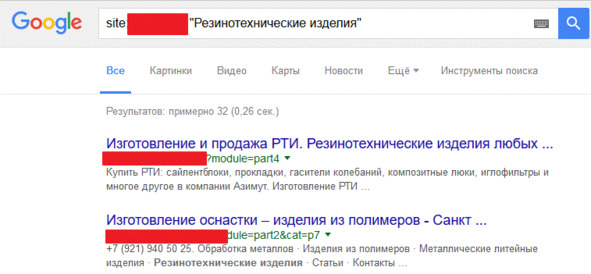
Рис.304. Проверка дублированных страниц через Google
5. Еще один способ найти дублируемый контент – уникальность. В этом нам помогут специальные программы и сервисы, мы рассмотрим на примере сервиса text.ru. Для анализа необходимо добавить информацию со страницы вашего сайта в сервис и запустить проверку. В результате вы увидите, на каких сайтах в Интернете есть такой же текст, и на сколько процентов ваш текст совпадает с текстами других сайтов.
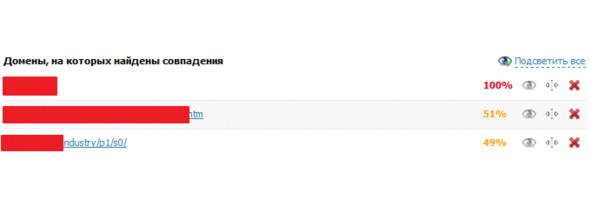
Рис.305. Проверка дублированных страниц через Text.ru
Атрибут rel="canonical" указывает роботу какая страница приоритетна для продвижения. Грамотно настроенный canonical повышает эффективность работы и ускоряет индексирование сайта.
5.2.6. Страницы пагинации
На сегодняшний день seo-оптимизаторы используют разные методы при работе со страницами пагинации. Какого-то универсального или на 100% правильного метода в данном случае быть не может – всё зависит от ресурса и целей данных страниц.
Для начала немного терминологии:
В веб-дизайне под пагинацией понимают постраничный вывод информации, показ ограниченной части информации на одной (веб)-странице.
Страницы с пагинацией – это страницы с параметрами, которые ограничивают вывод количества результатов по умолчанию. Например, 10 результатов поиска на странице или вывод 30 карточек товаров на странице категории интернет-магазина.

Рис.306. Страницы пагинации
Для чего нужна пагинация?
Пагинация способствует юзабилити сайта и упрощает его использование. Представим себе ситуацию, когда на странице каталога интернет-магазина представлен весь ассортимент, то есть десятки тысяч товаров. Технически это возможно, но насколько данная страница будет юзабильна? Будет ли пользователю удобно «работать» с данной страницей? Ответ – определенно нет. Также не стоит забывать, что скорость Интернет-соединения на данный момент ограничена, следовательно, чем больше товаров на странице, тем дольше она будет прогружаться в браузере пользователя.
Какие проблемы могут возникнуть при неправильной настройке пагинации?
Дублирование контента.
Смена релевантных страниц в поисковой выдаче.
Присутствие в выдаче нерелевантных или неактуальных страниц.
Затруднение индексирования и расход краулингового бюджета сайта.
Конец ознакомительного фрагмента.
Текст предоставлен ООО «Литрес».
Прочитайте эту книгу целиком, купив полную легальную версию на Литрес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.







