


Полная версия
SEOBOOK
Вывод: Чтобы ваш сайт не попал под алгоритмы Панда и Пингвин (равно как и под фильтры Яндекса), не переставайте следить за качеством контента на своем сайте и за качеством внешних ссылок. Не стоит покупать ссылки на биржах или заказывать тексты у сомнительных копирайтеров – такая экономия средств в настоящем может привести к потере позиций сайта в будущем – и, соответственно, к потере клиентов и вашей прибыли.
Проявите уважение к посетителям своего сайта – дайте им полезный и интересный контент. И желательно постоянно обновляемый (статьи, обзоры и прочее).
Не переусердствуйте с оптимизацией под ключевики – менее оптимизированная страница, но более ориентированная на живых людей, будет в поисковой выдаче выше просто за счет поведенческих факторов (из-за большей глубины просмотра и меньшего процента отказов).
На хороший контент будут ссылаться релевантные сайты. Особенно, если им это вовремя предложить, умелый маркетолог придумает, как это сделать.
5.1.3. Региональность
Яндекс – самый популярный поисковик в России, занимает львиную долю Рунета и лучше остальных продвинулся в формировании региональной выдачи. В апреле 2009 года Яндексом был запущен новый алгоритм Арзамас. Он начинает учитывать регион, из которого исходит запрос. Результаты выдачи по одному и тому же ключевому слову в разных городах стали разными, выделено 19 крупных регионов. Регион пользователей устанавливается через контакты на сайте и IP-хостинг провайдера. Позже, в декабре 2009, Яндекс выпустил модернизированный алгоритм Конаково – локальное ранжирование получили 1250 городов РФ.
Чтобы показать Яндексу географическую принадлежность ресурса, есть несколько способов:
1. Яндекс.Вебмастер. Зарегистрируйтесь на данном ресурсе, далее добавьте сайт и подтвердите права (как это сделать мы рассказывали в самом начале книги). Далее станет доступен весь функционал кабинета, где вы можете настроить региональную принадлежность. Выберите из меню слева Информация о сайте/Региональность.
Если регион не задан, то интерфейс будет выглядеть так:
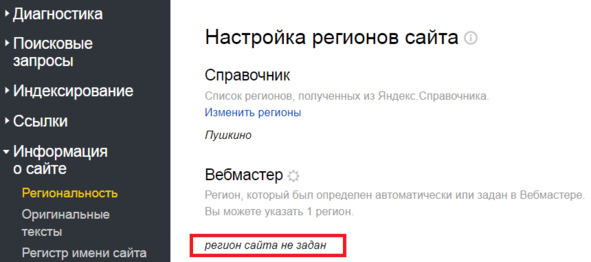
Рис.284. Пример незаданного региона сайта в Яндекс. Вебмастере
Если ресурс ориентирован на геозависимые запросы, то обязательно проследите за тем, чтобы региональность сайта была определена корректно, так как она может учитываться при определении релевантности сайта запросам из того или иного региона.
Геозависимые запросы – это ключевые слова, которые запрашиваются пользователями без употребления географических названий, но специфика запроса предполагает именно географическую привязку. Например, [заказать суши], [сделать депиляцию], [вызов эвакуатора] – очевидно, что пользователь хочет получить ответ именно по своему городу, хотя и не вписывает его в запрос. Определяются геозависимые запросы статистически. То есть по геозависимым запросам выдача у каждого региона будет разная.
Если у вас сайт общей тематики, рассчитанный на пользователей из всех регионов, то регион можно не присваивать. Сайтам общей тематики, вроде порталов, блогов и т.п. может быть присвоен статус «Не имеет региональной принадлежности».
Сайту не может быть присвоен статус «Не имеет региональной принадлежности», если он посвящен товарам или услугам конкретной организации, у которой имеется физический или юридический адрес.
Для того чтобы настроить регион сайта, укажите регион (можно указать только один), в котором вы продвигаетесь, а в поле ниже дайте ссылку на страницу, содержащую информацию о региональной принадлежности. К примеру, страницу контакты.
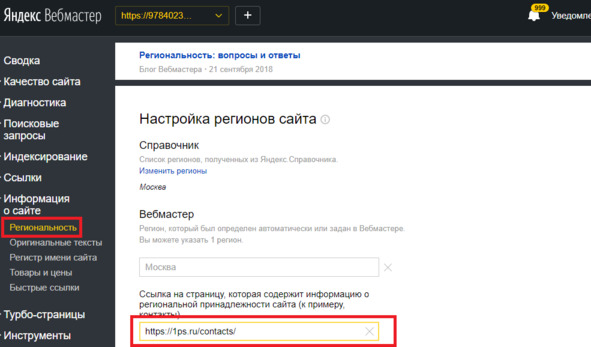
Рис.285. Настройка региона в Яндекс. Вебмастере
Изменения применятся после следующего апдейта Яндекса, если указанный регион согласует Яндекс. Бывает такое, что указанный регион не присваивается, причины могут быть разными, например, регион, который указали вы не соответствует продвигаемому на сайте, отличаются контакты сайта.
Регион советуем устанавливать с максимальной точностью. Если вы ведете свою деятельность в Иркутске, то стоит указать именно город Иркутск, а не Иркутскую область или Сибирский федеральный округ.
2. Раздел Справочник отображает регион, который назначен в Яндекс.Справочнике. Стоит разместить ресурс в справочнике, это поможет поисковому роботу Яндекса подробнее ознакомиться с вашей компанией, но добавление информации в данный справочник никак не влияет на продвижение.
Платон Щукин (вымышленный представитель техподдержки Яндекса) дал рекомендации по часто задаваемым вопросам от пользователей по поводу присвоения региона:
· Если ваш интернет-магазин доставляет товары по всей России, вы можете присвоить регион «Россия» в самом интерфейсе Яндекс.Вебмастера. Если сайт доставляет товары и за пределы России, можно указать регион СНГ.
· Яндекс рекомендует добавлять все филиалы в Яндекс.Справочник, так как все регионы, полученные из Справочника, могут влиять на ранжирование сайта по геозависимым запросам. Филиалами организации являются только те офисы, магазины и точки самовывоза, которые имеют одинаковое название с головным офисом и относятся к тому же виду деятельности. Точки выдачи нескольких магазинов разных брендов не считаются филиалами, и добавить их в Яндекс.Справочник не получится.
· Если сайт работает в нескольких городах (например, представительства есть только в трех городах), то в Яндекс.Вебмастере можно указать тот город, в котором находится главный офис, а остальные добавить через Справочник.
· В любом случае, алгоритмы поиска способны определить, что сайт релевантен запросу из какого-то региона, даже если у сайта нет этого региона в разделе «Региональность» Яндекс.Вебмастера.
· Если ваш сайт информационный, но в разделе «Диагностика» есть рекомендация о добавлении сайта в Справочник, укажите в настройках региональности Вебмастера «нет региона». Это даст роботу понять, что вы не забыли указать региональность, а указали именно на отсутствие региона у сайта.
Региональность в Google
Google отстает от Яндекса в качестве регионального поиска. Для настройки региональности в Google нам придет на помощь Google Search Console. Необходимо зарегистрироваться в данном сервисе, добавить свой сайт и подтвердить права (по аналогии с Яндекс.Вебмастером).
Google автоматически выставляет регион, основываясь на доменной зоне, и настраивать что-либо самостоятельно обычно не требуется. Если доменное имя находится в зоне .ru, то Google автоматически выстроит Россия.
Другое дело, когда ваш домен .org, .com, .net .moscow – придется настроить таргетинг по странам вручную. Нажмите галочку «Таргетинг на пользователей» и из выпадающего списка выберите нужную страну. Выбрать конкретные города возможности нет.
Важно добавить информацию о компании на Google.Maps, зарегистрировавшись в Google Мой бизнес. Это не влияет на продвижение напрямую, но принесет свои плоды. Пользователи смогут быстро найти вашу компанию в поисковой системе, посмотреть отзывы.
Вывод: при продвижении сайтов в конкретном регионе необходимо обязательно присвоить правильный регион в Вебмастерах, но кроме этого по максимуму пытайтесь уделить внимание вашему городу, подбирайте релевантные ключевые слова с указанием города, на их основе составляйте теги и пишите тексты, указывайте город в шапке сайта. Так вы подтолкнете поискового робота в правильном направлении, отсеете нецелевую аудиторию, привлекая нужных пользователей.
5.1.4. Вирусы
Зараженный ресурс рассылает спам, вредит компьютерам ваших клиентов, портит выдачу в поисковых системах и т. д. Вы обязаны заботиться о его безопасности, если не хотите потерять клиентов, позиции и репутацию.
Не знаете, что и как делать? Попробуем разобраться в диагностировании, лечении и предотвращении заражения.
Как понять, что произошло заражение сайта
Самые популярные маркеры того, что с сайтом что-то идет не так:
· ресурс заблокирован антивирусом или интернет-браузером;
· произошли резкие изменения в статистических параметрах сервера или индексации поисковых систем;
· сайт находится в черном списке Google или другой базе нежелательных адресов;
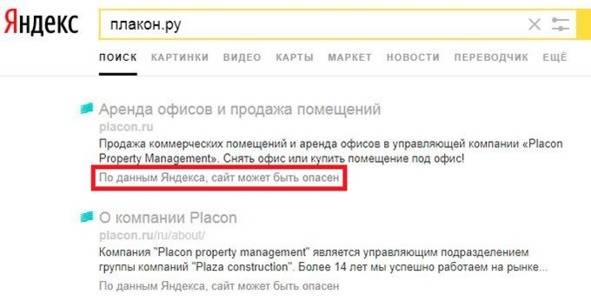
Рис.286. Предупреждение об опасности сайта в выдаче Яндекса
· сайт не работает должным образом, выдаются ошибки, предупреждения;
· в коде сайта есть подозрительный текст.
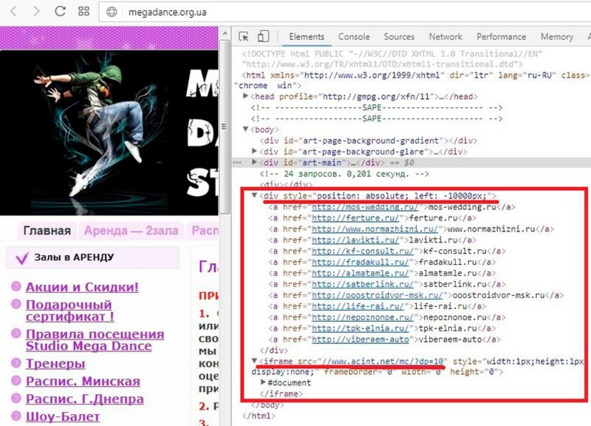
Рис.287. Подозрительный текст в коде сайта
Однако проверить свой сайт стоит в любом случае, даже если вы ничего из вышеперечисленного не замечали. Выдохнуть спокойно можно, когда подозрения на наличие вирусов на сайте не подтвердятся. Хотя нет, только после того, как примете превентивные меры защиты.
Наиболее частые источники или причины заражения
Основных причин и факторов, по которым ваш сайт может подхватить вирус и распространять его после этого по всему Интернету, не так и много. Ниже приведен список основных и наиболее встречающихся:
· использование вирусного ПО для кражи учетных данных, доступов от FTP, хостинга или панели управления сайтом;
· уязвимые компоненты в популярных CMS-платформах, например, Joomla, Wordpress, Bitrix, osCommerce;
· брутфорс – взлом пароля перебором.
Теперь мы знаем, что сайт может быть заражен как по вашей вине, так и благодаря стараниям сторонних «доброжелателей». Самое время рассмотреть, пожалуй, главное – идентификацию проблемы и ее устранение.
Что и чем проверять, и как лечить
Есть несколько подходов по выявлению причины проблемы и также несколько советов по ее излечению. Как и в других сферах, нет 100% гарантии, что проверка одним способом поможет решить все «косяки». Мы советуем для надежности использовать несколько методов.
Автоматическая проверка на вирусы средствами хостинга. Конечно, данные модули не являются панацеей, но в большинстве случаев определят заражение и укажут проблемные файлы.
Тестирование через программу Ai-bolit от revisium.com. Наиболее современная из всех существующих программ на данный момент. Она позволяет вычислить до 90% проблем. А там уже по факту обнаружения можно подбирать и метод исправления.
Если в коде сайта вы заметили какие-то посторонние подозрительные символы, куски кода и т. д., можно пользоваться специальными PHP-скриптами. Например, Far от Secu.ru. Они помогут найти файлы, которые содержат эту маску. После обнаружения надо провести чистку файлов от найденного «мусора». Но для данного метода нужны определенные знания в области программирования и файловой структуры сайта.
Полезно также проверить загруженную копию сайта на своём компьютере при помощи антивируса, предназначенного для локального компьютера. Современные антивирусы имеют развитый эвристический модуль, который позволяет с легкостью выявить вредоносные коды, поражающие сайты. Наиболее популярный на данный момент – rescan.pro.
Также можно проверить сайт через Вебмастер Яндекса, Mail, Bing, Google. Если на сайте будет обнаружена подозрительная активность, в панели Вебмастера появится соответствующее сообщение и общие рекомендации по дальнейшим действиям.
Периодически проверяйте страницы вашего сайта в индексе поисковых систем и по сниппету смотрите на содержание (для большого сайта). Если сайт небольшой (до 50 страниц), можно посмотреть каждую из страниц в сохраненной копии. Также рекомендуем периодически проверять файл. htaccess на наличие постороннего кода, который отправляет пользователей и роботов на разные виды контента (клоакинг). По аналогичной схеме работает часть дорвеев, но только в этом случае пользователю показывается тот же контент, либо производится его 3хх редирект на нужную страницу злоумышленника. В этом случае проверьте правильный ответ сервера страницы, при необходимости устраните проблему, в результате которой отдается неверный ответ. Стоит добавить правила в robots. txt для закрытия от индексации ненужных вошедших в индекс страниц, если взлом произошел.
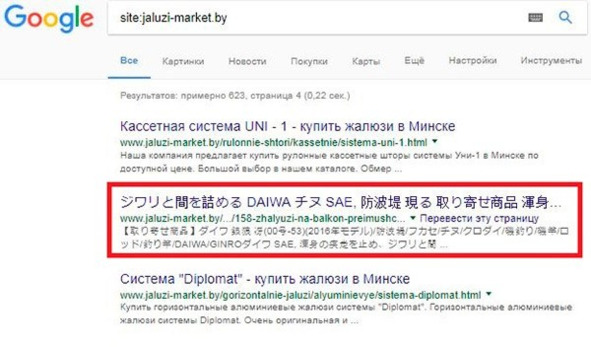
Рис.288. Пример вирусного сайта в выдаче Google
Важно проверять и состав пользователей, которые зарегистрированы на сайте. В первую очередь проверяем имеющих права к редактированию сайта. Если есть посторонние пользователи, их удаляем, отключаем права на редактирование и производим поиск уязвимости, выясняя, каким образом данный пользователь был добавлен.
Когда проверили сайт, нашли проблемы и устранили их, необходимо сменить пароли ко всем аккаунтам (панели управления хостингом и CMS, FTP, SSH, и т. д.).
Как защитить сайт?
Как уже неоднократно говорилось выше, лучше предупредить заражение, чем потом его лечить и исправлять последствия. Поэтому настоятельно рекомендуем соблюдать следующие меры безопасности.
Делайте резервные копии сайта. Желательно, чтобы период копирования был не менее 6 месяцев, т. к. при запущенной стадии заражения незатронутые вирусом файлы могут быть только в самых ранних версиях.
Используйте криптостойкие пароли. Их желательно ежемесячно обновлять.
Cкачивайте и устанавливайте актуальные версии ПО, регулярно их обновляйте. Своевременно устанавливайте все необходимые патчи, это поможет снизить риск атаки с использованием эксплойтов.
Не будет лишней и установка плагинов или компонентов с защитными свойствами. Например, изменяющие адреса админки или блокирующие IP вредителей, которые пытаются подобрать пароль. Можно добавить двойную авторизацию с помощью файлов *.htpasswd, отключив стандартный модуль восстановления пароля.
Настройте автоматическую проверку вашего сайта средствами хостинга.
Установите надежный антивирус на все компьютеры, с которых работаете с сайтом.
Не пересылайте пароли и запретите это делать всем сотрудникам, работающим с сайтом, любыми каналами связи (ВКонтакте, Facebook, Skype, различные мессенджеры и т.д.). Регулярно меняйте пароль от почты, с которой связан ваш сайт.
Повысьте безопасность специальными правилами в файле *.htaccess. Например, запретите php в папках, загружаемых пользователем через сайт, закройте загрузку исполняемых файлов.
Дополнительно можно ограничить показ сайта только в странах с вашей аудиторией. Очень часто преступники пользуются программами, шифрующими их местоположение IP других стран.
Если не используете SSH, то лучше вообще отключите его.
Выводы: К сожалению, не существует той самой таблетки, которая избавит вас от заражения раз и навсегда. Кибер-преступники не сидят на месте и изобретают новые способы, находят новые «дыры», пишут новые вирусы. Однако каждый может повысить надежность своего сайта, соблюдая основные правила безопасности, поддерживая чистоту сайта и компьютера.
5.2. Технические характеристики сайта
Если с основными параметрами все в порядке, можно приступать к настройке технических характеристик сайта. Файл robots.txt, карта сайта, зеркала, микроразметка – эти и другие технические параметры нужно корректно настроить, чтобы роботы правильно индексировали сайт. Но стоит еще раз напомнить, что все изменения нужно вносить осторожно, со знанием того, что вы делаете; либо лучше отказаться от самостоятельных правок и делегировать все техническим специалистам.
5.2.1. Robots.txt
Файл robots.txt – текстовый файл, который отвечает за индексирование сайта. Файл robots.txt представляет собой набор директив (набор правил для роботов), с помощью которых можно запретить или разрешить поисковым роботам индексирование определенных разделов и файлов вашего сайта, а также сообщить дополнительные сведения. Изначально с помощью robots.txt реально было только запретить индексирование разделов, возможность разрешать к индексации появилась позднее, и была введена лидерами поиска Яндекс и Google.
Структура файла robots.txt
Сначала прописывается директива User-agent, которая показывает, к какому поисковому роботу относятся инструкции.
Небольшой список известных и часто используемых User-agent:
· User-agent:*
· User-agent: Yandex
· User-agent: Googlebot
· User-agent: Bingbot
· User-agent: YandexImages
· User-agent: Mail.RU
Далее указываются директивы Disallow и Allow, которые запрещают или разрешают индексирование разделов, отдельных страниц сайта или файлов соответственно. Затем повторяем данные действия для следующего User-agent. В конце файла указывается директива Sitemap, где задается адрес карты вашего сайта.
Прописывая директивы Disallow и Allow, можно использовать специальные символы * и $. Здесь * означает «любой символ», а $ – «конец строки». Например, Disallow: /admin/*.php означает, что запрещается индексация всех файлов, которые находятся в папке admin и заканчиваются на .php, Disallow: /admin$ запрещает адрес /admin, но не запрещает /admin.php, или /admin/new/ , если таковой имеется.
Если для всех User-agent использует одинаковый набор директив, не нужно дублировать эту информацию для каждого из них, достаточно будет User-agent: *. В случае, когда необходимо дополнить информацию для какого-то из User-agent, следует продублировать информацию и добавить новую.
Пример robots. txt для WordPress:
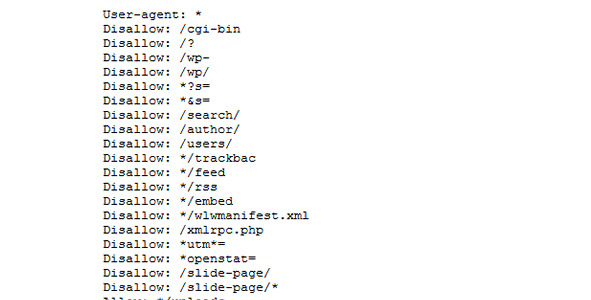
Рис.289. Пример robots. txt для WordPress
*Примечание для User agent: Yandex
· Для того чтобы передать роботу Яндекса Url без Get параметров (например:?id=,?PAGEN_1=) и utm-меток (например: &utm_source=, &utm_campaign=), необходимо использовать директиву Clean-param.
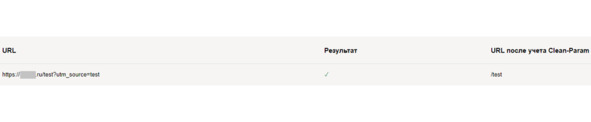
Рис.290. Пример применения директивы Clean-param
· Ранее роботу Яндекса можно было сообщить адрес главного зеркала сайта с помощью директивы Host. Но от этого метода отказались весной 2018 года.
· Также ранее можно было сообщить роботу Яндекса, как часто обращаться к сайту с помощью директивы Crawl-delay. Но как сообщается в блоге для вебмастеров Яндекса:
o Проанализировав письма за последние два года в нашу поддержку по вопросам индексирования, мы выяснили, что одной из основных причин медленного скачивания документов является неправильно настроенная директива Crawl-delay.
o Для того чтобы владельцам сайтов не пришлось больше об этом беспокоиться и чтобы все действительно нужные страницы сайтов появлялись и обновлялись в поиске быстро, мы решили отказаться от учёта директивы Crawl-delay.
Вместо этой директивы в Яндекс.Вебмастер добавили новый раздел «Скорость обхода».
Проверка robots.txt
Старая версия Search Console
Для проверки правильности составления robots.txt можно воспользоваться Вебмастером от Google – необходимо перейти в раздел «Сканирование» и далее «Просмотреть как Googlebot», затем нажать кнопку «Получить и отобразить». В результате сканирования будут представлены два скриншота сайта, где изображено, как сайт видят пользователи и как поисковые роботы. А ниже будет представлен список файлов, запрет к индексации которых мешает корректному считыванию вашего сайта поисковыми роботами (их необходимо будет разрешить к индексации для робота Google).
Обычно это могут быть различные файлы стилей (css), JavaScript, а также изображения. После того, как вы разрешите данные файлы к индексации, оба скриншота в Вебмастере должны быть идентичными. Исключениями являются файлы, которые расположены удаленно, например, скрипт Яндекс.Метрики, кнопки социальных сетей и т.д. Их у вас не получится запретить/разрешить к индексации.
Новая версия Search console
В новой версии нет отдельного пункта меню для проверки robots. txt. Теперь достаточно просто вставить адрес нужной страницы в строку поиска.
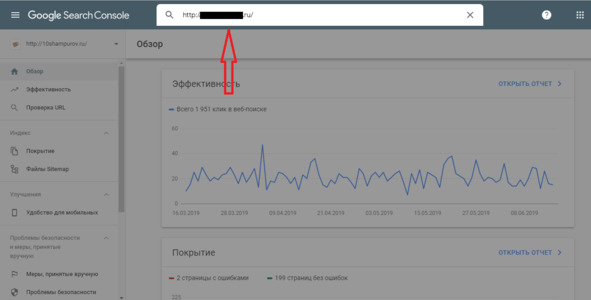
Рис.291. Проверка robots. txt в Search console
В следующем окне нажимаем «Изучить просканированную страницу».
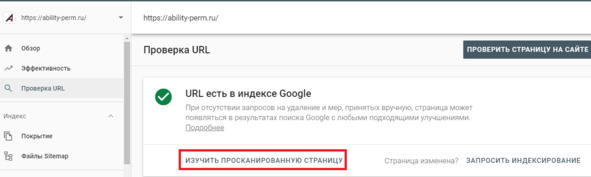
Рис.292. Проверка недоступных страниц роботу Google через Search console
Далее нажимаем ресурсы страницы. В появившемся окне видно ресурсы, которые по тем или иным причинам недоступны роботу Google.
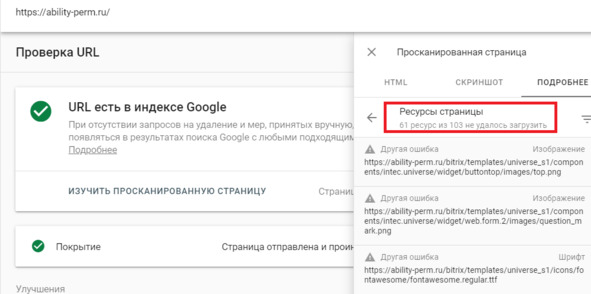
Рис.293. Недоступные страницы роботу Google
Если же такие ресурсы будут, вы увидите сообщения следующего вида:
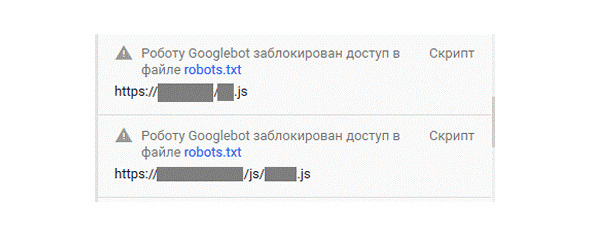
Рис.294. Заблокированные файлы роботу Google
Рекомендации, что закрыть в robots.txt
Каждый сайт имеет уникальный robots.txt, но некоторые общие черты можно выделить в такой список:
· Закрывать от индексации страницы авторизации, регистрации, вспомнить пароль и другие технические страницы.
· Админ панель ресурса.
· Страницы сортировок, страницы вида отображения информации на сайте.
· Для интернет-магазинов страницы корзины, избранное. Более подробно вы можете почитать в советах интернет-магазинам по настройкам индексирования в блоге Яндекса.
· Страница поиска.
Это лишь примерный список того, что можно закрыть от индексации от роботов поисковых систем. В каждом случае нужно разбираться в индивидуальном порядке, в некоторых ситуациях могут быть исключения из правил.
Вывод: файл robots.txt является важным инструментом регулирования отношений между сайтом и роботом поисковых систем, важно уделять время его настройке.
Мы описали в основном правила, посвященные роботам Яндекса и Google, но это не означает, что нужно составлять файл только для них. Есть и другие роботы – Bing, Mail.ru, и др. Можно дополнить robots.txt инструкциями для них.
Многие современные cms создают файл robots.txt автоматически, и в них могут присутствовать устаревшие директивы. Поэтому рекомендуем после прочтения книги проверить файл robots.txt на своем сайте, а если они там присутствуют, желательно их удалить.
5.2.2. Sitemap.xml
Карта сайта XML – это файл, размещенный в корневой директории сайта, с информацией для поисковых систем (таких как Яндекс, Google, Rambler, Bing и других) о страницах вашего сайта. Файл этот нужен для того, чтобы поисковым системам было легче индексировать ваш сайт.
По сути, это оглавление сайта, в котором перечислены все страницы ресурса. Файл sitemap.xml позволяет роботу быстрее понять, какие страницы есть на сайте. Как правило, файл расположен по стандартному адресу site.ru/sitemap.xml.
Как работает карта сайта XML?
Заходя на сайт, поисковый робот, прежде всего, читает инструкции в файле robots.txt о том, как следует индексировать сайт. И если в нём указать, что есть карта сайта sitemap.xml, то робот перейдет по указанному адресу, где перечислены URL-адреса самых важных страниц сайта, которые подлежат обязательной индексации.
Поэтому не забудьте, что файл sitemap.xml надо не просто разместить у себя на сайте, а указать к нему путь в robots.txt к директиве sitemap.
Пример:
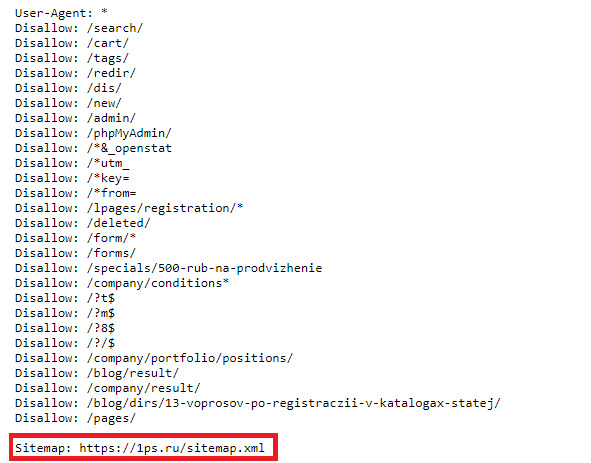
Рис.295. Указание директивы Sitemap в файле robots. txt
Вот так карта сайта XML облегчит работу поисковику и обеспечит качественную индексацию вашему сайту.
Как создать карту сайта XML?
Это не трудно. В сети есть несколько бесплатных программ и сайтов, которые сгенерируют вам такую карту автоматически. Вот некоторые из них: sitemapgenerator.ru, xml-sitemaps.com, cy-pr.com/tools/sitemap/







