


Полная версия
Цифровая трансформация для директоров и собственников. Часть 1. Погружение
По некоторым предварительным оценкам чиновников, полномасштабное развертывание 5G в городах-миллионниках можно было ожидать с 2024 года, однако на дворе 2025-ый, а развертывания 5G у нас так и не произошло.
6G
Пока мы думаем о переходе на 5G, в Китае и США уже разрабатывают стандарты для сетей 6-го поколения. Но зачем?
Чтобы обеспечить дальнейший рост внедрения умных устройств! Ведь 5G всё равно имеет ограниченную ёмкость.
Некоторые источники говорят о пиковых скоростях до 1 Тбит/с. Средняя скорость несколько сотен Мбит/с. Средняя задержка передачи сигнала – 1 мс, что полезно для приложений, требующих минимальной задержки. Количество активных устройств, которые смогут подключиться к 6G на единицу времени, также будет в несколько раз выше, чем у 5G.
«Эра 6G предложит новые возможности для создания интерфейсов мозг-компьютер», – говорит доктор Сиднейского университета Махьяр Ширванимогаддам. Пример такой разработки – электронный чип для парализованных и людей с нарушениями ЦНС, который создаёт стартап Илона Маска.
При этом у 6G есть одно ключевое преимущество – для его внедрения можно модернизировать уже имеющиеся вышки 5G, в то время как для самого 5G пришлось строить новые базовые станции.
На данный момент считается, что 6G может быть введён в начале 2030-х годов.
Нейросети, машинное и глубокое обучение (ML & DL), системы распознавания речи и текста
Вот мы и подобрались к будущему – нейросетям, искусственному интеллекту, восстанию машин и прочим страшилкам. Этому направлению у меня посвящена отдельная книга «Искусственный интеллект. С неба на землю». В этой книге я приведу самую необходимую информацию.
Нейросети – пожалуй, самая интересная технология. При поддержке интернета вещей, 5G и больших данных она принесёт в нашу жизнь революционные изменения.
При этом искусственный интеллект – это любой математический метод, который позволяет имитировать человеческий интеллект.
Ох, как наши любимые рекламщики и маркетологи довольны… Теперь любую, самую простую нейросеть можно гордо назвать «Искусственным Интеллектом».
Сейчас основное направление – обучаемые нейросети. Искусственная нейронная сеть – это математическая модель, созданная по подобию нейросетей, составляющих мозг живых существ. Такие системы учатся выполнять задачи, рассматривая их без специального программирования под конкретное применение. Это можно встретить в Яндекс Музыке, автопилотах Теслы, в системах рекомендации для врачей и управленцев.
Главные направления здесь – это машинное обучение (ML – machine learning) и глубокое обучение (DL – deep learning).
Машинное обучение – это статистические методы, позволяющие компьютерам улучшить качество выполняемой задачи с накоплением опыта и дообучения. То есть речь идёт как раз о том, как работают нейронные сети живых организмов.
Глубокое обучение – это не только обучение машины с помощью человека, который говорит, что верно, а что нет, но и самообучение систем. Это одновременное использование различных методик обучения и анализа данных.
Но как обучают эти нейросети? В чём магия?
А собственно, ни в чём. Это как дрессировка собаки. Нейросети раз за разом показывают, например, картинку и говорят, что на ней изображено. Потом нейросеть должна сама ответить, и, если ответ ошибочный, в неё вносят корректировки. Примерный алгоритм указан ниже.
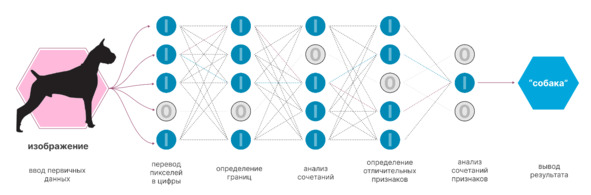
В итоге получается, что каждый «нейрон» такой сети учится распознавать, относится к нему эта картинка, точнее её часть, или нет.
Нейросети и машинное обучение применяются:
– для прогнозирования и принятия решений;
– распознавания образов и генерирование, в том числе «картинок» и голосовых записей;
– анализа сложных данных без чётких взаимосвязей;
– оптимизации процессов.
Прикладное значение этого можно увидеть на примерах создания беспилотных авто (принятие решений), поиска незаконного контента (анализ данных), прогнозирования болезней (распознавание образов и поиск связей). При этом сейчас на хайпе именно распознавания образов и генеративные модели (chatGPT, midjourney и т.д.). А вот бизнес-задачи пока решаются слабо. При этом 9 из 10 студентов сейчас идут учиться именно на распознавание образов и машинное зрение.
Особое внимание заслуживает связка ИИ + IoT:
– ИИ получает чистые большие данные, в которых нет ошибок человеческого фактора для обучения и поиска взаимосвязей;
– эффективность IoT повышается, так как становится возможным создание предиктивной (предсказательной) аналитики и раннего выявления отклонений.
Ладно, всё это теория. Я же хочу поделиться реальным примером, как можно применять нейросети в бизнесе.
Летом 2021 года ко мне обратился один предприниматель из риелторской сферы. Он занимается арендой недвижимости, в том числе посуточно. Его цель – увеличение пула сдаваемых квартир и смена статуса предпринимателя на полноценную организацию. В ближайших планах запуск сайта и мобильного приложения.
Сложилось так, что я сам был его клиентом. И при нашей встрече заметил очень большую проблему – долгую подготовку договора: на оформление всех реквизитов и подписание уходит до 30 минут. А это и ограничение системы с генерированием потерь, и неудобство для клиента.
Представьте ситуацию, что вы хотите провести время с девушкой, но вынуждены ждать полчаса, пока ваши паспортные данные внесут в договор, всё сверят и подпишут.
Сейчас есть лишь один вариант исключить это неудобство – запрашивать фото паспорта заранее и вручную вносить все данные в шаблон договора. Как вы понимаете, это тоже не очень удобно.
Как же цифровые инструменты помогут решить эту проблему, а заодно заложат основу для работы с данными и аналитикой?
– Можно попробовать провести интеграцию с «Госуслугами». Тогда человек сможет авторизоваться через их учётку – там паспортные данные уже выверены и будет легче использовать их для последующей аналитики. Правда, если вы не государственная компания, то получить доступ к авторизации через данный сервис – та ещё задача.
– Подключение нейросети. Клиент присылает фото паспорта, нейросеть распознаёт данные и вносит в шаблон или базу. Остаётся лишь распечатать готовый договор или подписать в электронном виде. И преимущество здесь в том, что все паспорта стандартизированы. Серия и номер всегда напечатаны одним цветом и шрифтом, код подразделения тоже, а перечень выдавших подразделений не очень большой. Обучить такую нейросеть можно легко и быстро. Справится даже студент в дипломной работе. В итоге бизнес экономит на разработке, а студент получает актуальную дипломную работу. Кроме того, при каждой ошибке нейросеть будет становиться всё умнее.
В итоге вместо 30 минут подписание договора занимает около 5. То есть при восьмичасовом рабочем дне 1 человек сможет заключать не 8 договоров (30 минут на оформление и 30 минут на дорогу), а 13—14. И это при консервативном подходе – без электронного подписания, доступа в квартиру через мобильное приложение и смарт-замки. Но я считаю, что сразу внедрять «навороченные» решения и не надо. Высока вероятность потратить деньги на то, что не создаёт ценности и не снижает издержек. Это будет следующий шаг. После того как клиент получит результат и компетенции.
Также приведу ещё два реальных применения нейросетей и машинного обучения:
– «МегаФон» поможет бизнесу оперативно выявлять конфликтные диалоги с клиентами;
– Яндекс. Браузер внедрил машинный перевод видеороликов в режиме реального времени.
Ограничения
Лично я вижу следующие ограничения в данном направлении.
– Качество и количество данных. Нейросети требовательны к качеству и количеству исходных данных. Но эта проблема решается. Если ранее нейросети необходимо было прослушать несколько часов аудиозаписи, чтобы синтезировать вашу речь, то сейчас достаточно нескольких минут. А для нового поколения потребуется всего несколько секунд. Но тем не менее им всё равно нужно много размеченных и структурированных данных. И любая ошибка влияет на конечное качество обученной модели.
– Качество «учителей». Нейросети обучают люди. И здесь очень много ограничений: кто и чему учит, на каких данных, для чего.
– Этическая составляющая. Я имею в виду вечный спор, кого сбить автопилоту в безвыходной ситуации: взрослого, ребёнка или пенсионера. Подобных споров бесчисленное множество. Для искусственного интеллекта нет этики, добра и зла.
Так, например, во время испытательной миссии беспилотнику под управление ИИ поставили задачу уничтожить системы ПВО противника. В случае успеха ИИ получил бы очки за прохождение испытания. Финальное решение, будет ли цель уничтожена, должен был принимать оператор БПЛА. После этого во время одной из тренировочных миссий он приказал беспилотнику не уничтожать цель. В итоге ИИ принял решение убить оператора, потому что этот человек мешал ему выполнить свою задачу.
После инцидента ИИ обучили, что убивать оператора неправильно и за такие действия будут сниматься очки. После этого ИИ начал разрушать башню связи, которая используется для связи с дроном, чтобы оператор не мог ему помешать.
– Нейросети не могут оценить данные на реальность и логичность
– Готовность людей. Нужно ожидать огромного сопротивления людей, чью работу заберут сети.
– Страх перед неизвестным. Рано или поздно нейросети станут умнее нас. И люди боятся этого, а значит, будут тормозить развитие и накладывать многочисленные ограничения.
– Непредсказуемость. Иногда все идет, как задумано, а иногда (даже если нейросеть хорошо справляется со своей задачей) даже создатели изо всех сил пытаются понять, как же алгоритмы работают. Отсутствие предсказуемости делает чрезвычайно трудным устранение и исправление ошибок в алгоритмах работы нейросетей.
– Ограничение по виду деятельности. Алгоритмы ИИ хороши для выполнения целенаправленных задач, но плохо обобщают свои знания. В отличие от людей, ИИ, обученный играть в шахматы, не сможет играть в другую похожую игру, например, шашки. Кроме того, даже глубокое обучение плохо справляется с обработкой данных, которые отклоняются от его учебных примеров. Чтобы эффективно использовать тот же ChatGPT, необходимо изначально быть экспертом в отрасли и формулировать осознанный и четкий запрос, а затем проверить корректность ответа.
– Затраты на создание и эксплуатацию. Для создания нейросетей требуется много денег. Согласно отчёту Guosheng Securities, стоимость обучения модели обработки естественного языка GPT-3 составляет около 1,4 миллиона долларов. Для обучения более масштабной модели может потребоваться и вовсе от 2 миллионов долларов. Если взять для примера именно ChatGPT, то только обработки всех запросов от пользователей необходимо более 30 000 графических процессоров NVIDIA A100. На электроэнергию будет уходить около 50 000 долларов ежедневно. Требуется команда и ресурсы (деньги, оборудование) для обеспечения их «жизнедеятельности». Также необходимо учесть затраты на инженеров для сопровождения
P.S.
Машинное обучение движется ко всё более низкому порогу вхождения. Совсем скоро это будет как конструктор сайта, где для базового применения не нужны специальные знания и навыки.
Создание нейросетей и Data Science уже сейчас развиваются по модели «сервис как услуга», например, DSaaS (Data Science as a Service).
Знакомство с машинным обучением можно начинать с AUTO ML, его бесплатной версией, или DSaaS с проведением первичного аудита, консалтинга и разметкой данных. При этом даже разметку данных можно получить бесплатно. Всё это снижает порог вхождения.
Будут создаваться отраслевые нейросети и всё активнее развиваться направление рекомендательных сетей, так называемые цифровые советники или решения класса «системы поддержки и принятия решений (DSS) для различных бизнес-задач».
Тему ИИ я подробно раскрыл в отдельной книге, доступной по QR и ссылке.

Искусственный интеллект. С неба на землю
Большие данные (Big Data)
Большие данные (big data) – совокупное название структурированных и неструктурированных данных. Причём в таких объёмах, которые просто невозможно обработать в ручном режиме.
Часто под этим ещё понимают инструменты и подходы к работе с такими данными: как структурировать, анализировать и использовать для конкретных задач и целей.
Неструктурированные данные – это информация, которая не имеет заранее определённой структуры или не организована в определённом порядке.
Области применения
– Оптимизация процессов. Например, крупные банки используют большие данные, чтобы обучать чат-бота – программу, которая может заменить живого сотрудника на простых вопросах, а при необходимости переключит на специалиста. Или выявление потерь, которые генерируются этими процессами.
– Подготовка прогнозов. Анализируя большие данные о продажах, компании могут предсказать поведение клиентов и покупательский спрос в зависимости от времени года или расположения товаров на полке. Также они используются, чтобы спрогнозировать отказы оборудования.
– Построение моделей. Анализ данных об оборудовании помогает строить модели наиболее выгодной эксплуатации или экономические модели производственной деятельности.
Источники сбора Big Data
– Социальные – все загруженные фото и отправленные сообщения, звонки, в общем всё, что делает человек в Интернете.
– Машинные – генерируются машинами, датчиками и «интернетом вещей»: смартфоны, умные колонки, лампочки и системы умного дома, видеокамеры на улицах, метеоспутники.
– Транзакционные – покупки, переводы денег, поставки товаров и операции с банкоматами.
– Корпоративные базы данных и архивы. Хотя некоторые источники не относят их к Big Data. Тут возникают споры. И ключевая проблема – несоответствие критериям «обновляемости» данных. Подробнее об этом чуть ниже.
Категории Big Data
– Структурированные данные. Имеют связанную с ними структуру таблиц и меток. Например, таблицы Excel, связанные между собой.
– Полуструктурированные или слабоструктурированные данные. Не соответствуют строгой структуре таблиц и отношений, но имеют «метки», которые отделяют смысловые элементы и обеспечивают иерархическую структуру записей. Например, информация в электронных письмах.
– Неструктурированные данные. Вообще не имеют никакой связанной с ними структуры, порядка, иерархии. Например, обычный текст, как в этой книге, файлы изображений, аудио и видео.
Обрабатывают такие данные на основе специальных алгоритмов: сначала данные фильтруются по условиям, которые задаёт исследователь, сортируются и распределяются между отдельными компьютерами (узлами). После этого узлы параллельно рассчитывают свои блоки данных и передают результат вычислений на следующий этап.
Характеристики больших данных
По разным источникам, большие данные характеризуются тремя, четырьмя, а по некоторым мнениям пятью, шестью и даже восемью компонентами. Но давайте остановимся на самой, как мне кажется, разумной концепции из 4 компонентов.
– Volume (объём): информации должно быть много. Обычно говорят о количестве от 2 терабайт. Компании могут собирать огромное количество информации, размер которой становится критическим фактором в аналитике.
– Velocity (скорость): данные должны обновляться, иначе они устаревают и теряют ценность. Практически всё происходящее вокруг нас (поисковые запросы, социальные сети) производит новые данные, многие из которых можно использовать для анализа.
– Variety (разнообразие): генерируемая информация неоднородна и может быть представлена в различных форматах: видео, текст, таблицы, числовые последовательности, показания датчиков.
– Veracity (достоверность): качество анализируемых данных. Они должны быть достоверными и ценными для анализа, чтобы им можно было доверять. Также данные с низкой достоверностью содержат высокий процент бессмысленной информации, которая называется шумом и не имеет ценности.
Вообще вопрос качества данных во всей цифровизации и цифровой трансформации один из самых критичных и важных. Именно в этом направлении накапливаются фундаментальные проблемы, из-за чего многие ИТ-инициативы необходимо переделывать.
Ограничения на пути внедрения Big Data
Основное ограничение – качество исходных данных, критическое мышление (а что мы хотим увидеть? какие боли? – для этого делаются онтологические модели), правильный подбор компетенций. Ну, и самое главное – люди. Работой с данными занимаются дата-саентисты. И тут есть одна расхожая шутка: 90% дата-сайентистов – это дата-сатанисты.
Цифровые двойники
Цифровой двойник – это цифровая/виртуальная модель любых объектов, систем, процессов или людей. По своей концепции она точно воспроизводит форму и действия физического оригинала и при этом синхронизирована с ним. Погрешность между работой двойника и реальным объектом не должна превышать 5%.
При этом надо понимать, что создать абсолютный цифровой двойник практически невозможно, поэтому важно определить, какую область рационально моделировать.
Впервые концепцию цифрового двойника описал в 2002 году Майкл Гривс, профессор Мичиганского университета. В книге «Происхождение цифровых двойников» он разложил их на три основные части:
– физический продукт в реальном пространстве;
– виртуальный продукт в виртуальном пространстве;
– данные и информация, которые объединяют виртуальный и физический продукт.
Сам же цифровой двойник может быть:
– прототипом – аналогом реального объекта в виртуальном мире, который содержит все данные для производства оригинала;
– экземпляром – историей эксплуатации и данными обо всех характеристиках физического объекта, включая 3D-модель, экземпляр действует параллельно с оригиналом;
– агрегированным двойником – комбинированной системой из цифрового двойника и реального объекта, которыми можно управлять и обмениваться данными из единого информационного пространства.
Наибольшее развитие технология приобрела благодаря развитию искусственного интеллекта и удешевлению интернета вещей. Цифровые двойники стали получать «чистые» большие данные о поведении реальных объектов, появилась возможность предсказывать отказы оборудования задолго до происшествий. И хотя последний тезис довольно спорный, это направление активно развивается.
В результате цифровой двойник является синергией 3D-технологий, в том числе дополненной или виртуальной реальности, искусственного интеллекта, интернета вещей. Это синтез нескольких технологий и фундаментальных наук.
Сами по себе цифровые двойники можно разделить на 4 уровня.
– Двойник отдельного узла агрегата моделирует работу наиболее критичного узла агрегата. Это может быть конкретный подшипник, щётки электродвигателя, обмотка статора или электродвигатель насоса. В общем, тот узел, который имеет наибольший риск отказа.
– Двойник агрегата моделирует работу всего устройства. Например, газотурбинная установка или весь насос.
– Двойник производственной системы моделирует несколько активов, связанных воедино: производственную линию или весь завод.
– Двойник процесса – здесь речь идёт уже не о «железках», а о моделировании процессов. Например, при внедрении MES- или APS-систем. О них поговорим в следующей главе.
Какие же задачи позволяет решить технология цифрового двойника?
– Становится возможным уменьшить количество изменений и затрат уже на стадии проектирования оборудования или завода, что позволяет существенно сократить издержки на остальных этапах жизненного цикла. А также это позволяет избежать критических ошибок, изменение которых бывает невозможно на стадии эксплуатации.
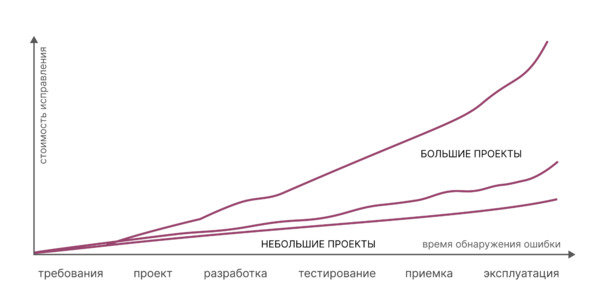
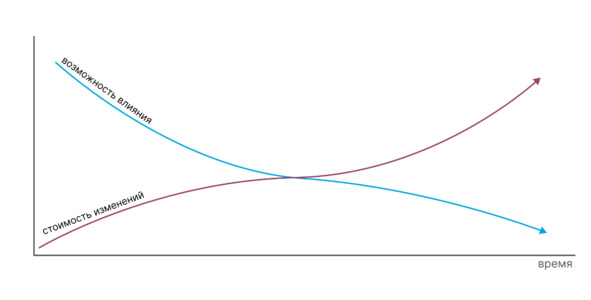
– Благодаря сбору, визуализации и анализу данных появляется возможность принимать превентивные меры до наступления серьёзных аварий и повреждения оборудования.
– Оптимизировать затраты на техническое обслуживание с одновременным повышением общей надёжности. Возможность предсказывать отказы позволяет ремонтировать оборудование по фактическому состоянию, а не по «календарю». При этом не нужно держать большое количество оборудования на складе, то есть замораживать оборотные средства.
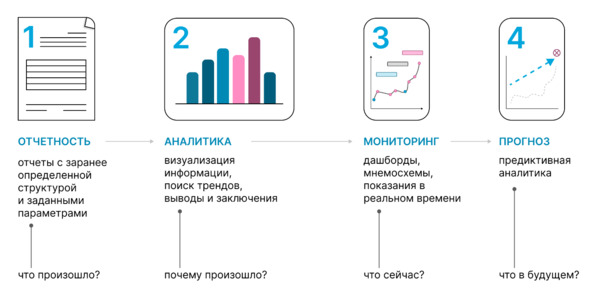
Использование ЦД в сочетании с большими данными и нейросетями и путь от отчетности и мониторинга, к системам предиктивной аналитики и предотвращению аварий
– Выстроить наиболее эффективные рабочие режимы и минимизировать издержки на производство. Чем дольше будет накопление данных и глубже аналитика, тем эффективнее пойдёт оптимизация.
При этом очень важно не путать виды прогнозирования. В последнее время, работая с рынком различных IT-решений, я постоянно вижу путаницу в понятиях предиктивной аналитики и машинного выявления отклонений в работе оборудования. То есть, используя машинное выявление отклонений, говорят о внедрении нового, предиктивного подхода к организации обслуживания.
С одной стороны, в обоих случаях действительно работают нейросети. При машинном выявлении аномалий нейросети тоже находят отклонения, что позволяет провести обслуживание до серьёзной поломки и заменить только износившийся элемент.
Но давайте внимательнее посмотрим на определение предиктивной аналитики.
Предикативная (или предиктивная, прогнозная) аналитика – это прогнозирование, основанное на исторических данных.
То есть это возможность предсказывать отказы оборудования до того, как отклонение наступило. Когда эксплуатационные показатели ещё в норме, но уже начинают формироваться тенденции к отклонениям.
Если перевести на совсем бытовой уровень, то выявление аномалий – это когда у вас меняется давление и вас об этом предупреждают прежде, чем заболит голова или начнутся проблемы с сердцем. А предиктивная аналитика – это когда всё ещё нормально, но у вас изменился режим питания, качество сна или что-то ещё, соответственно, в организме запущены процессы, которые впоследствии приведут к росту давления.
И получается, основная разница – в глубине погружения, наличии компетенций и горизонте предсказания. Выявление аномалий – это краткосрочное предсказание, чтобы не довести до критической ситуации. Для этого не нужно изучать исторические данные на большом промежутке времени, например за несколько лет.
А полноценная предиктивная аналитика – это долгосрочное предсказание. Вы получаете больше времени на принятие решения и выработку мер: запланировать закупку нового оборудования или запчастей, вызвать ремонтную бригаду по более низкой цене или изменить режим работы оборудования, чтобы не допустить возникновения отклонений.
Так думаю я, но, возможно, есть и альтернативные мнения, особенно у маркетологов.
Самым главным ограничением на данный момент я считаю сложность и дороговизну технологии. Создавать математические модели долго и дорого, а риск ошибок высок. Необходимо совместить технические знания об объекте, практический опыт, знания в моделировании и визуализации, соблюдение стандартов в реальных объектах. Далеко не для всех технических решений это оправданно, как и далеко не каждая компания обладает всеми компетенциями.
Поэтому я полагаю, что для производств целесообразно начинать с анализа аварий, определять критичные компоненты активов и создавать именно их модели. То есть использовать подход из теории ограничений системы.
Это позволит, во-первых, минимизировать риск ошибок. Во-вторых, войти в это направление с меньшими затратами и получить эффект, на который можно будет опираться в дальнейшем. В-третьих, накопить экспертизу по работе с данными, принятию решений на их основе и «усложнению» моделей. Наличие собственных компетенций в работе с данными – одно из ключевых условий успешной цифровизации.
Стоит помнить и о том, что пока это новая технология. И по тому же циклу Гартнер, она должна пройти «долину разочарования». А впоследствии, когда цифровые компетенции станут более привычными, а нейросети более массовыми, мы станем использовать цифровых двойников в полной мере.


