


Полная версия
Базовая оценка минерализации. Ресурсный геолог
Кроме фактора симметричности и наличия/отсутствия аномальных значений, на оценку среднего может повлиять и разница в других свойствах предметов (явлений), которые приводят к смещению оценки среднего. Одним из подобных факторов является свойство, которое принято называть весом.
Представим себе ситуацию смешивания двух объемов руды: одна смешиваемая руда характеризуется содержанием золота (почему бы и не золота?) 5 г/т, вторая – 10 г/т. Обычное среднее арифметическое, очевидно, в данном случае составит 7.5 г/т. То есть, если мы очень хорошо перемешаем рудный материал, то ожидаем увидеть в получившейся смеси эти самые 7.5 г/т. Но что будет, если масса «пятиграммовой» руды составит 10 т, а «десятиграммовой» – 1 т? Очевидно, что в результате смешивания мы получим 11 т руды. При этом из первой порции «придет» 50 г драгоценного металла, а из второй – 10 г. То есть в смеси всего будет содержаться 60 г. И среднее в этом случае составит 60/11 ≈ 5.45 г/т. Очевидно, цифра несколько отличается от ранее полученных 7.5 г/т (что, безусловно, обидно, зато позволило не впасть в ошибку при ожидании).
Учет подобных факторов при вычислении среднего называется взвешиванием, а среднее – средневзвешенным. Взвешивание используется при вычислении характеристик выборки довольно широко. Например, при композитировании данных опробования вдоль по скважинам (в этом случае используется взвешивание на длину проб). Или вычислении среднего по резко неравномерной сети (выполняется взвешивание на вес декластеризации). Вопросы способов вычисления весов рассматриваются в главах, посвященных декластеризации и композированию (впрочем, второе, по сути, является частным случаем первого).
Процентиль, медиана и мода
Кроме вычисления среднего с помощью указанных выше приемов, существуют другие способы краткой характеристики выборки, которые также дают представление о том, с чем имеет дело геолог. И следующие величины, которые мы рассмотрим, процентили или перцентили.
Процентиль – это характеристика выборки, представляющая собой значение, ниже которого находится заданная доля значений в данной выборке. То есть, если говорят, что для какой-то выборки 20% процентиль равен, предположим, 3.2, то это означает, что 20% значений этой выборки не превосходят значение 3.2.
В ряде руководств процентиль определяется как вероятность того, что наугад взятое значение, принадлежащее выборке, не превзойдет значения процентиль. В принципе, эти два определения описывают одну и ту же величину, только немного с разных позиций.
Существует довольно большое количество способов для расчета процентилей. Неплохой обзор способов их расчета приведен в англоязычной версии «Википедии4» (причем, что печально, русская версия этой статьи отличается избыточной лаконичностью). Если вы испытываете неприязнь к «Википедии» как к источнику информации, в упомянутой статье содержатся ссылки на первоисточники – можно почитать непосредственно научные статьи.
Маловероятно, что вам потребуется вручную считать процентили, поскольку формулы для их расчета заложены практически во все ПО, имеющее отношение к обработке данных – от Google Sheets до статистических пакетов (естественно, и в пакетах для геологического моделирования эти возможности тоже есть). Просто необходимо помнить, что существуют разные методы их расчета, и процентили, рассчитанные в одном ПО, могут незначительно отличаться от тех же процентилей, рассчитанных в другом ПО. В подавляющем количестве случаев эти различия не оказывают какого-либо влияния на финальный результат обработки данных, поэтому пугаться несовпадения цифр не стоит.
Наиболее часто используемые процентили – это 25%, 50% и 75% процентили. Процентили 25 и 75 называются квартилями – первым и третьим, соответственно. Первый квартиль (т. е. 25 процентиль) отсекает четверть выборки «снизу», т. е. 25% наименьших значений. Третий квартиль (75 процентиль) отсекает четверть выборки «сверху» – т. е. 25% наибольших значений в данной выборке. Процентиль 50% называется медианой и делит выборку на две равные части по количеству наблюдений или весу. Также достаточно часто рассчитываются процентили с шагом 10%: 10%, 20%, 30% и т. д. Такие процентили называют децилями.
Медиана делит распределение пополам, квартили – на четверти, квинтили – на 5 частей, децили – на 10 частей, процентили – на 100 частей.
Разность между первым и третьим квартилями называется межквартильным размахом. Это довольно важная характеристика выборки. Она показывает размах значений половины членов выборки. На величине межквартильного размаха построены некоторые способы ограничения аномальных значений. Также межквартильный размах используется в построении диаграммы, называемой «ящик с усами» (собственно, квартили там являются границами ящика).
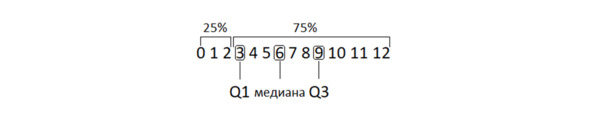
Квартили и медиана
Здесь первый квартиль Q1 – число, отделяющее первую четверть выборки: 25% значений меньше, а 75% – больше него. Медиана – половина значений больше и половина меньше нее. Третий квартиль Q3 – это отсечка трех четвертей: 75% значений меньше и 25% значений больше него. Межквартильный размах – это расстояние между Q1 и Q3. Или, по-другому, межквартильный размах – это размах половины данных. Причем данных «из центра» распределения.
Медиана является одной из характеристик выборки. Положительное свойство медианы заключается в том, что на нее не оказывает влияние наличие в выборке аномальных значений. Например, в упомянутых примерах с избыточно меркантильным директором небольшого предприятия медиана будет равна тем самым 30 т. р., которые получают не менее 50% сотрудников описанной организации. И даже если директор начнет получать 4 млн р. (не изменив при этом зарплату остальному коллективу), медиана не сдвинется ни на копейку.
Для процентилей, как и для среднего, доступно взвешивание. В этом случае процентиль будет представлять собой величину, ниже которой находится часть выборки, содержащая заданную долю суммы весов. Если, например, речь идет о рудной выборке и взвешивании на длину пробы, то наглядно, например, первый квартиль можно представить себе как границу четверти суммарной длины проб с наименьшими содержаниями.
Еще одной характеристикой, позволяющей получить представление о выборке, является мода. Эта характеристика называется так совершенно заслуженно: мода – это наиболее часто встречаемое значение (т. е. наиболее «модное»). Мода так же, как и медиана, может служить характеристикой среднего, но чаще используется для характеристики выборки, представленной нечисловыми значениями (например, литологической характеристики). Выборка может содержать более одной моды. В этом случае говорят, что выборка полимодальная (мультимодальная).
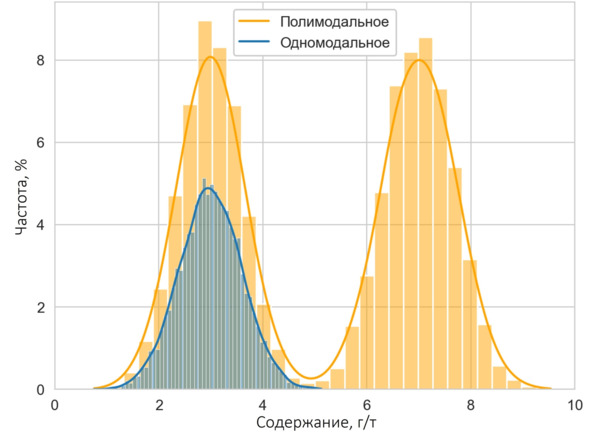
Одномодальное и полимодальное распределение на гистограмме
Например в выборке 2, 2, 3, 4, 5, 6, 7, 7 модами будут значения 2 и 7. Значение 2 будет называться нижней модой, значение 7 верхней модой. Если два соседних значения встречаются одинаково часто, то мода считается как среднее арифметическое между ними. Например в выборке 2, 3, 3, 4, 4, 5, 6 модой будет значение 3.5 (три целых пять десятых) поскольку 3 и 4 находятся рядом и встречаются одинаково часто. На гистограмме значениям моды соответствует вершина графика (при одномодальном распределении) или несколько вершин графика (при полимодальном распределении).
Дисперсия
Кроме «точечных» характеристик исследуемой величины, также полезно знать и о степени отклонения значений исследуемой величины от среднего, а также «направлении» отклонения.
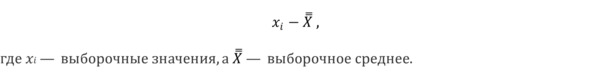
Формула отклонения значений от среднего
В результате этой операции будет получена новая величина, которая характеризует величину отклонения выборочного значения от среднего для каждого члена выборки. И значений этого отклонения – ровно столько же, сколько значений в выборке (отклонение рассчитано для каждого выборочного значения). Так же нам хочется понять, каково это отклонение в среднем, и хочется взять и усреднить полученные значения. Но в данном случае проблема заключается в том, что расчет среднего арифметического из значений отклонения даст 0. Просто по причине того, что среднее – это значение, «равноудаленное» от всех значений выборки. Выше было указано, что одно из свойств среднего – это то, что сумма отклонений всех выборочных значений от среднего равно 0. Из сложившегося неудобного положения можно найти два выхода:
– взять модуль (абсолютное значение) отклонений и усреднить их,
– возвести в четную степень полученные отклонения и усреднить их. Проще всего – возвести в квадрат.
Исторически сложилось так, что был выбран второй вариант – просто потому, что степенная функция является дифференцируемой во всей области определения, а модуль – нет. Для статистических расчетов, более сложных, чем обычно используются в геологии, необходимо, чтобы была возможность без лишних проблем интегрировать и дифференцировать функции. В этом отношении степенная функция значительно «удобнее», чем модуль. Поэтому мы имеем в качестве величины, характеризующей разброс данных, усредненную сумму квадратов отклонений.
Итого: чтобы не получить ноль при усреднении отклонений, требуется использовать квадрат величины отклонения. То есть выборочной дисперсией называется величина, рассчитанная по формуле:

Формула для оценки дисперсии выборки
То есть выборочная дисперсия – среднее из квадратов отклонения случайной величины от ее среднего значения.
Считается (и доказывается в классических статистических работах), что выборочная дисперсия является смещенной оценкой дисперсии генеральной совокупности. Для оценки дисперсии генеральной совокупности используется чуть более сложная формула:
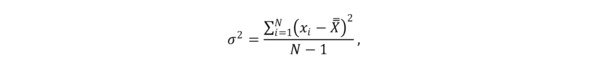
Формула для оценки дисперсии генеральной совокупности
Выше мы с помощью несложных логических рассуждений вывели формулу дисперсии. Было бы нелишним понимать смысл этой формулы, но строгого запоминания этих формул не требуется, поскольку они заложены во всем ПО, работающем с данными (по крайней мере, авторам не встречалось ПО, где бы эти формулы не были заложены).
Выше приведены две формулы расчета дисперсии. Необходимо обратить внимание на то, что в задачах моделирования практически всегда мы имеем дело не с генеральными совокупностями, а со случайными выборками из генеральной совокупности. Поэтому мы не имеем точного значения дисперсии, а только ее оценку. В учебниках по математической статистике5 указано, что верхняя формула (где выполняется деление на численность выборки) дает смещенную оценку дисперсии, а нижняя (где деление выполняется на численность выборки минус 1) – несмещенную. Вторую формулу используют для оценки дисперсии генеральной совокупности.
Теперь о том, какую дисперсию считает ПО, которым мы имеем счастье пользоваться:
– Первым пунктом идет, естественно, великий и ужасный Excel6. В Excel существует две формулы для расчета дисперсии (на самом деле, больше, но глобально – две, остальные – это вариации на тему «использовать логические значения / не использовать логические значения»): ДИСП. В и ДИСП. Г. Причем вторая, как сказано в ее кратком описании, рассчитывает дисперсию генеральной совокупности. Вот, казалось бы, «щасстье привалило». Однако нет: ручная проверка показывает, что результат работы функции ДИСП. Г совпадает с формулой смещенной оценки. В чем же проблема? А проблема очень простая: функция ДИСП. Г считает, что то, что она получила на вход, это и есть генеральная совокупность. А при генеральной совокупности – таки да, надо делить на численность генеральной совокупности. Но у нас-то не генеральная! Хорошо, если генеральная совокупность выглядит как «непьющие мужчины за 40 деревни Чуево-Кукуево» – там вообще считать нечего. Но в моделировании мы практически всегда имеем дело со случайной выборкой. Поэтому функцию ДИСП. Г мы забываем, как страшный сон.
Вывод: Excel для выборочной дисперсии (ДИСП. В) приводит ее несмещенную оценку.
– Google таблицы7 – аналогично: функция VAR рассчитывает несмещенную оценку, функция VARP совершенно аналогична ДИСП. Г Excel.
– Datamine. Дает смещенную оценку.
– Snowden Supervisor. Дает смещенную оценку.
– Micromine. Дает несмещенную оценку.
– Leapfrog. Дает несмещенную оценку.
И вот вы прочитали предыдущие 6 пунктов и сидите в ужасе: «Чему верить?» А в общем, ничего страшного в описанной ситуации нет. Заметим, что при росте объема выборки (и соответственно, приближении ее к генеральной совокупности) разница между оценкой выборочной дисперсии и дисперсии генеральной совокупности уменьшается (ну просто потому, что разница между делением на 10 и 11 вполне ощутима, а на 10000 и 9999 – почти нет). Ниже представлен график разницы между смещенной и несмещенной оценкой для выборок различного объема, созданных с помощью генератора случайных чисел.
Выборка сгенерирована с помощью генератора случайных чисел (в генератор заложена дисперсия 10), поэтому абсолютные цифры могут несколько «гулять», но тенденция видна невооруженным глазом: при численности выборки более ~100 наблюдений разница между смещенной и несмещенной оценками падает ниже 1% от дисперсии (кстати, на втором листе файла Excel, ссылка на который была чуть выше, эти формулы заложены – можете поиграть с ними). Учитывая обычные объемы выборок для моделирования, можно не забивать себе голову вопросами «это смещенная или несмещенная оценка?».
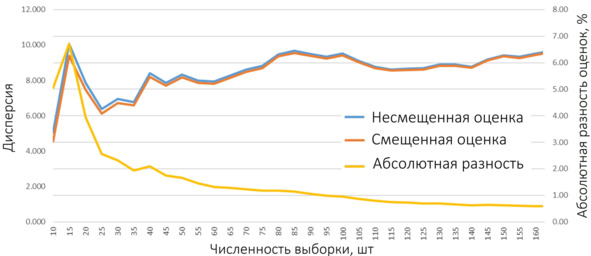
График разницы между смещенной и несмещенной оценкой для выборок различного объема
Стандартное отклонение и коэффициент вариации
Глядя на формулу дисперсии, можно понять, что единицы измерения дисперсии – это квадраты тех единиц, в которых измеряется исследуемая величина. Во многих случаях это немного неудобно, поэтому имеет смысл взять квадратный корень из этой величины. Полученное значение принято называть среднеквадратичным отклонением или стандартным отклонением. Единицы измерения стандартного отклонения совпадают с единицами измерения исследуемой величины.
При работе с данными довольно часто мы имеем дело с разнопорядковыми величинами, часто еще и измеренными в разных единицах или несущих разный физический смысл. При этом время от времени возникает горячее желание сопоставить между собой разброс двух величин, имеющих разное среднее и зачастую измеренных в разных единицах. Для решения такой задачи требуется некая, видимо, безразмерная величина, которая должна показывать то, насколько разброс данных больше его среднего. То есть, например, отношение стандартного отклонения к среднему по выборке.
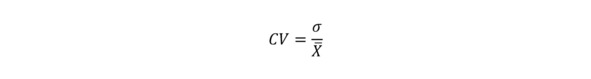
Формула коэффициента вариации
Эта величина называется коэффициентом вариации. Эта величина безразмерная (в том смысле, что не имеет «нормальных» единиц измерения – типа сантиметров, тонн или джоулей): и в числителе, и в знаменателе дроби присутствуют величины, измеряющиеся в одинаковых единицах. Коэффициент вариации может измеряться в долях единицы, а может в процентах (разница между «тем и этим» – 100). Коэффициент вариации характеризует степень изменчивости, «неустойчивости», «непостоянства» исследуемой величины. Он может быть использован для сравнения степени изменчивости различных величин – например, содержания металла и сквозного извлечения. Также он используется при проверке того, можно ли использовать кригинг для интерполяции. Считается, что коэффициент вариации больше 2 (или 200%) препятствует удачному использованию кригинга и требуются некоторые действия для его уменьшения – например, ограничение аномальных значений (урезка ураганов) или изучение вопроса об однородности выборки.
Общепринятого ранжирования величин по степени изменчивости на основе коэффициента вариации нет. В советское время предлагалось ранжировать выборки от весьма слабой изменчивости к весьма сильной по реперным значениям коэффициента вариации 0.2—0.4—0.8. По опыту работы с данными опробования золоторудных объектов можно сказать, что подавляющее большинство рудных выборок имеют коэффициент вариации содержаний не менее 0.8 (80%). Очень часто он превышает 2.
§ Задание 1.1
Для выборки значений содержаний проб:
0, 0.2, 0.6, 0.9, 0.9, 1.4, 1.6, 3
рассчитайте:
– Среднее.
– Мода.
– Медиана.
– Дисперсия (несмещенная).
– Стандартное отклонение.
– Коэффициент вариации.
Ответы округлите до двух знаков после запятой.
§ Задание 1.2
Скачайте8 выборку значений содержаний проб и рассчитайте:
– Среднее.
– Мода.
– Медиана.
– Дисперсия (несмещенная).
– Стандартное отклонение.
– Коэффициент вариации.
Ответы округлите до двух знаков после запятой.
Диаграмма накопленной частоты
Кроме гистограммы, классическим вариантом диаграммы, характеризующей выборку, считается также диаграмма накопленной частоты. Диаграмма накопленной частоты может быть построена как на сгруппированных данных, так и на не сгруппированных.
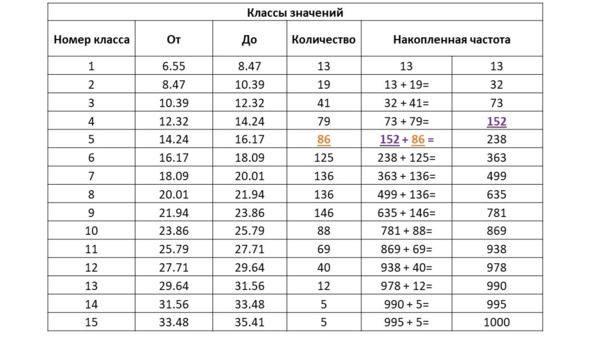
При построении диаграммы накопленных частот по сгруппированным данным выполняется разбиение всего диапазоны на классы (аналогично тому, как это делается для гистограммы), классы ранжируются по возрастанию, затем для каждого класса суммируется количество данных, попавших в этот класс с количеством данных, попавших во все классы, «ниже» данного. То есть частота данных в каждом классе накапливается от «низов» выборки до ее «верха». В качестве примера рассмотрим некоторую величину, распределенную следующим образом:
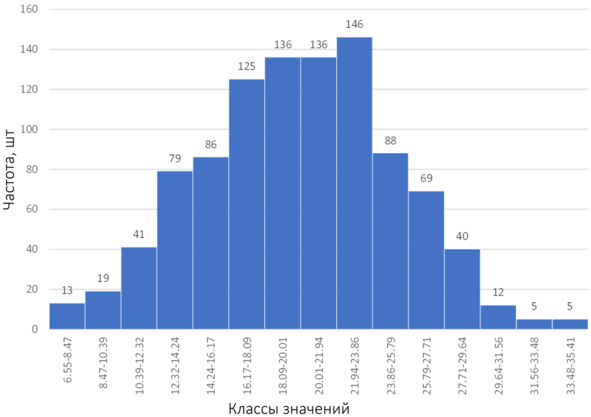
Пример распределения
В табличном виде это распределение можно представить следующим образом:
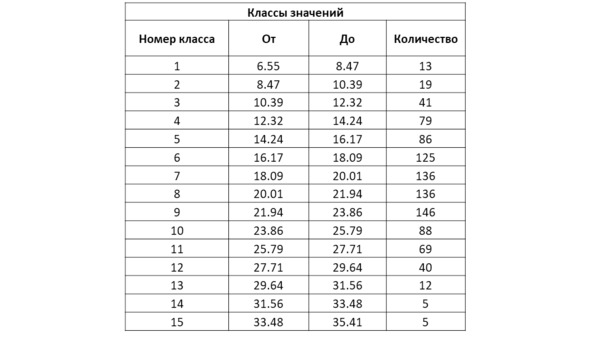
Выполним расчет накопленной частоты для приведенного примера:
И теперь – построение графика:
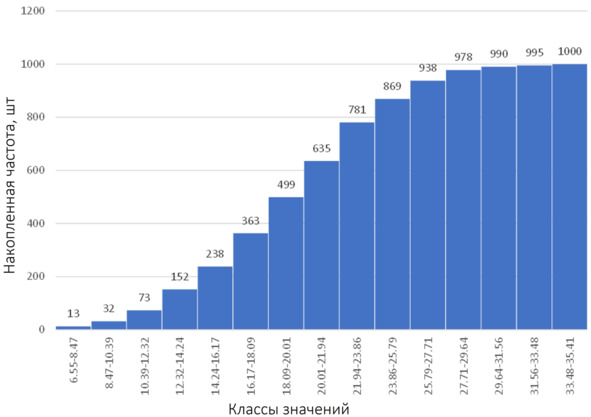
Диаграмма накопленных частот
При построении диаграммы накопленных частот по не сгруппированным данным последовательность действий чуть другая:
– Данные ранжируются по возрастанию.
– Составляется ранжированный ряд уникальных значений.
– Для каждого уникального значения подсчитывается частота встречаемости.
– Для каждого уникального значения подсчитывается накопленная частота: частота встречаемости этого значения плюс частоты всех значений более низкой величины. То есть в данном случае в качестве классов значений (как в варианте со сгруппированными данными) выступают уникальные значения исследуемой величины.
График накопленных частот для того же распределения, что и выше по не сгруппированным данным, представлен на рисунке ниже.
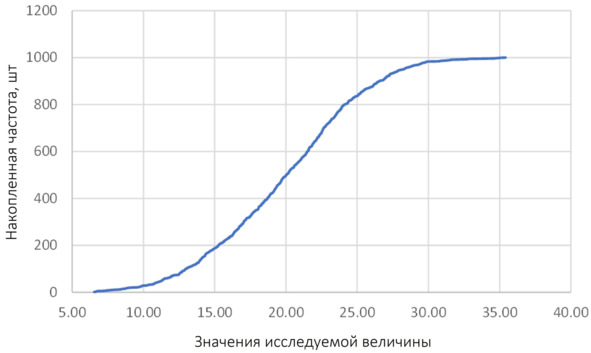
График накопленных частот по не сгруппированным данным
Коэффициент асимметрии
При построении гистограмм можно получить график как симметричный, в котором больших и малых значений «примерно поровну», так и асимметричный – с преобладанием высоких или низких значений. Для условий данных опробования цветных или драгоценных металлов асимметричный график встречается намного чаще симметричного. Логично, что нужна некая точная характеристика асимметрии, которая позволила бы избежать волюнтаризма в определении степени асимметричности выборки. Так давайте же сконструируем такую характеристику.
Итак, у нас есть набор выборочных значений, основная масса которых группируется «слева» или «справа». Логично задать себе вопрос: слева или справа от чего? Видимо, от среднего арифметического. То есть, если мы попытаемся рассчитать разность (Xi – Xсреднее), то среднее подобных разностей должно бы нам показать направление и величину отклонений выборочных данных от среднего. Возможно, должно, но не будет: сумма подобных разностей всегда будет нулевой – по механизму расчета среднего. Казалось бы, можно возвести в квадрат – как это делалось для расчета дисперсии. Но проблема в том, что знак разности (Xi – Xсреднее) нужен (мы ж хотим понимать – значение ушло «влево» или «вправо» от среднего), а при возведении в квадрат знак «потеряется». Логично тогда использовать нечетную степень – она позволит избежать обнуления суммы разностей, с одной стороны, и «не потеряет знак» разностей – с другой. Первая нечетная степень – 3. То есть логично рассчитать среднее арифметическое кубов разностей. Также хотелось бы, чтобы конструируемая величина допускала сравнение асимметрии распределений разнородных данных, возможно, даже измеренных в разных единицах. То есть эта величина должна быть безразмерной – как сконструированный ранее коэффициент вариации. И кажется вполне логичным, что наше среднее должно быть нормировано на стандартное отклонение – т. е. показывать, во сколько раз асимметрия выборки больше, чем характеристика ее размаха. Ну, а учитывая то, что:
– хочется получить безразмерную величину,
– стандартное отклонение имеет те же единицы измерения, что и выборочные данные,
– мы уже рассчитали среднее из кубов разностей,
становится понятным, что необходимо выполнить возведение в куб также и величины стандартного отклонения. Итоговая величина будет рассчитываться по формуле:
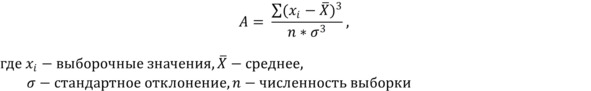
Полученная величина называется коэффициентом асимметрии или просто асимметрией. Коэффициент асимметрии показывает, куда и насколько сильно смещено среднее выборки относительно максимальной частоты распределения. В случае нулевого (или близкого к нулю) коэффициента асимметрии распределение симметрично и «высоких» значений примерно столько же, сколько «низких». В этом случае среднее и медиана выборки близки либо вообще равны.
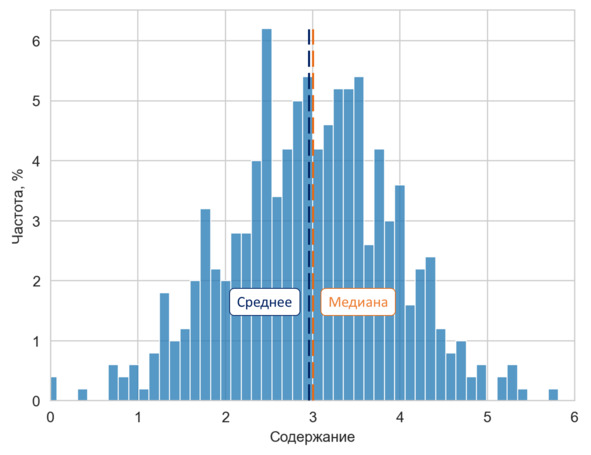
Распределение с близким к нулю коэффициентом асимметрии
В случае отрицательного коэффициента асимметрии «высоких» значений больше, чем «низких». Среднее ниже медианы, то есть по оси значений смещено влево. В этом случае говорят, что распределение случайной величины имеет левую или отрицательную асимметрию.
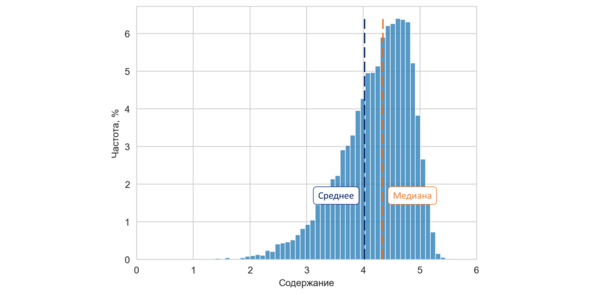
Распределение с отрицательным коэффициентом асимметрии
В случае положительного коэффициента асимметрии картина прямо противоположна: «низких» значений больше, чем высоких, среднее смещено относительно медианы вправо (помните пример с жадным директором предприятия? – добавьте к этому «нехорошему» человеку его зама, главбуха, еще парочку топ-менеджеров и получите правоасимметричное распределение зарплат).
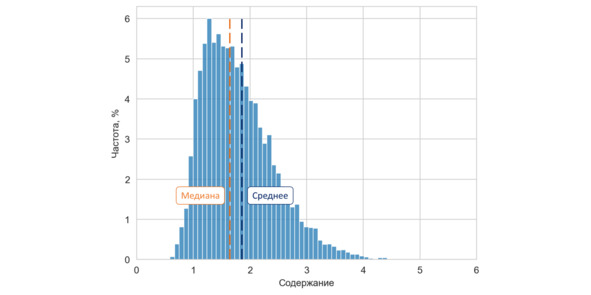
Распределение с положительным коэффициентом асимметрии
