


Полная версия
Базовая оценка минерализации. Ресурсный геолог
# Пример из практики
Пример, аналогичный предыдущему, только теперь на месторождении серебра.

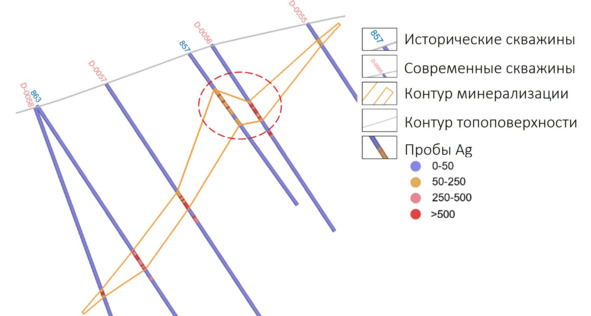
Контур минерализации по сети 100х100
После построения модели по историческим данным были начаты работы по сгущению сети. Для нескольких скважин было выполнено заверочное бурение, заключавшееся в бурении новых скважин в непосредственной близости от заверяемых. Заверке подверглись 8 скважин. В результате выполненных работ по 5 скважинам было обнаружено несоответствие данных предыдущих периодов современным, выраженное в ощутимом смещении границ ранее построенных зон минерализации.
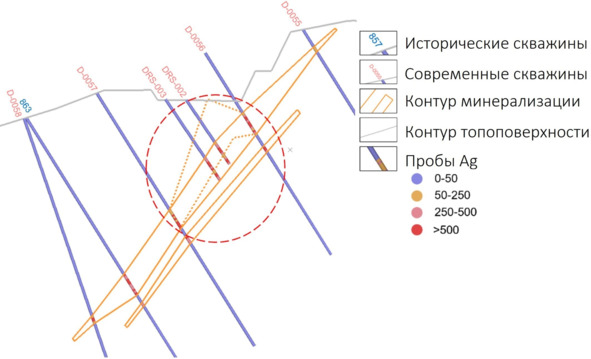
Контур минерализации по сети 50х50 м
Геологи проигнорировали несоответствие между современными и историческими данными и отстроили контур минерализации с использованием всех данных. Но внезапно с началом выполнения сопровождающей эксплуатационной разведки минерализация в ожидаемых местах не была вскрыта.

Неподтверждение ранее отстроенного контура минерализации
И только после того как выявленное и проигнорированное несоответствие в данных привело к проблемам при добыче, было принято решение выполнить анализ соответствия исторических и современных данных. Анализ показал, что по части скважин предыдущих периодов не совпадают не только пространственное положение минерализованных зон, но и содержания.

Анализ содержаний в современной и исторической скважинах
По результатам выполненного сопоставления было принято решение исключить из рудной выборки исторические скважины с неподтвержденными данными и провести перемоделирование в соответствующих участках. Там, где расхождений выявлено не было, исторические данные не исключались.
Неподтверждение ранее отстроенного контура минерализации
В данном случае все кончилось относительно благополучно, если не считать неверно рассчитанных календарных планов отработки, предполагаемого получения прибыли, времени, потраченного на поиск и устранение проблем, а также нервов всех вовлеченных в эту поучительную историю.
# Пример из практики
Месторождение золота, представленное кварцевыми жилами с крайне высоким содержанием. Жилы сопровождаются зонами дробления и прожилкования, а также метасоматической проработки. Мощность стержневых жил составляет первые метры, зон околожильных изменений – до 10—15 м.
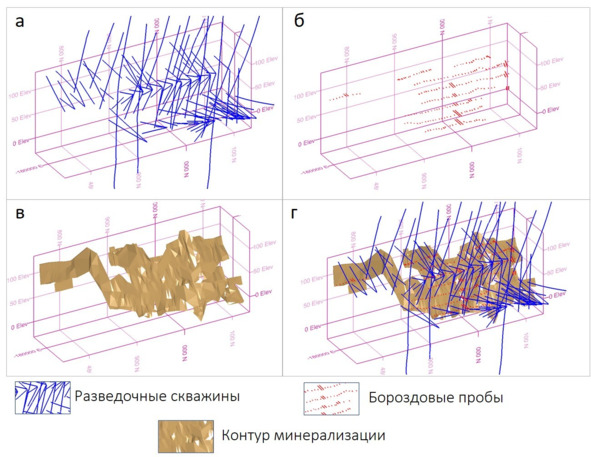
a – разведочные скважины, б – бороздовые пробы, в – контур минерализации, г – общий вид
Месторождение отрабатывалось подземным способом с 50-60-х годов предыдущего века. В текущем столетии изучалось скважинами колонкового бурения по сети ~20—25×20—25 м (на флангах – реже). Историческое опробование представлено довольно объемным массивом бороздовых проб, отобранных по горизонтам подземных выработок с шагом ~2—3 м. Основная проблема исторического опробования заключается в том, что опробованию подвергались главным образом стержневые жилы с высокими содержаниями (20—30 г/т, зачастую выше), а зоны дробления и метасоматической проработки пристального внимания не удостаивались. Современные данные представлены результатами анализов кернового опробования, отобранного по всей минерализованной зоне (стержневая жила + зальбанды). Несложно догадаться, что в настоящее время промышленный интерес представляют не только стержневые жилы, но и зоны околорудных изменений.
Проблема в том, что современных данных, по сравнению с историческим опробованием, не так чтобы очень много: по минерализации, представленной на рисунке выше, более 60% массива опробования составляют бороздовые пробы, а керновые – соответственно, не более 40%. Причем приведенный пример – не самый «страшный» – бывают случаи, когда доля исторических данных составляет около 80% массива опробования.
Моделирование «в лоб» по всему массиву данных и последующая отработка всей массы минерализованных пород ожидаемо привело к факту «неотхода» металла на фабрике.
И вот здесь начинается самое интересное. Во-первых, не очень понятно, как сопоставлять исторические данные с современными. Просто сравнить полностью выборку современных данных и полностью выборку исторических данных – не вариант, учитывая схему опробования. Любые попытки подобного сопоставления дают совершенно ожидаемый результат завышения содержаний в данных предыдущих периодов.
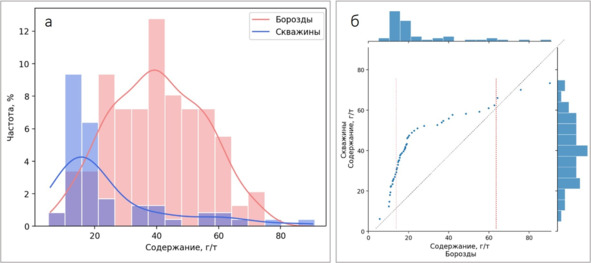
а – гистограмма, б – график квантиль-квантиль
И в данном случае непонятно: то ли причина завышения – принципиальные различия в схеме опробования, то ли действительно имеет место завышение. Или обе причины. Выделить сопоставимые части не представляется возможным: как было сказано чуть выше, основная масса проб – это пробы из стержневых жил. Однако пробы из околожильных пород тоже присутствуют, беда в том, что непонятно, в каком соотношении: литологическая характеристика в исторических данных отсутствует. То есть понятно, что проб из околожильного пространства существенно меньше, но насколько? Опять же, есть опробование из зальбандов, сколько его – непонятно, но в любом случае историческими данными вся зона минерализации почти нигде не пересечена. И что делать? Просто выбросить исторические бороздовые пробы? Мы сразу лишаемся 60% данных опробования. Неприятно, однако.
Сопоставлять ближайшие пробы? Хорошо, если часты случаи, как на рисунке ниже.
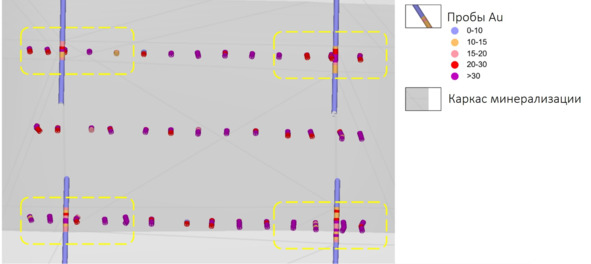
Выбор бороздовых проб для анализа содержаний
Но чаще всего так не получится: борозды отбирались по горизонтам выработок, а разведка скважинами запроектирована таким образом, чтобы освещать пространство между горизонтами. Соответственно, между ближайшими пробами может быть и 5, и 10 м, и мы возвращаемся в исходную точку.
Можно, конечно, сделать вид, что все прекрасно, никакого завышения нет, и пытаться моделировать по всей выборке. Результат такого моделирования приведен выше – неотход металла на фабрике. И причина понятна – бороздовые пробы «задавливают» массой: поисковый эллипсоид набирает максимум из исторических данных, а современные игнорируются.
В общем, что делать – непонятно. К сожалению, однозначного окончательного решения у этой проблемы нет. Варианты есть, но они все не идеальны:
– Введение понижающего коэффициента. Самый простой способ и, наверное, самый «лежащий на поверхности». Но в итоге мы получаем новую искусственную величину, которая ведет себя довольно непредсказуемо в разных частях одного и того же месторождения. Понижающий коэффициент может несколько сгладить очевидное неподтверждение содержаний (а при избыточном усердии даже привести к переотходу металла), но эффект от его применения скорее психологический (ну что-то же делать надо!). В общем, на наш взгляд, путь откровенно тупиковый. Вообще, любое введение искусственных понижающих/повышающих и прочих коэффициентов, не имеющих никакого обоснования, кроме «давайте подгоним», – это тупиковый путь.
– Постепенное разбуривание минерализации скважинами и создание плотной регулярной сети данных. Идеальный вариант, если бы не одно «но»: данные нужны «вотпрямщас», поскольку отработка уже идет.
– Попытка выделять внутри минерализации домены стержневых жил, опираясь только на содержания с последующей интерполяцией раздельно по жилам и околожильным породам. Тоже очень неплохой вариант. На бумаге. На практике также начинают «вылезать» проблемы с определением граничного содержания для стержневой жилы и т. д.
Описанная ситуация является почти типичной на месторождениях Северо-Востока России, изучение которых началось в «глубоко советское» время. Очень часто здесь массив исторических данных представляет собой эдакий «чемодан без ручки»: и использовать невозможно, и выбросить жалко. В каждом конкретном случае решение чаще всего принимается волевым порядком, сопровождается довольно ощутимыми рисками, а специалист, принявший это решение, впоследствии зачастую имеет полный набор бодрящих последствий.
Общий статистический анализ одной величины
Прежде чем переходить к обсуждению темы, заявленной в заголовке, дадим краткое пояснение. По мнению авторов, понимание смысла терминов и смысла формул намного важнее, чем механическое заучивание определений и формул без их смыслового наполнения. Поэтому в ряде случаев будут использованы методы объяснения, очень далекие от наукообразности и не выдерживающие никакой критики с точки зрения высокой статистики. Но зато, надеемся, позволяющие понять суть объясняемых терминов. Строгие академические определения желающие смогут найти в справочниках и учебниках по статистике.
Генеральная совокупность и выборка
Первое, что необходимо обсудить в рамках настоящей главы, это такие понятия, как выборка и генеральная совокупность.
Выборка – это любой набор данных, имеющихся в распоряжении исследователя. Это может быть набор данных опробования по отдельному горизонту, по отдельному рудному телу, группе тел, участку месторождения или всему месторождению целиком. Или просто случайно попавший в руки геолога отдельный журнал опробования. То есть выборка – это тот реальный набор данных, который есть в распоряжении геолога.
Генеральная совокупность – некая математическая абстракция, это выборка, которая содержит все возможные значения некоторой величины для данного объекта. То есть это «все возможные данные». Например, генеральной совокупностью можно считать данные о содержании какого-либо компонента в каждой точке рудного тела (генеральная совокупность содержаний по данному рудному телу), участку месторождения (генеральная совокупность содержаний по участку месторождения). Из подобного «определения» становится ясно, почему генеральная совокупность – это абстракция: просто потому, что в большинстве случаев она недостижима. Даже обладая бесконечным финансированием, невозможно получить содержания в каждой точке рудного тела/участка/месторождения.
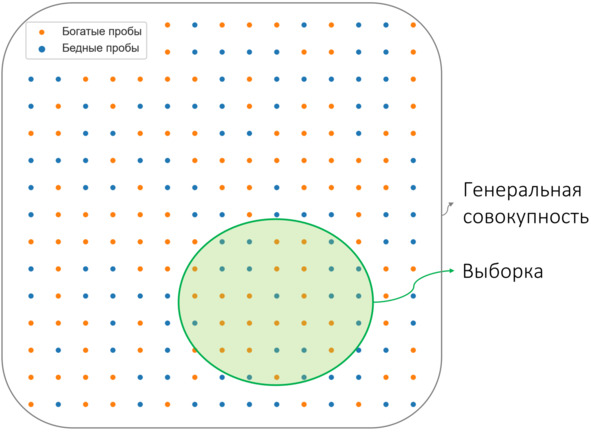
Генеральная совокупность и выборка
Выборка может характеризовать генеральную совокупность «хорошо» или «плохо», то есть быть представительной (репрезентативной) или непредставительной (нерепрезентативной). Представительностью принято называть характеристику, которая показывает то, насколько хорошо выборка, имеющаяся в распоряжении геолога, отражает реальные статистические характеристики изучаемого объекта. Представительность – бинарная характеристика: она либо есть, либо ее нет. Например, выборка бороздового опробования по одному горизонту крупного рудного тела, скорее всего, «плохо» характеризует генеральную совокупность содержаний данного тела. Выборка, отобранная из какого-то локального участка рудного тела, скорее всего, тоже будет непредставительной (даже если проб там «много»).

Непредставительные выборки
Напротив, данные опробования этого тела, отобранные по регулярной сети (вопрос о плотности сети, позволяющей получить представительную выборку, решается в каждом случае индивидуально), скорее всего, являются представительными для данного тела (но, скорее всего, непредставительными для всего месторождения). Поэтому при заявлении «эта выборка является представительной» неплохо бы уточнять, представительной для чего.
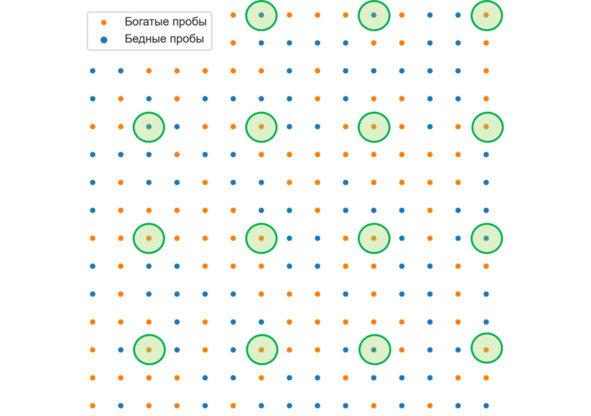
Представительные выборка
Гистограмма
В большинстве случае объем выборки таков, что ее невозможно всю «охватить взглядом». Однако желание понять, что из себя представляет тот массив данных, который есть в распоряжении, возникает сразу же после появления этого массива. И одним из наилучших способов получить это понимание является графический, поскольку подавляющее количество информации человек получает с помощью зрения. Просто просмотр числовых значений при большом объеме выборки мало что дает, поэтому хочется как-то «генерализовать» всю эту информацию. Для такой генерализации и визуального представления существует очень полезный вид диаграмм, называемый гистограммами. Гистограммы представляют собой столбчатый график, в котором по горизонтали отложены значения изучаемой величины, по вертикали – частота встречаемости значений, а все данные сгруппированы в то или иное количество классов содержаний равной величины и представлены, соответственно, столбцами. Равенство классов в данном случае означает равенство разброса содержаний (не количества наблюдений!) в каждом классе.

Гистограмма
Методика построения гистограммы проста и незамысловата:
– Определяем размах изучаемой величины.
– Решаем, на какое количество классов содержаний будем разбивать наши данные. Количество классов содержаний – это количество столбцов на создаваемой гистограмме (точнее, максимальное количество столбцов). Например, мы определили, что размах содержаний составляет 100 г/т – от 0 г/т до 100 г/т. Далее мы захотели разбить весь диапазон на 10 классов содержаний (о выборе количества классов содержаний чуть дальше). В этом случае границы классов будут следующими: от 0 до 10 г/т, от 10 до 20 г/т, от 20 до 30 г/т… от 90 до 100 г/т.
– Для каждого класса содержаний подсчитываем количество проб, попавших в класс. При подсчете обычно в класс включают нижнюю границу – т. е. содержание 10 г/т войдет в класс от 10 до 20 г/т, а не в класс от 0 до 10 г/т. Хотя возможна и обратная схема. Но в любом случае – схема включения граничных содержаний должна быть едина, и каждая проба должна быть учтена только в одном классе.
– На оси абсцисс (горизонтальной, если забыли) отмечаем границы классов, на оси ординат (вертикальной) размечаем масштаб. И для каждого класса содержаний строим прямоугольник, такой, что вертикальные стороны совпадают с границами классов, а высота равна количеству проб в данном классе с учетом выбранного масштаба. В итоге должно получиться что-то, похожее на диаграмму, приведенную выше (с учетом особенностей используемого распределения).
Можно вместо натуральных величин частоты (т. е. «штук») использовать долю проб в данном классе от общего количества проб – количество проб не всегда информативно. Характер гистограммы от этого не изменится, поменяется только вертикальный масштаб.
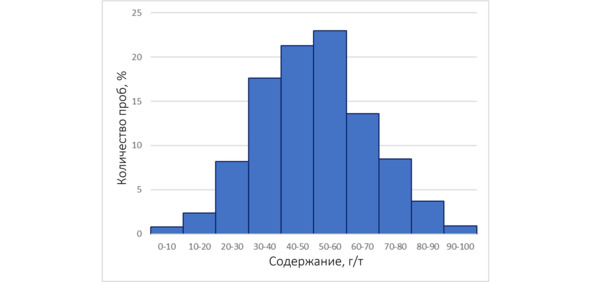
Гистограмма
Если длина проб резко различна, то имеет смысл использовать взвешивание – в этом случае на длину пробы. Случается, что визуально видимую минерализацию опробуют более детально – секциями меньшего размера, тогда как слабо проявленные околорудные изменения – более длинными пробами. Гистограмма, построенная по количеству проб, в этом случае неправильно отражает характер распределения содержаний, и вместо количества проб в каждом классе в этом случае лучше подсчитывать суммарную длину проб. То есть в данном случае имеет смысл выполнять взвешивание на длину. Сравните две гистограммы ниже. Они построены по одним и тем же данным. Но гистограмма слева построена без взвешивания на длину, а справа – со взвешиванием. Очевидно, характер гистограмм несколько различен.

Гистограмма без взвешивания (слева) и со взвешиванием на длину пробы (справа)
Взвешивание также имеет смысл выполнять при наличии участков, освещенных сетями разной плотности. В этом случае взвешивание должно выполняться на так называемый вес декластеризации (об этом чуть дальше).
Гистограмма – довольно удобный инструмент, который легко позволяет получить представление о характере распределения значений исследуемой величины по диапазону значений. По внешнему виду гистограммы можно судить о том, является ли выборка однородной или нет. Под однородностью понимается принадлежность всех значений изучаемой величины к одной и той же генеральной совокупности. Обычно однородные выборки одномодальные – т. е. на гистограммах таких выборок присутствует только один «горб». Наличие нескольких таких «горбов» может говорить о том, что в выборку попали значения, имеющие разную природу: например, пробы из стержневой жилы и зоны околорудных изменений или из минерализованных зон разных стадий рудообразования с разной продуктивностью. Или из первичных руд и из зоны окисления – причин может быть масса. Однако кроме естественных причин могут быть и причины технического характера.
Выше при объяснении механизма построения гистограммы было сказано, что диапазон значений разбивается на некоторое количество классов содержаний. Однако ничего не было сказано о том, как выбирается количество классов. Вопрос о количестве классов, на которые разбивать диапазон значений, не имеет однозначного ответа. «Классическим» вариантом разбивки на классы считается формула Стерджесса.
Количество классов ≈ 1 +3.22 * lg (N),Здесь N – численность выборки, lg – десятичный логарифм.
Формула является эмпирической, т. е. ее единственное обоснование: «всегда так делали, и хорошо получалось».
Основной недостаток этой формулы – слишком малое количество классов, которое на больших выборках зачастую не позволяет увидеть важные особенности. Рост количества классов полностью объясняется особенностью поведения логарифма: сначала относительно быстрый рост, а затем замедление. На рисунке ниже можно увидеть зависимость между численностью выборки и количеством классов, определенных согласно этой формуле.
Выборку в 100 тыс. записей данное правило рекомендует разбить на 18 классов, в 200 тыс. – на 19, в 1 млн – только на 21. При построении гистограмм в соответствии с данной формулой можно увидеть только что-то очень явное, что чаще всего «и так понятно».

Зависимость между численностью выборки и количеством классов
Эта особенность применяемого правила, скорее всего, объясняется тем, что во времена создания «классической» статистики обычная численность выборки составляла несколько сотен замеров. В настоящее же время объемы выборок принципиально возросли и применение этой формулы может быть не вполне оправдано.
Обычно количество классов подбирается таким образом, чтобы на гистограмме были видны важные особенности, но при этом гистограмма продолжала бы быть похожей на гистограмму, а не на творение художника-абстракциониста или на картинку с одинокими столбцами, разделенными «белым безмолвием». Обычно количество классов не превышает 50 (для выборок объема в несколько десятков тысяч значений). При избыточном количестве классов на небольших выборках очень несложно обнаружить неоднородность, обусловленную исключительно разбиением на классы. На рисунке ниже представлена гистограмма, построенная для выборки в 1000 записей, представляющих собой сгенерированное однородное (нормальное) распределение со средним 20 и стандартным отклонением 5. N для данного рисунка – количество классов разбиения.
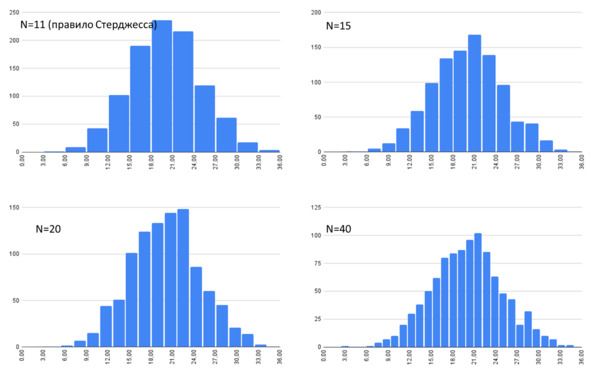
Гистограммы с различным количеством классов разбиения по выборке в 1000 записей
Можно видеть, что для выборки в 1000 значений при количестве классов, существенно превышающем правило Стерджесса, появляется ложная неоднородность (второй «горб») с границей в районе 28.
В то же время при достаточно большом количестве наблюдений получить искусственную неоднородность уже довольно сложно. На рисунке ниже показана аналогичная выборка, но с числом наблюдений 10000. То есть для выборки в 10000 наблюдений даже при десятикратном превышении правила Стерджесса явной неоднородности не отмечается. Нижняя граница численности выборки, после которой можно не очень опасаться искусственной неоднородности, вероятно, находится на уровне 4—5 тыс. наблюдений (в принципе, не очень большая редкость для геологии). При меньшем количестве классов, вероятно, не стоит кратно превышать те цифры, которые дает правило Стерджесса.

Гистограммы с различным количеством классов разбиения по выборке в 10000 записей
Среднее арифметическое
Генеральная совокупность в подавляющем большинстве случаев недостижима. Вы в своей работе будете всегда иметь дело с выборкой. У выборки, как и у генеральной совокупности, есть свои характеристики. В том случае, если выборка очень небольшая – например, 5-7-10 значений, вы можете видеть ее всю целиком, и никаких дополнительных характеристик выборки вам не нужно. Однако традиционно в геологии (и моделировании) вы будете иметь дело с выборками объемом в десятки, сотни и тысячи значений. Впрочем, и выборки в миллионы значений также не являются сугубо экзотичными. Поскольку физически невозможно держать эту выборку «в поле зрения», возникает необходимость каким-либо образом охарактеризовать ее относительно небольшим количеством величин, позволяющими получить представление о выборке без просмотра ее целиком.
Первое, что логично напрашивается – это минимальное и максимальное значения, а также размах. Если с минимумом и максимумом все понятно, то размах – это разница между максимумом и минимумом. То есть размах – это диапазон значений, полученных для данной выборки.
Следующая характеристика выборки – это выборочное среднее. Зачастую слово «выборочное» опускают и говорят просто о «среднем». Вообще говоря, существует довольно большое количество средних, однако чаще всего при упоминании «среднего» имеют в виду среднее арифметическое. Среднее (арифметическое) – это величина, которая рассчитывается по формуле, хорошо знакомой еще из школьного курса.
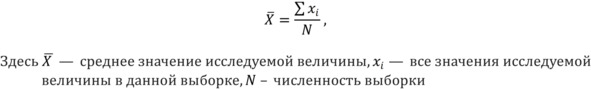
Формула расчета среднего
Например, среднее из 4, 10 и 19 равняется 11. То есть среднее – величина, промежуточная для реальных значений. Если рассматривать числа как точки на числовой прямой, то среднее – это точка «посередине» точек, соответствующих выборочным данным.
Среднее обладает некоторыми свойствами, также позволяющими лучше понять его смысл:
– если средней величиной заменить все значения выборки, то сумма значений выборки не изменится;
– если среднее значение вычесть из каждого значения выборки, то сумма этих разностей будет равна 0.
Необходимо отметить, что среднее (арифметическое) дает неплохое представление о выборке «симметричной», т. е. такой, в которой высоких и низких значений «примерно поровну». В том же случае, когда явно преобладают высокие или низкие значения, среднее дает смещенную оценку. Также на оценку среднего серьезное влияние оказывают значения, резко выделяющиеся из общей массы (причем неважно – в большую или меньшую сторону). В качестве примера можно рассмотреть коллектив небольшой организации, в которой 20 человек получают по 30 т. р., а генеральный директор – 2 млн. р. Очевидно, что среднее, равное для описанного случая, ~695 т. р., вряд ли корректно отражает ситуацию с уровнем доходов сотрудников организации – причем это справедливо как в отношении рядовых сотрудников, так и в отношении директора. Ну или можно рассмотреть известную шутку о том, что все посетители бара, куда заходит Билл Гейтс, мгновенно в среднем становятся миллионерами (правда, счастье длится ровно до того момента, пока этот уважаемый человек не покинет бар). Вопрос о методах выявления и компенсации аномальных значений в выборке – не самый простой и будет относительно подробно рассмотрен в главе, посвященной урезке ураганных содержаний.
