


Полная версия
Большие данные, цифровизация и машинное обучение для собственников и топ-менеджеров, Или как зарабатывать больше с помощью информации
Остается еще вопрос этики: как собрать все необходимые данные о производстве и сотрудниках так, чтобы они этого не замечали, чтобы им было безразлично, ведется ли учет каждого их движения или нет. Единственный способ осуществить это – сделать процесс полностью автоматическим, чтобы сотрудник не заносил данные в компьютер вручную и даже не писал цифры серийного номера на детали. Все это должна делать машина, и неважно, каким именно способом: выбивать цифры или выжигать лазером QR-код. Главное, чтобы все происходило автоматически.
Отделение квалификации и качества
Отделение квалификации и качества проверяет качество услуг и товаров, производимых компанией. Если оно низкое, то принимаются необходимые меры, к примеру, персонал отправляют на повышение квалификации. Указанное отделение непрерывно получает отзывы клиентов, собирает информацию об их впечатлениях от продукта или услуги. Затем на основе этих данных товары улучшаются, поступают на рынок и PDCA цикл Деминга (планирование-действие-проверка-корректировка) повторяется вновь.
В современных компаниях, которые давно провели цифровизацию, отзывы не собираются и не анализируются вручную, потому что это рутинная работа. Поручать ее человеку – это непростительно дорогое удовольствие. Тем более что программа может обрабатывать миллионы отзывов в сутки, тогда как рядовой сотрудник только десятки или сотни. А если отклики не приходят на определенный почтовый адрес или не принимаются через форму жалоб на сайте производителя, то собирать их приходится по всему интернету. Что еще больше говорит о необходимости в программном анализе информации.
Рассмотрим интересный случай, который произошел с крупной южнокорейской компанией Samsung. В нашей стране она в первую очередь знаменита своими сотовыми телефонами и бытовой техникой. Однако в действительности эта компания намного больше, чем мы себе представляем, и она производит очень широкий ассортимент товаров, среди которых есть даже крупнотоннажные грузовые корабли. При таком разнообразии продукции сбор отзывов и их систематизация представляют собой крайне трудоемкий процесс, которым в основном занимаются машины. То есть программа просматривает в интернете все страницы всех социальных сетей, чтобы определить, появились ли новые сообщения с упоминанием продуктов бренда. Несмотря на то, что мониторинг происходит автоматически, процесс этот все же довольно медленный, да и компьютер иногда пропускает нужные отзывы, если в них отсутствуют «правильные» контрольные слова.
Недавно Samsung зарегистрировала неблагозвучный для русского уха бренд Gnusmas[9], название которого представляет собой перевернутое Samsung. Возможно, производитель не знал, что в нашей стране это слово стало довольно популярным и используется в негативном ключе, в том числе в качестве нарицательного для отзывов о неудачных продуктах рассматриваемой нами компании. А теперь представьте, что произойдет, если Samsung официально попросит всех владельцев ее устройств использовать слово Gnusmas в качестве ругательства, чтобы выражать недовольство продуктами компании на просторах интернета. Очевидно, что с наличием контрольного слова поиск и обработка отзывов, оставленных во всемирной паутине, будут занимать намного меньше времени. Благодаря чему отдел качества сможет быстрее получать обратную связь от пользователей, и данные станут точнее. Наличие такого слова-метки в интернет-публикациях – бесценная находка для компании, позволяющая действительно улучшить выпускаемые ею продукты за счет анализа огромного количества реальных откликов.
К слову, обычно небольшие компании, у которых еще нет наработок в области искусственного интеллекта, используют сервисы «Google Alerts» или «Яндекс.Медиана» для обнаружения в интернете с помощью контрольных слов отзывов о своих товарах. Такие сервисы автоматически отправляют пользователю уведомление на почту, если в глобальной сети появляется заданное контрольное слово. То есть если у вашего товара достаточно уникальное название, можно настроить отслеживание прямо по нему и собирать обратную связь. Полученные отзывы необходимо классифицировать на положительные и отрицательные, определяя в каждом, какое преимущество или недостаток продукта озвучены как основные. В небольшой компании с этим может справиться один человек, но с ростом популярности продукта приходится создавать свой машинный интеллект для столь кропотливой и нудной работы. В любом случае без обработки и сбора больших данных по комментариям пользователей невозможно улучшить продукт и удовлетворить клиентов.
Отделение по работе с клиентами и партнерами
Именно в отделении по работе с клиентами и партнерами, в которое в том числе входит отдел по связям с общественностью, работают над тем, чтобы организация стала всемирно известной. И это действие напрямую влияет на стоимость привлечения новых клиентов.
Имидж создается различными способами: от публикаций в прессе до участия в общественных движениях, а иногда даже за счет обнародования некоторой закрытой информации с целью привлечения внимания партнеров и поиска клиентов-почитателей. Например, если компания собирает большие данные о своем продукте, то в публичный доступ может попасть часть уже обработанных сведений. Чтобы любители могли потренироваться в создании собственной системы для предсказаний, используя машинное обучение. Именно так и поступил «Сбербанк»[10], который выложил на соревновательную платформу Kaggle набор больших данных о недвижимости в России. Сейчас это один из самых популярных тренажеров, на котором учат будущих специалистов по данным на различных отечественных курсах по машинному обучению.
По опубликованному набору можно сразу понять, как профессионалы в банке относятся к большим данным. Достаточно взглянуть на количество параметров, рассматриваемых для каждой квартиры:
• Описание квартир – 14 параметров.
• Описание ближайшей недвижимости – 24 параметра.
• Макроэкономические факторы, касающиеся недвижимости, – 101 параметр.
• Дополнительное описание ближайшей недвижимости – 288 параметров.
Данные представлены в форме таблиц, где квартиры – это строчки, а их параметры – колонки. Подобный вид является обычным для больших данных. Именно такие таблицы затем передаются машине для обучения, цель которого – натренировать ее на предсказание цены квартиры в зависимости от значений параметров.
В опубликованном наборе данных часть параметров не зависит от времени: количество комнат, географическое положение дома, расстояние от квартиры до ближайшей атомной станции, музея и университета. Таких пунктов почти триста. То есть в таблицах будет три сотни колонок, описывающих каждую квартиру.
Стоит обратить внимание на то, что значения некоторых изменяющихся параметров могут записываться несколько раз в привязке ко времени. Например, уровень безработицы или рождаемости в стране в разные дни[11]:

В таких временных данных тоже содержится скрытая информация. Например, если пару лет назад резко снизилась безработица, а сейчас увеличилась рождаемость, то спрос на квартиры увеличится. Обычному человеку не под силу заметить такую тонкую взаимосвязь между всеми этими цифрами и предсказать их влияние на стоимость «однушки» на окраине столицы. А машина с легкостью определяет значимость и вклад каждого параметра в цену квартиры. После обучения она сможет предсказывать эту величину самостоятельно, принимая в расчет лишь значения параметров. Человек будет в буквальном смысле спрашивать машину: «Сколько, по твоему мнению, сейчас стоит квартира в 5 минутах ходьбы от атомной станции, в 10 минутах пешком от университета, если безработица сегодня составляет 5.6 %, а коэффициент рождаемости равен 2.3?» Натренированный алгоритм – результат машинного обучения – в ответ на такой вопрос выдаст конкретную стоимость квартиры.
Банк вряд ли многое потерял из-за публикации этой информации о недвижимости. Зато теперь во многих школах программирования по всему миру используют этот набор данных в качестве наглядной демонстрации для студентов возможностей машинного обучения.
С помощью больших данных можно привлечь интерес не только студентов, но и партнеров. Даже если компания не может напрямую делиться с ними собранной информацией, то всегда есть вариант создать предсказательный сервис, который будет использовать алгоритмы, обученные на этих данных. В таком случае партнерские системы отправляют запрос алгоритму и получают ответ в виде прогноза. Партнеры не видят всех таблиц данных, но, поверьте, они очень благодарны за доступ к подобному алгоритму (подробнее об этой схеме мы поговорим в разделе «Торговля большими данными»).
Таким образом, предоставив хотя бы ограниченный доступ к своим большим данным в каком угодно виде, можно улучшить имидж организации. Благодаря чему компания без финансовых вложений сможет снизить стоимость привлечения новых клиентов и удержания старых.
Отделение создания и построения компании
Отделение создания и построения компании выполняет функции найма и адаптации сотрудников. Оно анализирует организацию технологического процесса во всей компании с целью повысить эффективность каждого из отделов, комплектует подразделения сотрудниками, следя за тем, чтобы везде хватало рабочих рук. Именно отделение создания и построения компании часто отвечает за оборудование и связь между сотрудниками, а следовательно, и за формирование единой информационной системы предприятия (об этом в следующих главах).
В современных компаниях это отделение уже давно не использует бумажный документооборот, потому что найти хорошего сотрудника на сайте по поиску работы – это как найти иголку в стоге сена. Основная проблема в том, что на одного адекватного работника приходится сотня неподходящих. Точнее, статистика такова:
• 90 % кандидатов на работу вообще не отвечают на электронные письма.
• 5 % – не слышат, что им говорят на собеседовании, и не понимают, о чем их просят.
• 2 % – совсем неадекватные, агрессивные и т. п.
• 2 % – подходят на должность, компетентны, но их не устраивают условия.
• 1 % – подходят и согласны работать, отвечают требованиям, адекватны.
Из этой статистики видно, насколько несладко приходится специалистам по подбору кадров при создании и построении компании. Целых 90 % работы проделывается впустую. Поэтому в этой сфере уже давно применяются алгоритмы автоматического поиска сотрудников. Специальные программы анализируют тексты резюме кандидатов и выявляют среди них наиболее подходящие. После чего другая программа вступает в переписку с отобранными кандидатами. И если те отвечают хотя бы на несколько вопросов-предложений, то контакт передается оператору – реальному сотруднику отдела кадров.
Естественно, что для всего этого – написания и подготовки программы рассылки, получения и обработки резюме кандидатов – требуются программисты. Готовый продукт должен анализировать находящиеся в публичном доступе тексты резюме огромного количества соискателей на соответствие специальному шаблону. Конечно, точного совпадения ждать не стоит, но алгоритмы машинного обучения могут оценить, с какой вероятностью кандидат подходит на предлагаемую должность. Таким образом, на первой же стадии поиска происходит обработка больших данных.
После того как алгоритм определяет наиболее подходящих соискателей, их контакты сохраняются и им отправляется приветственное сообщение, к примеру: «Вы нам подходите… Скажите, вас это интересует?» В итоге после этапов поиска и первого вопроса будет отсеяно 90 % кандидатов. Потому что если в ответ на первый же вопрос соискатель молчит, то его можно смело удалять из контактов и продолжать поиски.
Из оставшихся кандидатов, откликнувшихся на приглашение побеседовать о возможном сотрудничестве, придется отсеять еще немалую часть претендентов. Здесь опять вступает в дело машина: существуют алгоритмы по распознаванию текста, вопросов и генерации ответов. То есть компьютер может задать соискателю несколько вопросов до того, как передать задачу – дальше вести этот диалог – оператору. Таким образом можно сократить количество оставшихся кандидатов вдвое. Программистам для разработки подобного алгоритма не надо даже создавать сложную нейронную сеть. Зачастую в первом же ответе на поставленные вопросы содержится контрольное слово или фраза, указывающие на отказ кандидата от сотрудничества: «к сожалению», «вынужден», «приношу» и т. п. Если подобные слова прозвучали, то лучше отбросить такую кандидатуру – этот человек сейчас не готов менять свое место работы.
В любом случае первичный поиск проводится автоматически со скоростью несколько тысяч резюме в день. Только представьте, сколько бы заплатила компания за эту работу, если бы для ее выполнения посадили «девочку на телефон», тратившую бы 90 % времени на «холодный обзвон» номеров, по которым не берут трубку, и на пустую переписку с соискателями, которые либо вовсе не отвечают, либо присылают отказ в первом же сообщении.
Итак, в случае с поиском новых сотрудников в роли больших данных выступает содержимое резюме кандидатов, анализируя которое машина сама определяет, насколько соискатель подходит на предлагаемую должность. Проводя первичный отсев кандидатов, мы значительно снижаем расходы фирмы на подбор персонала. А ведь найм сотрудников – это бесконечный непрерывный процесс, происходящий в каждой компании. Поэтому можно сделать однозначный вывод: цифровизация точно позволит этому отделению сэкономить значительные средства, повысить эффективность и скорость работы.
Контроль качества
Если в процедуре поиска сотрудников на первый взгляд сложно заметить влияние больших данных, то с контролем качества продукта или услуги все более-менее понятно. В этой области уже давно устоялись стандарты проверки, которые используют цифровые метрики. Например, если предприятие производит детали, то отдел контроля качества сравнивает их прочность с требуемой. И в случае, когда деталь ломается при меньшей нагрузке, чем планировалось, всю партию можно забраковать. Записи же об инциденте будут содержать всевозможную информацию: количество протестированных деталей, даты их выпуска, предельные нагрузки на них во время проверки и т. п., которая по результатам тестирования попадает в озеро данных компании. В дальнейшем эти сведения будут использовать для улучшения качества деталей, материала, производственного процесса. Таким образом, отдел контроля качества даже без приказа сверху самостоятельно собирает большие данные, на которых можно тренировать машину с целью получения рекомендаций относительно свойств деталей еще до того, как они будут физически созданы.
С другой стороны, существуют компании, в которых производственные процессы нельзя напрямую измерить цифрами. Например, невозможно сделать это применительно к бизнесу, который предоставляет услуги по прыжкам с парашютом, то есть обеспечивает получение клиентами свежих впечатлений.
Очевидно, что в момент свободного падения у неподготовленного человека происходит мощный выброс адреналина. А после приземления бессмысленно просить его оценить полет по десятибалльной шкале. Потому что в ответ вы рискуете услышать лишь междометия. Скорее всего, клиент даже не способен будет произнести ни одной цифры, просто потому что он их все забудет, или и вовсе не поймет, не услышит вопроса из-за перенесенного стресса.
Ситуация для бизнеса критическая. Но и тут можно многое придумать, используя большие данные. Давайте мысленно проведем эксперимент с подобной компанией. Поставим следующую цель: добиться того, чтобы впечатления от прыжка с парашютом были одинаковыми у всех категорий клиентов – и у новичков, и у опытных. Мы хотим, чтобы после полета количество эндорфина (гормона счастья) в крови каждого клиента было одинаковым при минимальных затратах со стороны компании. С учетом всего этого план по снижению издержек будет звучать так: впечатлительных клиентов выталкиваем за борт пораньше, на средних высотах, а спокойных только на большой высоте. В итоге у всех клиентов после прыжка будет одинаковый уровень эндорфина, а компания неплохо сэкономит на солярке и ремонте.
Для реализации этого плана соберем необходимые нам большие данные, проведя ряд экспериментов. Возьмем десяток спортсменов разного уровня подготовки. Сбросим их с парашютом в разные дни и с разной высоты. Затем сохраним все данные по каждому прыжку. Даже уровень эндорфина в крови, взятой из вены каждого участника. Так у нас появятся большие данные, в которых будет содержаться следующая информация:
• Способ заказа услуги, дата заказа, способ оплаты.
• Вес, рост, пол клиента.
• Дата и время взлета, прыжка, приземления.
• Высота и максимальная скорость при прыжке.
• Температура, давление, осадки, облачность, видимость на разных высотах.
• Скорость набора высоты при взлете.
• Ширина и долгота точки, в которой был совершен выход из самолета, и места, где состоялось приземление.
• Размер и тип парашюта.
• Показатели артериального давления, частоты пульса и сатурации (уровень кислорода) до, после и во время прыжка.
• Уровень эндорфина, адреналина и других гормонов (и всего, что можно измерить) в крови до и после прыжка.
•… и еще бесконечное множество параметров, которые только существуют, включая фазу луны, количество водоемов в 100 метрах от аэродрома, наличие повара в столовой летного училища.
Число собираемых параметров ограничивается лишь фантазией сотрудников компании, которые проводят эксперимент. Но важно, чтобы их было как можно больше. Потому что на собранных данных будет тренироваться модель машинного обучения, которая в дальнейшем сможет предсказывать уровень эндорфина в крови клиента.
Обратите внимание, что после окончания эксперимента и обучения машины прогнозированию, для собственно предсказания не требуется собирать абсолютно всю информацию о настоящих клиентах, то есть достаточно будет лишь измерить их рост, вес и пульс до прыжка (это можно сделать с помощью спортивного браслета с пульсометром), и машина попробует выдать прогноз по этому ограниченному набору данных. Конечно, чем больше параметров введено, тем выше точность предсказания, но и этого минимального пакета вполне достаточно для прогноза хотя бы примерного уровня эндорфина. И нет нужды брать у клиента кровь из вены.
Обычно предсказание по готовой, обученной модели происходит за доли секунды. Это означает, что система может работать буквально во время полета, снимая показания пульса клиента. И когда машина даст сигнал «дошел до кондиции», инструктору останется только настойчиво предложить клиенту насладиться процессом свободного падения прямо сейчас. А чем меньший вес перевозит самолет, тем меньше топлива он тратит, следовательно, компания снижает издержки. С такой моделью предсказаний «удовлетворенности» клиентов расходы на обслуживание воздушного судна снижаются довольно динамично.
Возможно, приведенный пример несколько экзотичен, но он точно иллюстрирует схему сбора и использования больших данных в коммерческих целях. Даже в сфере обслуживания можно получить достаточно числовых данных, чтобы иметь возможность влиять на степень удовлетворенности клиентов, предсказывать уровень испытываемого ими счастья и, как следствие, сокращать издержки.
Финансовое отделение
В современной компании финансовый отдел и так состоит из комплекса электронных систем. Мало кто пользуется бумажной бухгалтерией. У всех есть автоматизированные системы, в которых можно строить графики, диаграммы, делать сводные таблицы, смотреть развернутую статистику. К сожалению, во многих фирмах собственники и топ-менеджеры не работают с отчетами из данного отдела. Несмотря на то, что финансы – это кровь предприятия, а доход – это основная цель существования бизнеса, а бухгалтерские данные являются основным источником информации о будущем компании. Без них невозможно планировать закупки, прогнозировать рост и минимизировать потери от спада продаж.
Бухгалтерия
Финансовые показатели – одни из самых востребованных среди тех, на которые обращают внимание владельцы и топ-менеджеры успешных компаний. Поэтому стоит еще раз напомнить вам про систему, в которой эти показатели отображаются в реальном времени. «Информационная панель», «панель индикаторов» или «дешборд» (dashboard) – это веб-сайт, где можно посмотреть детальную статистику по каждому отделу компании, в том числе и по финансам. Чтобы было понятнее, о чем идет речь, стоит посетить сайт RealBigData.ru, сделанный специально для демонстрации различных идей, изложенных в этой книге. Внутренний раздел сайта является наглядным примером информационной панели компании. Там есть интерактивные графики, диаграммы, таблицы. Попробуйте поработать с ними и ощутить, насколько это мощный инструмент для управления компанией и ежедневного мониторинга работы каждого отделения.
Программисты организации создают информационные панели, настраивают их непрерывное обновление за счет сбора данных системами бухгалтерии. Если точнее, такие панели рождаются благодаря слаженной работе «инженеров по данным» и «аналитиков данных» и в результате запроса со стороны топ-менеджеров и собственников. Используя эти графики, руководство может мгновенно реагировать на изменения любых показателей бизнеса.
Первое, что можно увидеть на информационной панели, отражающей финансовое состояние компании, – это график прибыли за текущий год по месяцам. При этом обычно на таком графике также представлено сравнение текущего года с прошлым, чтобы можно было проследить динамику, и отмечена прогнозируемая часть графика прибыли, предсказанная алгоритмом, то есть возможные продажи до конца года, которые спрогнозировала машина, основываясь на ранее собранных больших данных.
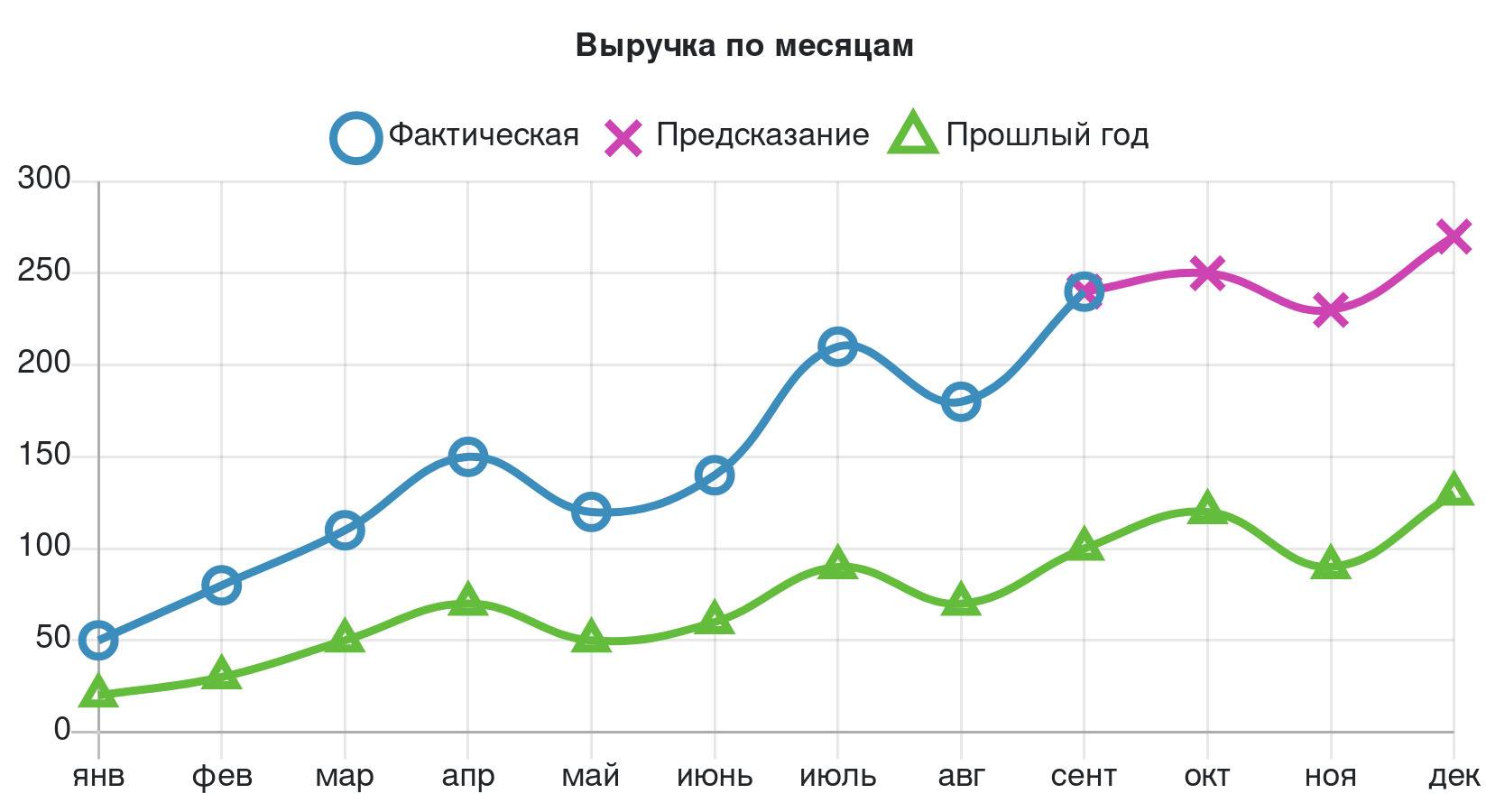
Если углубляться в то, как именно делаются такие предсказания прибыли на будущие периоды, то кратко весь процесс можно описать так:
1. Специалисты по машинному обучению разбирают историю продаж компании на составные части, в том числе по годам, месяцам, неделям и дням.
2. В разбитых данных они находят различные периодические колебания: сезонные, дневные, недельные спады продаж, увеличение спроса в праздники и т. п.
3. На основе найденных периодических эффектов прогнозируются значения на будущее. Можно даже сделать предсказание на весь год или даже десять лет. При этом прогнозы непрерывно уточняются, используя ежедневно поступающие данные по продажам.
Стоит учитывать, что предсказания на короткие промежутки времени более точные, чем на большие. Но в любом случае благодаря прогнозам можно увидеть тенденцию, а значит, сделать вывод, верным ли путем идет компания или пора что-то быстро менять.
К сожалению, во многих компаниях, как это ни странно, именно собственники и топ-менеджеры являются самыми большими противниками использования информационных панелей для контроля финансовых результатов. Зачастую они считают, что такие системы нужны только серьезным и успешным компаниям. А для бизнеса с небольшими оборотами эти графики погоды не сделают. Обычно фирмы с подобными руководителями заканчивают быстро и плохо. Причина банкротства проста: контроль финансовых показателей организации должен начинаться практически с момента ее создания. Потом спешить построить графики будет уже поздно.
Оплата
Финансовое отделение компании отвечает за одну из самых главных функций – сбор денег с клиентов. От скорости и простоты совершения оплаты зависит и отзыв покупателя. Если заставлять его бегать по банкам с распечатанным счетом, он возненавидит фирму и обязательно поделится на просторах интернета тем, какой дискомфорт испытал. С другой стороны, если клиент легко обменяет свои деньги на товар, то негативных впечатлений от этой сделки получит гораздо меньше или не получит вовсе. Конечно, для достижения подобного результата недостаточно только цифровизации всей системы получения оплаты, необходимо провести обучение персонала, чтобы любой менеджер по работе с клиентами мог квалифицированно сопроводить процедуру купли-продажи.
В качестве отличного примера создания единой информационной системы для всей компании рассмотрим опыт отечественного холдинга Major. А точнее его подразделения, занимающегося легковыми автомобилями, Major Auto, клиентом которого является автор данной книги. Эта компания возникла еще в начале века, когда авторынок в России был не так сильно развит. В то время для совершения какой-либо операции по обслуживанию или покупке автомобиля необходимо было дождаться, пока сотрудник салона распечатает специально подготовленный договор, затем получить счет на оплату, далее пройти в кассу, оплатить счет и вернуться с оплаченным счетом обратно к сотруднику. Такой забег требовал от клиента много времени и сил.
