


Полная версия
ChatGPT для саморазвития: Освоения программирования, консалтинга и изучения иностранных языков

Алексей Михнин
ChatGPT для саморазвития: Освоения программирования, консалтинга и изучения иностранных языков
Введение
Добро пожаловать в книгу о том, как использовать ChatGPT для саморазвития в различных областях! В этой книге вы узнаете, как использовать чата для обучения программированию на языке Python, ABAP, для изучения макросов в MS Excel и для повышения уровня английского языка и не только.
В разделе, посвященном изучению Python, мы преподнесем вам уникальную возможность научиться задавать правильные вопросы, а также продемонстрируем вам полный процесс машинного обучения, начиная с загрузки данных, предобработки, статистического анализа и заканчивая обучением модели машинного обучения.
Одним из примеров, которые мы рассмотрим, будет модель, содержащая данные пассажиров Титаника. Используя свои собственные данные, вы сможете предсказать вероятность выживания на корабле благодаря тому, что мы покажем вам, как использовать ChatGPT для обучения модели машинного обучения.
Затем мы перейдем к изучению языка программирования ABAP, где наш ChatGPT будет играть роль программиста, а вы будете проверять его код в системе SAP и создавать отчеты согласно функциональной спецификации.
В разделе, посвященном макросам в MS Excel, наш ChatGPT будет выступать в роли специалиста по макросам, который будет писать готовый код на основе ваших команд и пожеланий, чтобы облегчить вам работу по анализу данных и подготовке красивых отчетов.
В разделе посвящённому изучению иностранных языков, мы покажем вам, как использовать ChatGPT для изучения английского языка, где чат выступит в роли личного репетитора.
Кроме того, в конце книги вы узнаете о том, как продуктивно использовать ChatGPT для продолжения вашего саморазвития. Мы покажем вам, где и как можно применять чат для повышения ваших компетенций и навыков, которые напрямую влияют на вашу производительность и успех в работе.
Вы также узнаете о преимуществах использования ChatGPT в качестве консультанта, который может помочь вам в решении различных задач и проблем, связанных с программированием, анализом данных, работой в SAP и других областях.
Таким образом, читая эту книгу и осваивая различные навыки, вы сможете стать более продуктивным и эффективным в своей работе, достигая новых высот в своей карьере.
Будьте готовы к увлекательному путешествию по саморазвитию с помощью ChatGPT!
Изучаем
Python
– с
ChatGTP
Для демонстрации возможностей ChatGPT в обучении программированию на языке Python, мы предлагаем вам пройти пошаговый сквозной пример машинного обучения, используя набор данных (dataset), содержащий данные о пассажирах Титаника. Файл titanic.csv содержит информацию о 887 пассажирах, включая их выживаемость, возраст, класс пассажира, пол и стоимость проезда.
Вы, в качестве пользователя, будете задавать вопросы на русском языке чат-боту, который будет предоставлять развернутые ответы с решением, которые Вы заносите в среду разработки, в данном случае – Jupyter lab, и проверяете результаты и адекватность ответов.
По результатам прохождения сквозного примера, Вы будете наблюдать, как правильно писать вопросы и как взаимодействовать с чат-ботом. В конце данной главы вы сможете уже самостоятельно не только анализировать большие объёмы бизнес-данных на языке python но и познакомитесь с основами машинного обучения затратив минимальное время и сэкономив на курсах по обучению python которые стоят десятки тысяч рублей.
Файл с данными о пассажирах (Титаника), который мы будем использовать в нашем сквозном примере для обучения – вы можете скачать беслпатно на сатей kaggle.
Дано:
В левой части перед нами открытый чат ChatGPT, регистрация на данном ресурсе бесплатная. Как зарегистрироваться для граждан России (см. раздел Секреты – регистрация на сайте ChatGPT )
В правой части экрана представлена среда разработки (Colab) от google для языка Python – доступ к данной среде предоставляется бесплатно. Как только зарегистрируетесь в среде разработки Colab, не забываем загрузить туда наш файл с данными (датасет) по Титанику.
После того как мы зарегистрировались в ChatGPT и получили доступ в Colab и разобрались как загрузить туда наш датасет, можно приступать к нашему увлекательному путешествию.
В следующих главах этой книги вы будете замечать слова "Пользователь" – это означает, что мы будем писать запросы и команды для передачи в ChatGPT от вашего лица. А когда вы получите ответ, вы увидите слово "Чат", которое будет означать ответ ChatGPT на наши запросы и команды.
Кроме того, мы будем обращать ваше внимание на важные моменты, которые могут помочь вам работать с ChatGPT более продуктивно и эффективно. Эти моменты будут помечены словом "Внимание", чтобы вы смогли легко заметить их и улучшить свой опыт работы с ChatGPT.
Когда мы говорим о "Результате", мы имеем в виду тестирование решения, предложенного ChatGPT, в соответствующей среде разработки.
Для языка программирования Python мы будем использовать среду разработки Colab/Jupiter для тестирования наших решений. В случае работы с SAP мы будем использовать среду разработки SAP ERP, а для работы с MS Excel – MS Excel.
Мы убедимся, что предложенное решение, созданное с помощью ChatGPT, проходит тестирование в соответствующей среде разработки, что гарантирует его готовность для практического применения в вашей работе.
Шаг1 Загрузка и изучение данных
На этом шаге мы попробуем загрузить информацию из нашего датасета в среду разработки и получить общую информацию о данных.
Это позволит нам более детально изучить и понять наш набор данных, что в свою очередь поможет нам выбрать правильные инструменты и методы для анализа данных и решения поставленных задач.
Пользователь:
Напиши мне код на python – Открой файл titanic.csv с данными и изучите общую информацию по данному файлу и представь все в табличном виде.
Чат:
Для выполнения этого задания мы будем использовать библиотеку pandas.
Если у вас ее нет, установите с помощью команды:

Теперь, когда у вас есть библиотека pandas, следуйте приведенному ниже коду для открытия файла 'titanic.csv' и вывода общей информации о данных в табличном виде:
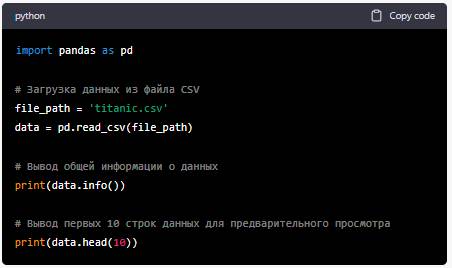
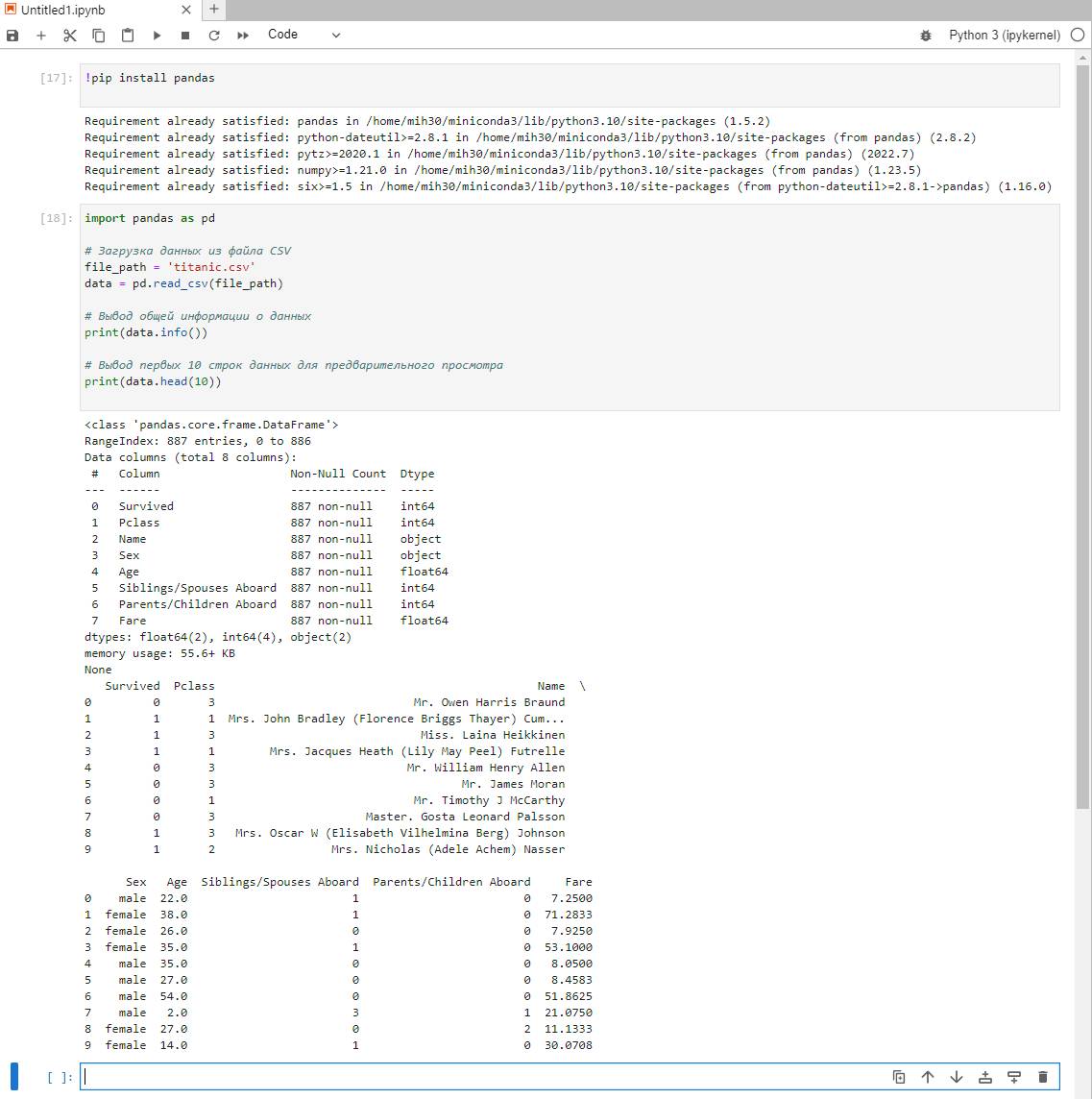
После выполнения этого кода вы увидите общую информацию о данных, такую как количество строк, столбцов, типы данных и количество непустых значений. Также вы увидите первые 10 строк данных для предварительного просмотра.
Учтите, что вам нужно будет заменить 'titanic.csv' на действительный путь к файлу CSV на вашем компьютере или URL-адрес файла, если он доступен онлайн.
Результат:
Выполняем все рекомендации Чата и посмотрим смотрим что из этого получилось.
Шаг2 Предварительная обработка данных
Давайте попробуем предварительно обработать данные на этом шаге. Мы проверим на наличие дубликатов, пропущенных значений и другие аномалии. Мы не знаем, какое качество данных находится в нашем файле на входе, поэтому этот шаг очень важен для последующего анализа данных. Предварительная обработка позволит нам избавиться от мусорных значений и повысит качество нашего анализа.
Пользователь
Выведи все названия столбцов в одну строку и выполни шаги по предварительной обработке данных т.е. проверь на дубликаты, на наличие пропущенных значений и т.п. и выведи отчет по результатам предварительной обработки.
Чат:
Для выполнения этой задачи мы будем использовать библиотеку pandas.
Приведенный ниже код выполняет предварительную обработку данных и выводит отчет по результатам:
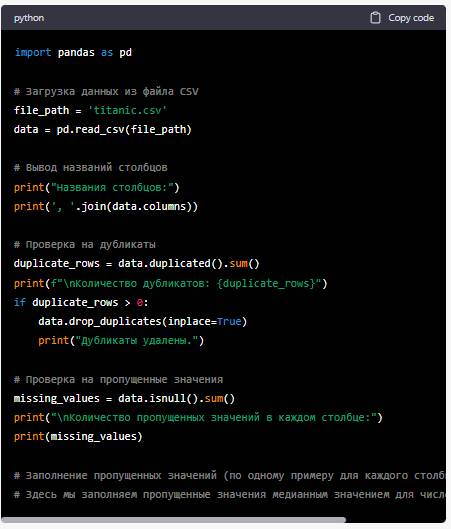
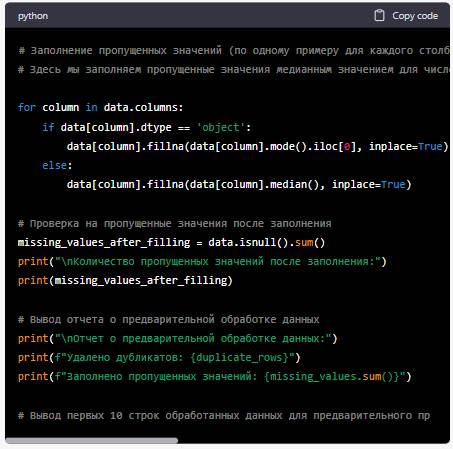
После выполнения этого кода вы получите отчет о предварительной обработке данных, включая количество удаленных дубликатов и заполненных пропущенных значений. Код также выводит первые 10 строк обработанных данных для предварительного просмотра.
Учтите, что вам нужно будет заменить 'titanic.csv' на действительный путь к файлу CSV на вашем компьютере или URL-адрес файла, если он доступен онлайн.
Результат:
Выполняем все рекомендации Чата и посмотрим смотрим что из этого получилось.
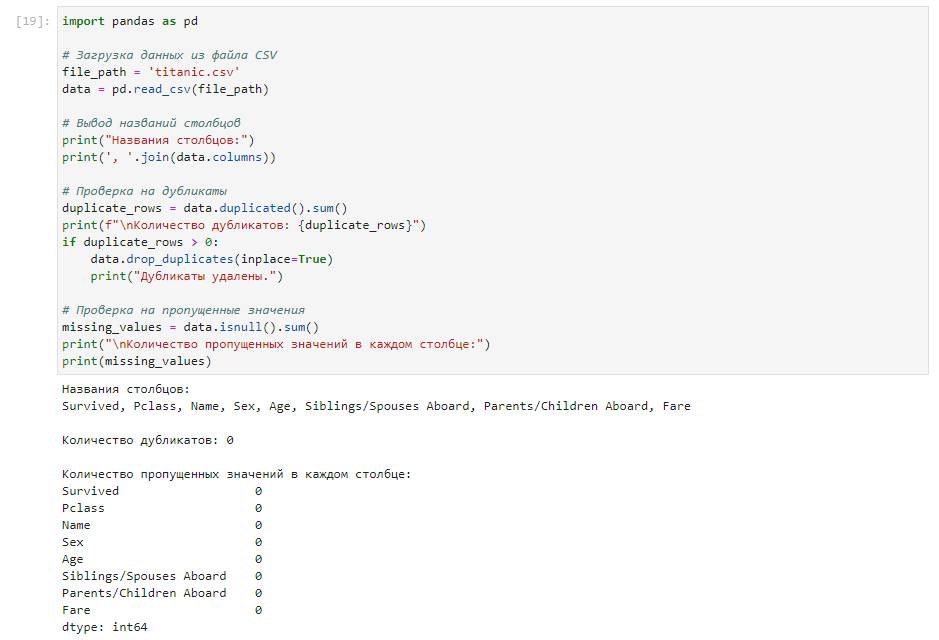
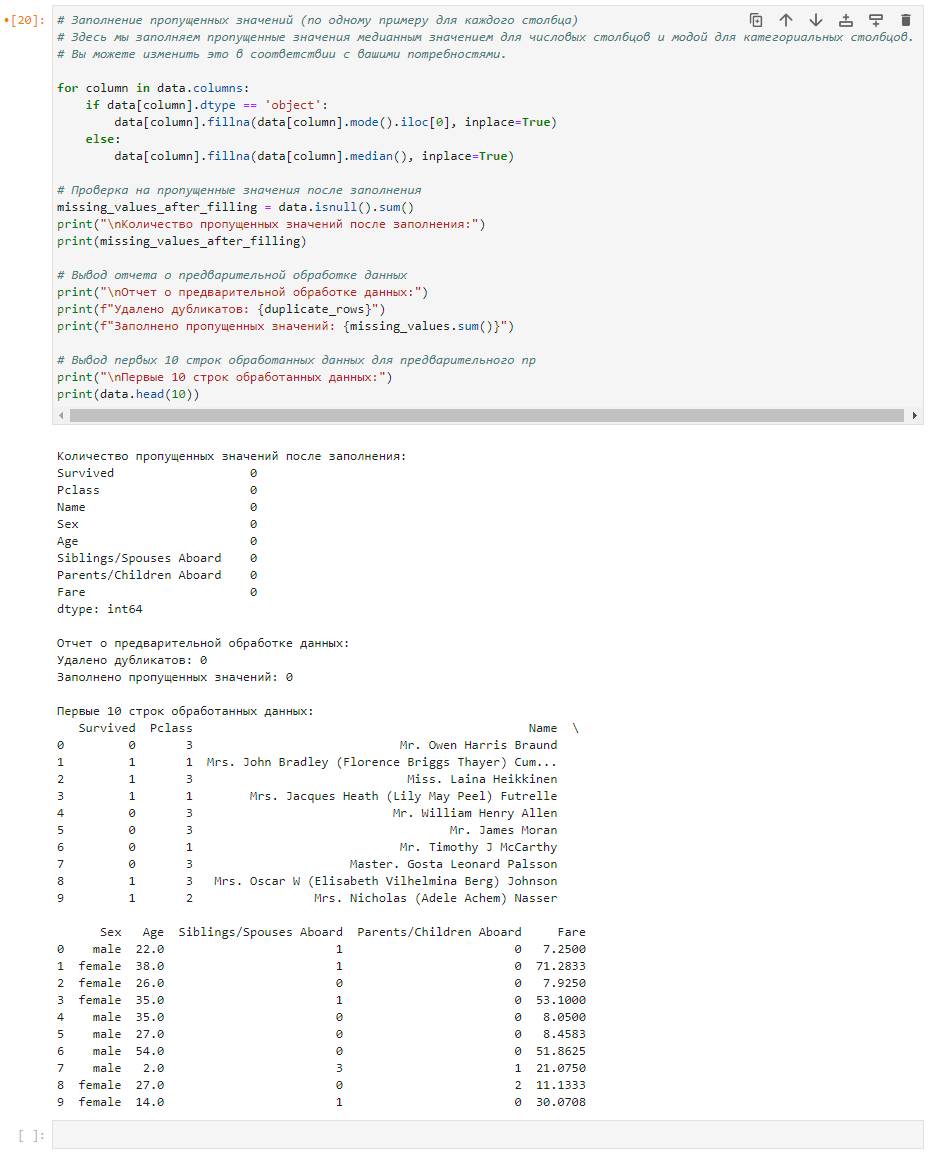
Внимание:
Мы заметили, что при каждом ответе ChatGPT повторяется код, который устанавливает библиотеку pandas для работы с табличными данными, и загружает данные из нашего датасета в переменную data. Чтобы избежать повторения этого кода, мы можем поступить следующим образом:
Пропустить эти строки кода и использовать только код, который расположен ниже.
Конкретизировать наши запросы, напоминая ChatGPT о том, что библиотека pandas уже установлена, и что файл titanic.csv уже загружен в переменную data.
Кроме того, мы рекомендуем напоминать ChatGPT о том, какие названия столбцов у нас есть в датасете, и какого они типа. Это поможет нам точнее работать со столбцами в нашем датасете. Для этого мы можем попросить ChatGPT вывести названия столбцов и их типы в одну строку, которую мы сможем скопировать и использовать для конкретизации наших последующих запросов.
Пользователь:
Выведи в одну строку название столбцов и тип каждого столбца
Внимание:
Мы не указали, какой именно датасет мы должны использовать в данном запросе, потому что мы формируем запрос в текущем чате обсуждения, и ChatGPT будет анализировать предыдущие шаги, чтобы понять, какой датасет мы используем. Однако, если в текущем чате было выполнено много шагов или если есть несколько альтернативных датасетов, то необходимо конкретизировать запрос, указав, какой датасет нужно использовать.
Чат:
Для вывода названия столбцов и типа каждого столбца, используйте следующий код:
Результат:
Выполняем все рекомендации Чата и посмотрим смотрим что из этого получилось.

Внимание:
Как вы заметили, мы пропустили строки кода с импортом библиотеки pandas и загрузкой данных из CSV файла. Мы воспользовались ранее предложенным советом и пропустили эти строки кода, чтобы избежать повторения одних и тех же команд.
Шаг3 Визуализация и статистический данных
Для построения различных графиков, которые могут помочь визуализировать и провести статистический анализ данных, мы просим Чат предоставить нам соответствующий код.
Такой код позволит нам быстро и удобно построить необходимые графики и провести необходимый анализ данных.
Благодаря этому мы сможем получить более глубокое понимание нашего датасета и извлечь более полезные выводы из данных.
Пользователь:
Библиотека pandas уже установлена и наш файл titanic.csv уже загружен в переменную data.
Файл titanic.csv содержит следующие столбцы:
Survived: int64, Pclass: int64, Name: object, Sex: object, Age: float64, Siblings/Spouses Aboard: int64, Parents/Children Aboard: int64, Fare: float64
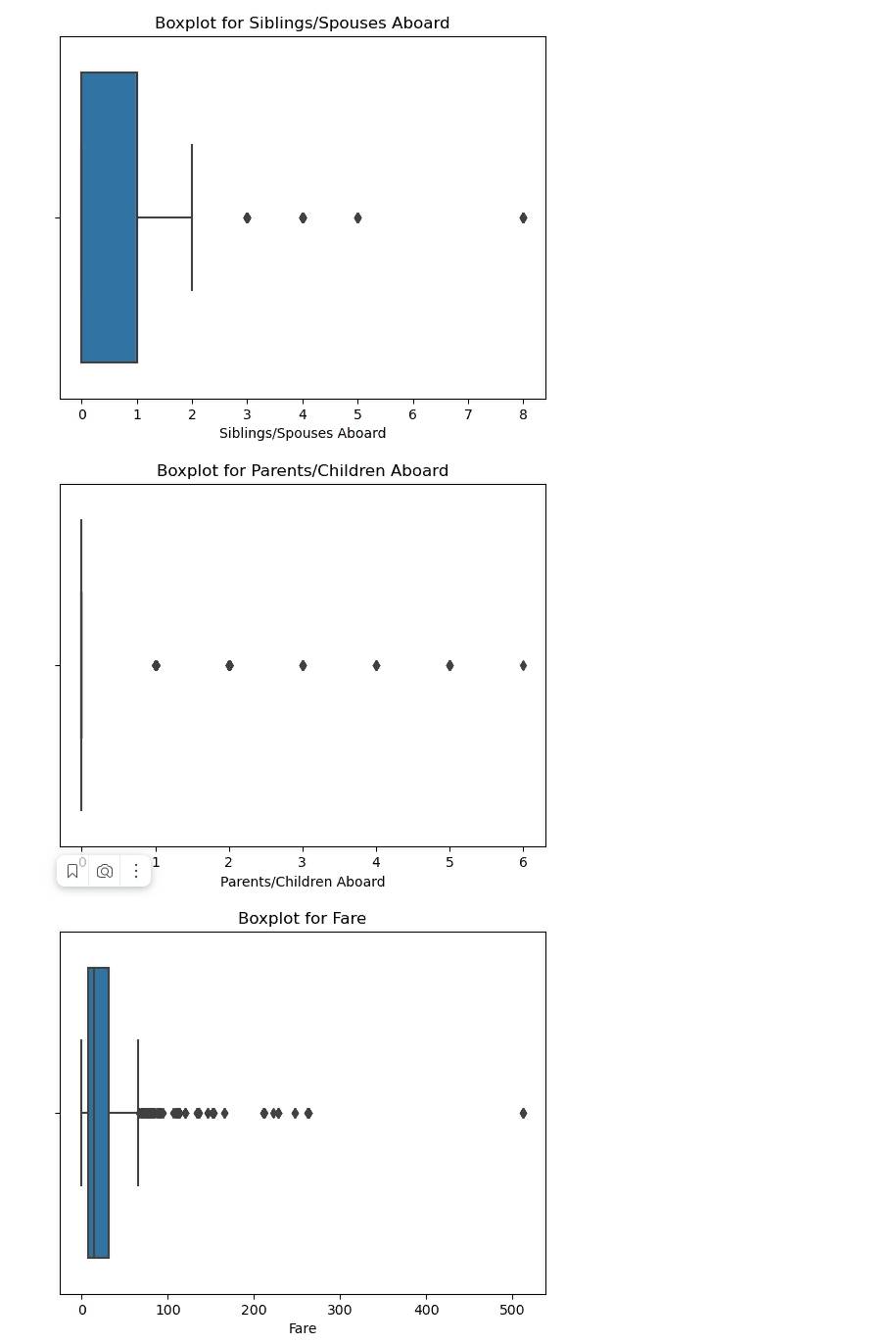
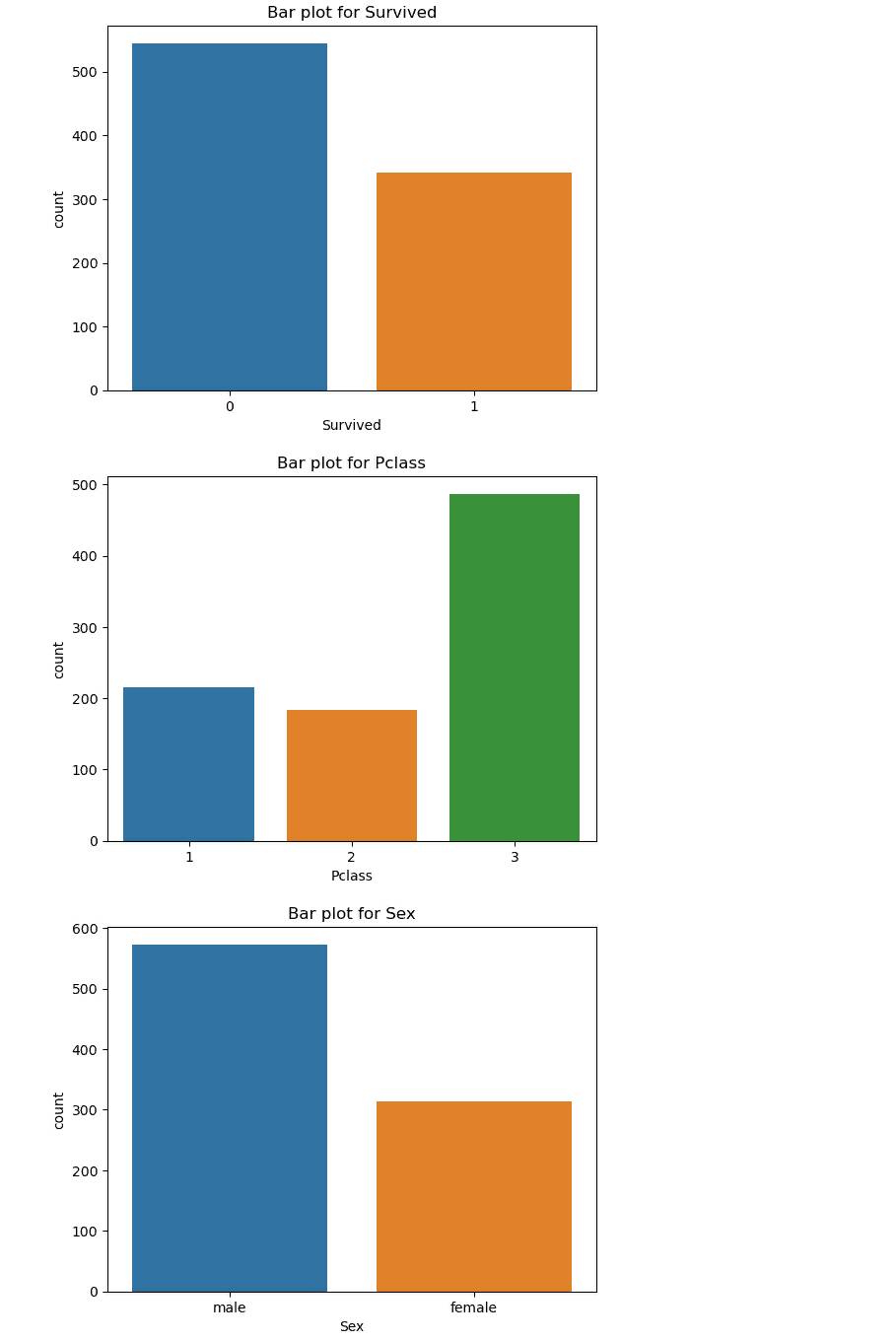
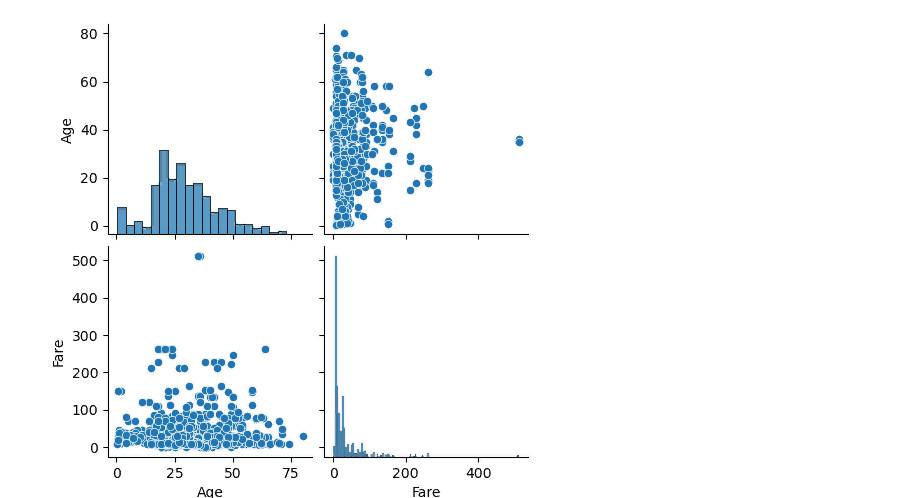
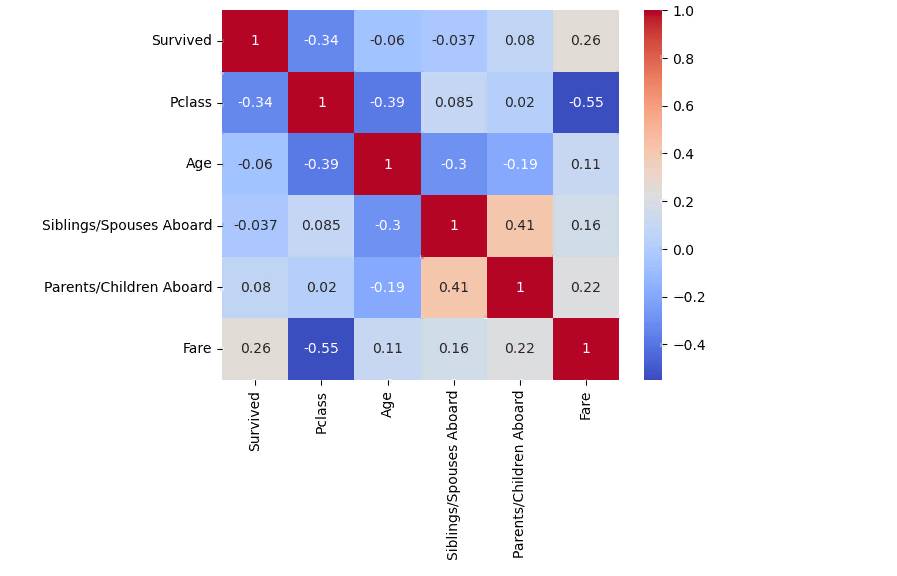
Выполни визуализацию данных построив гистограмму, box plot, bar plot, scatter plot и корреляционную матрицу.
Чат:
Если данные уже загружены в переменную data, вы можете использовать следующий код для визуализации данных с помощью гистограмм, box plot, bar plot, scatter plot и корреляционной матрицы:
Этот код создаст графики визуализации, включая гистограммы, box plot, bar plot, scatter plot и корреляционную матрицу для различных столбцов данных. Гистограммы и box plot используются для числовых переменных, в то время как bar plot используется для категориальных переменных. Scatter plot и корреляционная матрица позволяют наблюдать взаимосвязь между числовыми переменными.
Выполнение кода создаст графики, которые помогут вам лучше понять распределение данных, взаимосвязь между переменными и выявить возможные выбросы или аномалии в данных.
Результат:
Выполняем все рекомендации Чата и посмотрим смотрим что из этого получилось.
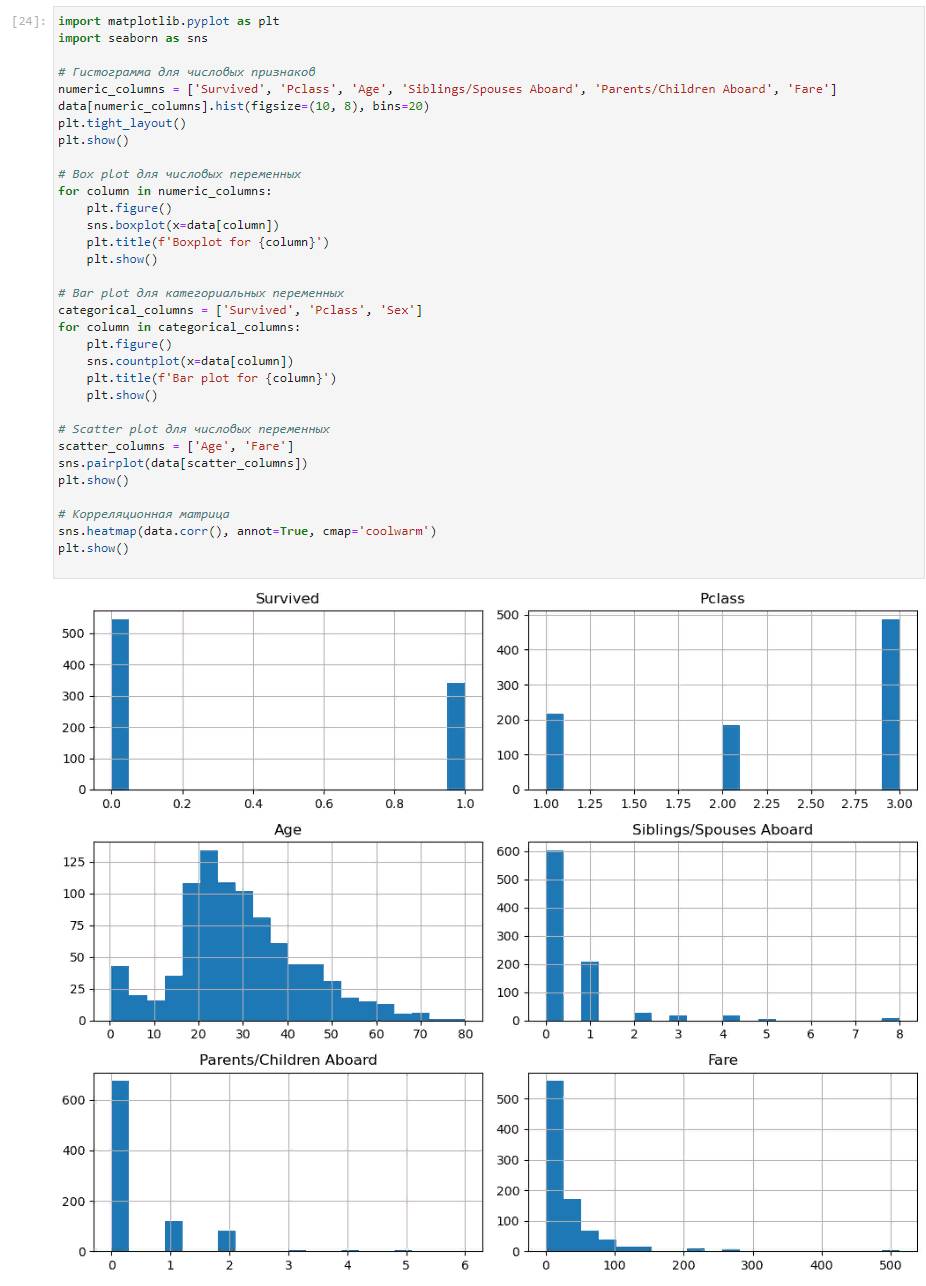
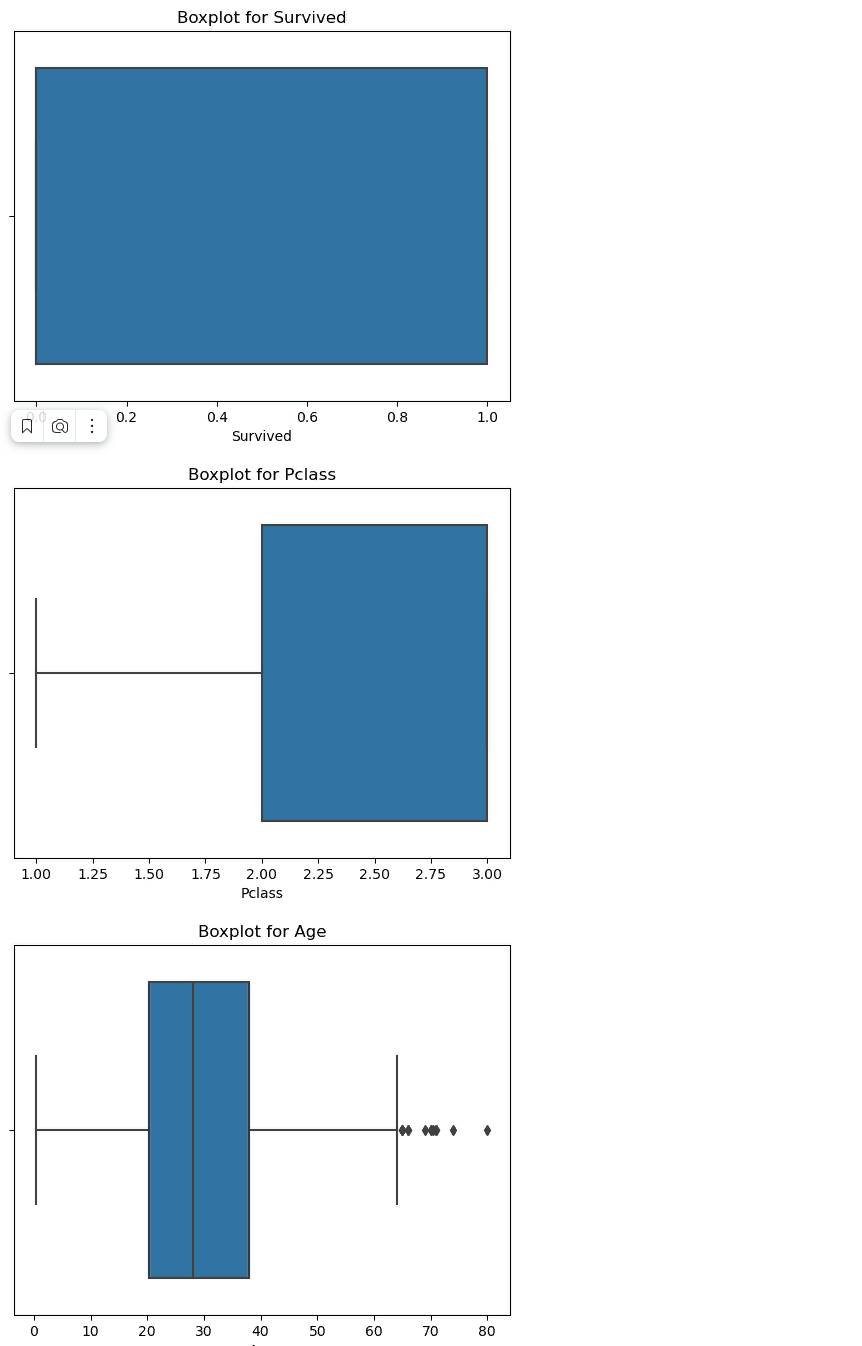
Пользователь:
Ты можешь анализировать графики?
как их загрузить тебе для анализа?
Чат:
К сожалению, как AI, я не могу напрямую анализировать изображения или графики, загруженные пользователем. Однако, если у вас есть вопросы о том, как интерпретировать графики или какие выводы можно сделать на основе графиков, я могу помочь вам с объяснениями и рекомендациями.
Вы можете задать вопросы, касающиеся графиков, и я постараюсь дать вам подробные ответы и объяснения.
Примеры вопросов могут быть следующими:
Как интерпретировать корреляционную матрицу?
Что такое выбросы на box plot, и что они могут означать для данных?
Какие выводы можно сделать из гистограммы или bar plot?
Пожалуйста, задайте свои вопросы, и я с радостью помогу вам разобраться в анализе графиков.
Пользователь:
Как интерпретировать корреляционную матрицу?
Что такое выбросы на box plot, и что они могут означать для данных?
Какие выводы можно сделать из гистограммы или bar plot?
Чат:
Корреляционная матрица – это таблица, которая показывает корреляционные коэффициенты между парами переменных. Корреляционные коэффициенты – это числовые значения, которые измеряют степень связи между двумя переменными.
Коэффициент корреляции может принимать значения от -1 до 1. Коэффициенты, близкие к 1, означают положительную корреляцию, т.е. если значение одной переменной увеличивается, то увеличивается и значение другой переменной. Коэффициенты, близкие к -1, означают отрицательную корреляцию, т.е. если значение одной переменной увеличивается, то значение другой переменной уменьшается. Коэффициенты, близкие к 0, означают отсутствие корреляции между переменными.
Box plot – это график, который показывает распределение данных и позволяет выявлять выбросы. Выбросы – это значения, которые сильно отличаются от остальных значений в выборке. Выбросы могут означать, что данные содержат ошибки, ошибки измерения или аномальные значения. Также выбросы могут быть результатом редкого события или непредвиденных условий, которые необходимо учитывать при анализе данных.
Гистограмма – это график, который показывает распределение данных по определенным интервалам или классам. Она может помочь понять форму распределения данных, например, нормальное, скошенное или мультимодальное распределение. Bar plot – это график, который используется для сравнения количественных данных между несколькими категориями. Он может показать, какие категории имеют более высокие или более низкие значения, и помочь выявить различия в данных между категориями. Выводы из гистограммы или bar plot могут помочь понять, какие категории или значения в данных являются наиболее значимыми или важными для анализа.
Внимание:
Как вы уже заметили, ChatGPT не только предоставляет вам код с решением, но и может подробно консультировать вас, объяснять сложные термины и помогать сделать выводы и заключения.
Это значительно упрощает процесс обучения и решения задач, позволяя вам получать не только готовые решения, но и понимать, как они работают и почему они правильны. Это очень полезно для тех, кто только начинает изучать программирование или машинное обучение, так как помогает закрепить теоретические знания на практике.
Шаг 4 Построение модели машинного обучения
Далее в книге мы предоставляем код, который поможет вам построить модель машинного обучения на основе подготовленного датасета и обучить ее предсказывать значения столбца "Survived" (выживший). С помощью этой модели вы сможете оценить вероятность своего выживания, если бы вы оказались на Титанике в тот роковой день.
Пользователь:
Библиотека pandas, matplotlib, seaborn уже установлены и наш файл titanic.csv уже загружен в переменную data.
Файл titanic.csv содержит следующие столбцы:
Survived: int64, Pclass: int64, Name: object, Sex: object, Age: float64, Siblings/Spouses Aboard: int64, Parents/Children Aboard: int64, Fare: float64
Столбец Survived – это целевая переменная, которую необходимо научится предсказывать на основании переменных Pclass, Name, Sex, Age, Siblings/Spouses Aboard, Parents/Children Aboard, Fare
Построй модель на языке python и обучи ее.
Предобработка данных на проверку дублей, пустых значений уже выполнена.
Чат:
Поскольку предобработка данных уже выполнена, приступим к построению и обучению модели. В качестве модели я выберу случайный лес (Random Forest) из библиотеки sklearn.
Сначала разделим данные на обучающую и тестовую выборки, а затем обучим модель.
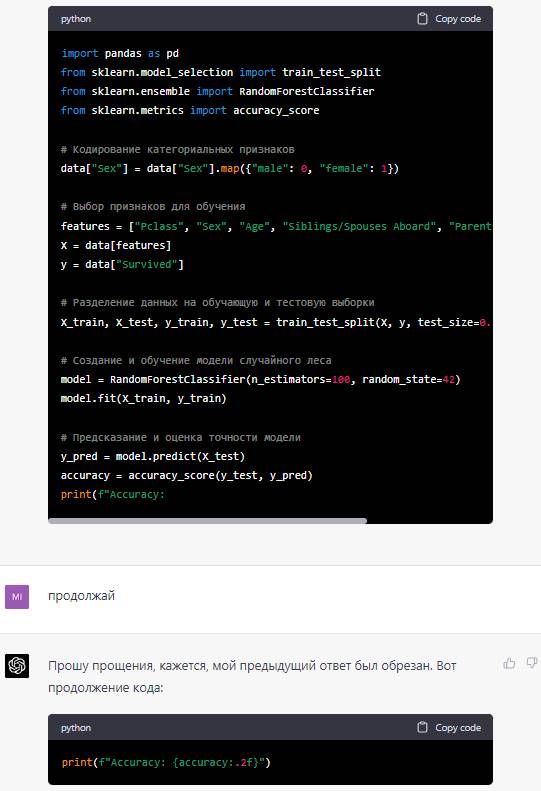
Теперь, когда модель обучена, вы можете использовать её для предсказания выживаемости на новых данных.
Пример:
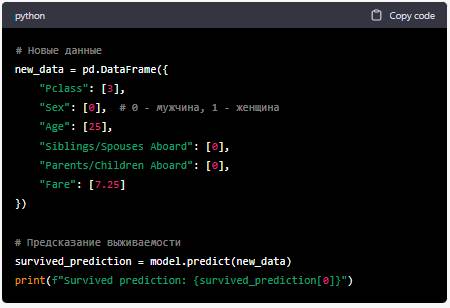
Таким образом, вы можете использовать обученную модель для предсказания выживаемости на основе данных о пассажирах.
Внимание:
Как вы заметили на представленном выше скриншоте, пользователь использовал слово "продолжай". Мы используем это слово в случае, когда по каким-то неизвестным нам причинам ChatGPT не завершает свой ответ до конца и обрывается на полпути.
Написание слова "продолжай" воспринимается чатом как инструкцию продолжить с того места, где он остановился. Однако, если мы напишем это слово, когда чат уже завершил свою мысль, то он воспримет это как просьбу дать нам еще примеров или информации по данному запросу.
Результат:
Выполняем все рекомендации Чата и посмотрим смотрим что из этого получилось.
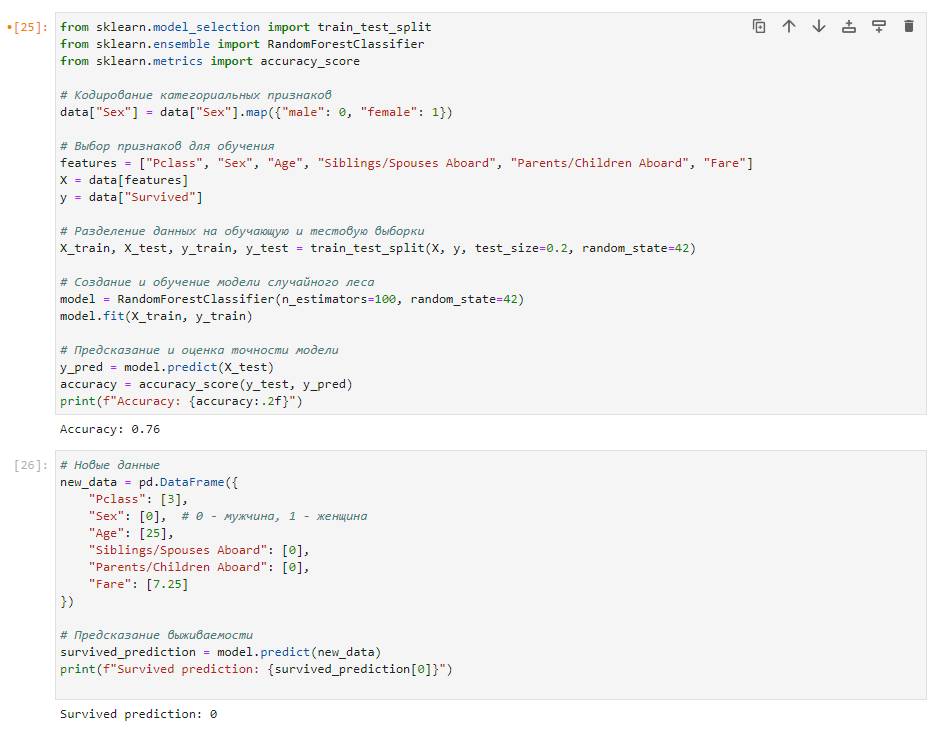
Пользователь:
Что означает Accuracy: 0.76 и Survived prediction: 0
Чат:
Accuracy: 0.76 означает, что точность вашей модели составляет 76%. Точность (accuracy) – это доля правильно классифицированных объектов от общего количества объектов. В данном случае, модель правильно предсказала выживаемость пассажиров в 76% случаев на тестовой выборке. Это одна из метрик оценки качества классификации.
Survived prediction: 0 относится к примеру с новыми данными о пассажире. Значение 0 указывает на то, что модель предсказывает, что этот пассажир не выживет в случае кораблекрушения. В данной задаче классификации значение 0 соответствует классу "не выжил", а значение 1 соответствует классу "выжил".
Пользователь:
Давайте попробуем сделать изменения в коде самостоятельно, без запросов в ChatGPT. Мы заменим значения для предсказания на свои собственные, вместо мужчины мы подставим женщину, а все остальные параметры оставим без изменений.
Результат:
Выполняем все изменения и посмотрим смотрим что из этого получилось.
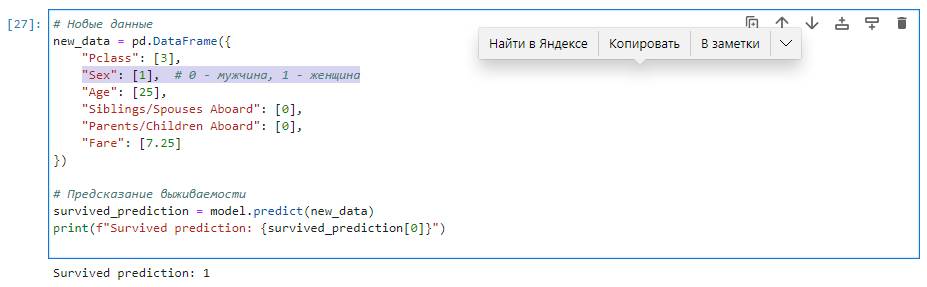
Получается, что женщина с теми же параметрами выжила. Это неудивительно, учитывая тот факт, что на борту спасательных шлюпок в первую очередь спасали женщин и детей. Мы можем сделать вывод, что пол пассажира был одним из факторов, влияющих на выживаемость в данном случае.
Пользователь:
Как добиться более высокой точности модели?
Чат:
Для достижения более высокой точности модели можно выполнить следующие шаги:
Инжиниринг признаков:
Создайте новые признаки на основе существующих данных. Например, вы можете создать признак "IsAlone" (один путешествует), если количество родственников на борту (Siblings/Spouses Aboard + Parents/Children Aboard) равно нулю.
data["IsAlone"] = (data["Siblings/Spouses Aboard"] + data["Parents/Children Aboard"]).apply(lambda x: 1 if x == 0 else 0)
Отбор признаков:
Оцените значимость признаков и исключите незначимые или шумные признаки из обучения.
Оптимизация гиперпараметров:
Подберите оптимальные значения гиперпараметров модели, например, используя поиск по сетке (GridSearchCV) или случайный поиск (RandomizedSearchCV) из sklearn.
Дополнительно – рекомендации автора:
Для более полного понимания метрик машинного обучения, их разнообразия и правильного выбора в различных ситуациях, мы рекомендуем ознакомиться с книгой того же автора под названием "Оценка качества моделей машинного обучения: выбор, интерпретация и применение метрик".
Также, если вам необходимо овладеть процессом машинного обучения для табличных данных и узнать, какие вопросы стоит задавать чат-боту при обработке таких данных, мы рекомендуем прочитать книгу этого же автора "Табличное Мастерство: Осваиваем Модели Машинного Обучения для Анализа Табличных Данных". Обе книги помогут вам овладеть профессиональными навыками в области машинного обучения и эффективно применять их на практике.
Выводы
Мы успешно прошли полный процесс машинного обучения на языке Python, начиная с загрузки и предобработки данных, их визуализации, разделения на обучающую и тестовую выборки, обучения модели и тестирования ее на данных, а также объяснения результатов и возможных дальнейших шагов.
Конец ознакомительного фрагмента.
Текст предоставлен ООО «ЛитРес».
Прочитайте эту книгу целиком, купив полную легальную версию на ЛитРес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.







