


Полная версия
Основы статистической обработки педагогической информации
Эта книга посвящена исключительно табличным данным: коллекции значений, каждая из которых связана с переменной и наблюдением. При том, что есть много наборов данных, которые не вписываются естественным образом в эту парадигму, например, изображения, звуки, деревья и текст. Но таблицы чрезвычайно распространены в науке и промышленности, они являются отличной стартовой площадкой для анализа данных.
Можно разделить анализ данных на следующие два этапа: генерация гипотез и подтверждение гипотезы (иногда называемый подтверждающим анализом). Основное внимание в этой книге уделяется генерации гипотез или исследованию данных. Будем внимательно смотреть на данные и в сочетании предметной областью генерировать много интересных гипотез, чтобы помочь найти объяснение, почему данные ведут себя именно так. Относитесь к гипотезам непредвзято, скептически, с разных сторон подходя критически.
Естественным продолжением процесса генерации гипотез является подтверждение одной из гипотез. Подтверждение гипотезы бывает трудным по двум причинам:
1) Для этого понадобится точная математическая модель, чтобы генерировать фальсифицируемые прогнозы. Это часто требует значительных усилий и статистической изощренности.
2) Наблюдение можно использовать только один раз для подтверждения гипотеза. Как только используете его больше, чем один раз, возвращайтесь к проведению исследовательского анализа. Это значит, чтобы считать гипотезу подтвержденной, нужно написать заранее весь план анализа, и не отклоняться от него. Позднее мы поговорим о некоторых стратегиях, которых стоит придерживаться, для упрощения моделирования.
Ошибочно полагать моделирование как инструмент подтверждения гипотезы и выбирать визуализацию в качестве единственного инструмента для генерации гипотез. Модели зачастую используется для формулирования гипотез, и с определенной осторожностью можно использовать визуализацию для их подтверждения. Ключевое различие заключается в том, насколько часто воспроизводится каждое наблюдение: если только один раз, это подтверждение; если больше, чем один раз, это уже исследование.
Чтобы получить максимальную отдачу от этой книги, предварительно стоит изучить вводный курс численных методов и определенно полезным иметь некоторый опыт в программировании. Если никогда не программировали ранее, до прочитайте базовый курс по программированию, как полезное дополнение к этой книге.
Для запуска примеров кода из этой книги вам понадобятся: R, RStudio, коллекция пакетов R под названием Tidyverse и несколько других пакетов. Пакеты являются основной единицей воспроизводимого кода R. Они включают в себя функции, документацию, и тестовые наборы данных.
Чтобы загрузить R, если не сделали этого ранее, перейдите на сайт CRAN, который состоит из зеркалируемых серверов, распределенных по всему миру, и используется для распространения R. Не пытайтесь выбрать зеркало, которое находится географически рядом, вместо этого используйте зеркало облака, https://cloud.r-project.org, которое автоматически выяснит оптимальное расположение серверов для загрузки.
Новая основная версия R выходит один раз в год, кроме того, выпускается два или три незначительных обновления каждый год. Положите за правило регулярно обновлять установку. Да, обновление может принести немного хлопот, особенно основных версий, которые требуют переустановки всех ваших пакетов, но откладывание только ухудшает ситуацию.
RStudio это интегрированная среда разработки, или IDE, для программирования в R. Загрузите и установите его с официального сайта http://www.rstudio.com/download. RStudio обновляется несколько раз в год. Когда новая версия будет доступна, RStudio сообщит об этом. Опять же, хорошей привычкой является регулярное обновление установки, чтобы воспользоваться преимуществами актуальных сборок. Для воспроизведения примеров из этой книги, убедитесь, что установлена актуальная версия RStudio.
Когда запустите RStudio, увидите поля в интерфейсе:
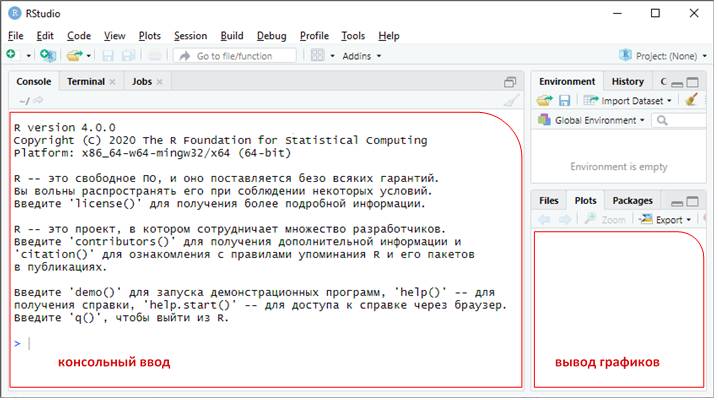
На данный момент все, что нужно знать, это то, что набирается R код на панели консоли, а запускается нажатием на клавиатуре клавиши Enter.
Хрестоматийный пример, после выполнения серии команд:
library(ggplot2)
ggplot(mpg, aes(x = displ, y = hwy))+geom_point(aes(colour = class))
Система запишет лог выполнения

подключится библиотека для работы с графиками (ggplot2) и визуализируются данные об объеме двигателя автомобиля, в литрах (displ) в зависимости от топливной экономичности автомобиля на шоссе, в милях на галлон (hwy) из предустановленной базы автомобильных производителей (mpg) выделив цветом автомобили разных классов (class).
В соответствующей главе разберем аналогичный пример на педагогических данных подробнее.

Также потребуется установить некоторые дополнительные пакеты R. Пакет R представляет собой набор функций, данных и документацию, что расширяет возможности базовой установки. Использование пакетов является ключевым для успешного использования R. большинство пакетов, которые используются в этой книге есть часть так называемого коллекции пакетов Tidyverse. Пакеты Tidyverse разделяют общую философию программирования и данных в R, а также предназначены для совместной работы. Вы можете установить полный комплект Tidyverse одной строкой кода:
install.packages("tidyverse")
На компьютере введите эту строку в поле консоли, а затем нажмите клавишу Enter, чтобы запустить её. R загрузит приложение пакеты с серверов CRAN и установит их на компьютер. Если возникнут проблемы при установке, убедитесь, что есть подключение к интернет, и что https://cloud.r-project.org/ не блокируется с помощью брандмауэра или на стороне прокси-сервера.
Вы не сможете использовать функции, данные и файлы справки из пакета, пока не подключите его с помощью команды library(). После установки пакета можете загрузить его библиотечной функцией:
library(tidyverse)
В логе консоли отобразится процесс загрузки необходимых пакетов, являющихся ядром tidyverse, потому что используются они практически в каждом анализе.
Пакеты tidyverse достаточно часто обновляются. Можете посмотреть, доступны ли обновления, и при необходимости установить их, запустив
tidyverse_update()
Есть много разных пакетов, которые не являются частью tidyverse, они либо решают задачи статистического анализа немного иначе, либо предназначены для использования других парадигм представления информации. Это не делает их лучше или хуже, они просто иные. По мере ознакомления с R, обязательно узнаете про новые пакеты и новые способы представления данных. В книге будем использовать как правило три вспомогательных пакета из-за ограничений tidyverse. Так как в них предоставлены данные о мировом развитии, рейсах авиакомпаний и бейсболе, то присутствуют некоторые сведения об успеваемости, развитии, различные оценки и тесты, поэтому мы будем использовать их для иллюстрации ключевых идей науки о педагогических данных.
Выше было показано несколько примеров выполнения кода на языке R. Код в книге выглядит так:
1 + 2
#[1] 3
Если запустите тот же код в своей локальной консоли, он будет выглядеть так:
> 1 + 2
[1] 3
Как видим, в консоли код вводится после приглашения, символа «>», его не будем дублировать в книге. Выходные же данные порой закомментированы с помощью «#»; а в консоли они появляется непосредственно после кода. Эти два различия означают, что если работаете с электронной версией книги, то сможете легко копировать код из книги и вставлять его в консоль. Кроме того, на протяжении всей книги будем пользоваться следующими договоренностями в тексте кода:
1) Функции находятся в шрифте кода и завершаются скобками, например sum().
2) Другие объекты R, например, данные или аргументы функции, записываются без скобок.
3) Если из контекста не ясно, какой объект из какого пакета, то будем использовать имя пакета, за которым следуют два двоеточия и имя объекта. Этими допущениями изобилует код R.
С другой стороны, эта книга не единственна в своём роде, есть много людей и онлайн-ресурсов, помогающих освоить R. Как только начнете применять техники, описанные в этой книге к вашим данным, наверняка возникнут вопросы, на которые здесь нет ответа. Приведём несколько советов, как получить помощь, чтобы продолжить обучение. Если не знаете, с чего начать, начните с Yandex. Как правило, добавления «R» к поисковому запросу достаточно, чтобы повысить релевантность поисковой выдачи: если поиск не удался, это часто означает, что нет доступных для R результатов, но Yandex особенно полезен для поиска сообщений об ошибках. Если же получаете сообщение об ошибке и Yandex понятия не имеет, что это значит, попробуйте погуглить. Скорее всего, кто-то ранее уже сталкивался с подобным, и обращался за помощью где-нибудь в интернете. Если сообщение об ошибке не отображается на русском, то в консоли введите
Sys.setenv(LANGUAGE = "ru")
и повторите запуск кода; с большей вероятностью найдете справку для сообщения об ошибке на русском языке. При этом, удастся избежать многих проблем совместимости кода, написанного членами международных исследовательских команд, если настроите RStudio через меню Tools/Global Options на использование UTF-8 в качестве кодировки по умолчанию, как это показано на следующей иллюстрации:
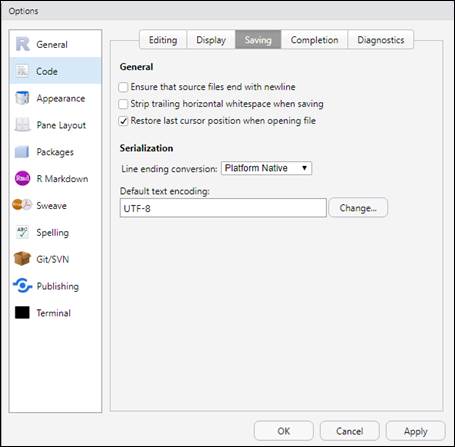
Если Yandex не помогает, то попробуйте ru.stackoverflow.com. Начните с того, чтобы потратить немного времени на поиск существующего ответа, в том числе по тэгу [R], чтобы ограничить ваш поиск вопросами и ответами, которые используют R. Если не нашли ничего полезного, то подготовьте краткий воспроизводящий ошибку пример. Удачный пример делает его более доступным для других людей, чтобы они смогли помочь вам, и часто искореняет проблему в процессе его подготовки.
Есть три вещи, которые нужно описать, чтобы сделать ваш пример воспроизводим другими: необходимые пакеты, используемые данные и код.
1) Пакеты должны загружаться в самом начале скрипта, чтобы можно было увидеть, какие из них понадобятся в примере. При этом, хорошо не лишним будет проверить, что используете последнюю версию каждого пакета; возможно, разработчики обнаружили ошибку ранее и она уже была исправлена с момента установки пакета. Для пакетов из комплекта tidyverse самый простой способ – запустить tidyverse_update().
2) Самый простой способ включить свои данные в вопрос, это использовать dput () при создании кода R. Например, чтобы воссоздать набор данных mtcars в R, достаточно выполнить следующее шаги:
а) Запустите dput (mtcars) в R
б) Скопируйте выходные данные
в) В демонстрационном скрипте введите mtcars<– и вставьте ранее скопированное. Попробуйте найти наименьшее подмножество ваших данных, которое приводит к появлению проблемы.
3) Потратьте немного времени на то, чтобы проверить, что ваш код легко читается другими участниками. Для этого: убедитесь, что использовали пространство и ваш имена переменных лаконичны, но информативны; используйте комментарии, чтобы указать, где именно возникла проблема; сделайте все возможное, чтобы удалить все, что не связано с демонстрируемой проблемой. Чем короче ваш код, тем проще его использовать, понять, и тем легче его исправить.
4) Закончите, проверив, что действительно сделали воспроизводимый пример путем запуска нового сеанса R, копирования и вставки своего скрипта внутрь.
В любом случае, необходимо потратить некоторое время на подготовку, чтобы можно было решать проблемы до их возникновения. Инвестирование времени в обучение R каждый день на долгосрочной перспективе окупится сторицей. Принимайте активное участие в обсуждениях перспективных проектов на блоге RStudio, там размещаются объявления о новых пакетах, публикуются новые возможности интегрированной среды разработки и разрабатываются индивидуальные курсы. Чтобы идти в ногу со временем и сообществом R в более широком смысле, рекомендуется чтение http://www.r-bloggers.com: оно объединяет более 700 блогов пользователей R со всего мира. Если являетесь активным участником социальной сети Twitter, то подпишитесь на обновления по хэштегу #rstats, так как Twitter является одним из ключевых инструментов, который используют разработчики на R. Эта книга не просто вольный пересказ новостей компании занимающейся активной разработкой R, а результат долгой и плодотворной самостоятельной работы. С публикациями автора, в которых оказались применены описываемые инструменты статистической обработки информации в педагогических, биологических и химических областях на базе научных и исследовательских лабораторий ОмГПУ, можно ознакомиться на сайте https://www.researchgate.net.
§2. Визуализация и преобразование данных
Цель первой главы состояла в том, чтобы получить быстрое знакомство с основными инструментами исследования данных. Ведь исследование данных это в первую очередь искусство просмотра ваших данных, быстрая генерация гипотез, быстрая их проверка, а затем повторение этого процесса снова, и снова. Цель предварительного исследования данных заключается в том, чтобы сгенерировать как можно больше многообещающих идей, которые можете будет развить позднее.
Во второй части книги изложены некоторые полезные инструменты, которые дают немедленную отдачу по следующим причинам:
1) Визуализация прекрасна для начала работы в R, потому что выигрыш очевиден, научитесь делать элегантные и информативные графики, которые помогут понять собранные данные. Погрузитесь в визуализацию изучая основное содержимое библиотеки ggplot2, и узнаете мощные методы превращения табличных данных в графики.
2) Визуализация сама по себе, как правило, не является достаточной для полноценного исследования, потому что в последующей трансформации данных ключевое место занимают визуально обнаруживаемые тренды, наглядная фильтрация наблюдений, создание новых переменных и вычисление сводных данных.
3) Наконец, в исследовательском анализе данных, приходится сочетать визуализацию и преобразования с вашим любопытством и скептицизмом, чтобы задать и ответить на интересующие вопросы о данных.
Моделирование является важной частью исследовательской работы, но порой не хватает навыков, чтобы эффективно этому обучиться для многократного применения. Вернемся к моделированию, как только освоим большое количество инструментов для обработки и программирования данных.
Среди последующих глав, сконцентрированных на изложении инструментов исследования, присутствует описание рабочих процессов. В соответствующем разделе разбираются основы рабочего процесса, автоматизация сценариями, на примере готовых решений иллюстрируются ведущие практики написания и организации R-кода. Это настроит на успех в долгосрочной перспективе, так как даёт инструменты для реализации конкретных проектов.
Как было показано во введении, простой график приносит больше информация для ума аналитика, чем любое другое представление данных. Покажем, как визуализировать данные с помощью ggplot2. В R имеется несколько систем для построения графиков, но ggplot2 является одним из самых элегантных и самых универсальных, так как ggplot2 реализует графический язык, схожий в системе описания и построения графиков. С ggplot2, многое делается быстрее, изучив одну систему команд можно применять её в самых неожиданных местах.
Если хотите узнать больше о теоретической основе ggplot2, то прежде, чем продолжить, рекомендуется прочитать специализированную учебную литературу по компьютерной графике. А в данной главе сфокусируемся на ggplot2, как одном из основных членов библиотеки tidyverse. Для доступа к наборам данных, справке и функциям, которые мы будем использовать в этой главе, загрузите tidyverse запустив следующую строку кода на исполнение:
library(tidyverse)
Эта одна строка кода загружает ядро tidyverse, пакеты, которые будут использоваться практически при каждом анализе данных. После её выполнения в консоли показывается, какие функции из tidyverse конфликтуют с функциями в базе R (или из других пакетов, которые могли быть загружены). Если запустите этот код и получите сообщение «Ошибка в library(tidyverse) :нет пакета под названием ‘tidyverse’», то нужно будет сначала установить его, а затем снова запустить library() следующим образом:
install.packages("tidyverse")
library(tidyverse)
Достаточно однократно установить пакет, но необходимо подгружать его каждый раз, когда открываете новую рабочую сессию. Если потребуется в явном виде указать из какого пакета вызывается функция (или набор данных), то будем использовать специальную нотацию с двойным двоеточием, например, ggplot2::ggplot() сообщает явным образом, что мы используем функцию ggplot() из пакет ggplot2. Давайте разберем первый график из предыдущей главы, чтобы ответить на a вопрос: используют ли автомобили с большими двигателями больше топлива, чем автомобили с маленькими двигатели? Аналогично риторическому: лучше ли осваивают математику ученики в специализированных физико-математических классах, чем ученики обучающиеся в классах с минимальным количеством уроков математики? Вы, вероятно, уже знаете ответ, но попробуйте конкретизировать. Какова взаимосвязь между размером двигателя и топливная эффективность, либо взаимосвязь между количеством учебного времени, выделяемого на элементарную математику, и успехами страны в космической отрасли, как она выглядит: положительно? отрицательно? линейно? нелинейно?
Вы можете проверить свой ответ с помощью базы данных mpg хранящейся в ggplot2 (она же ggplot2::mpg). База данных представляет собой таблицу переменных (в столбцах) и наблюдаемых значений (в строках). База mpg содержит наблюдения, собранные американскими агентством по охране экологии на 38 моделях автомобилей.
Среди прочих переменных в базе mpg хранятся:
1. displ, – объем двигателя автомобиля, в литрах;
2. hwy, – топливная экономичность автомобиля на шоссе, в милях на галлон (mpg).
Автомобиль с низкой топливной экономичностью потребляет больше топлива, чем автомобиль с высокой топливной эффективностью, когда они проедут одно и то же расстояние. Чтобы узнать больше о содержимом mpg, откройте ее страницу в справке.
Чтобы визуализировать mpg, запускается следующий код, который отобразит displ на ось x и hwy на ось y:
ggplot (data = mpg) +
geom_point (mapping = aes (x = displ, y = hwy))
По графику становится очевидной отрицательная связь между размером двигателя (displ) и топливной экономичностью (hwy). Другими словами, автомобили с большими двигателями использует больше топлива, равно как и большее количество учебного времени приводит к заведомо лучшим результатам обучающихся. Может ли это подтвердить или опровергнуть гипотезу о топливной экономичности и размере двигателя?
С помощью ggplot2 можно начать построение графика с помощью функции ggplot(). ggplot() создает систему координат, которую можно наполнить слоями. Первый аргумент функции ggplot() это набор данных, используемый в диаграмме. Таким образом, ggplot(data=mpg) создает пустой график, но это не очень информативно. Вы завершите построение графика, добавив один или несколько слоёв в ggplot(). Функция geom_point() добавляет слой точек.
В общем случае, ggplot2 используется со многими функциями категории geom, каждая из которых добавляет отдельный слой к графику, на протяжении этой главы они еще будут упомянуты.
Каждая функция geom в ggplot2 принимает аргумент, который определяет, как переменные в наборе данных сопоставляются с визуальными свойствами. Аргумент mapping всегда сопряжен с функцией aes(), а аргументы x и y в функции aes () определяют, какие переменные нужно сопоставить осям x и y соответственно. ggplot2 ищет сопоставленные переменные в данных аргумента, например, в таблице mpg.
Перепишем код в виде многоразового шаблона для построения графиков с помощью ggplot2. Чтобы построить график, достаточно заменить заключенные в угловые скобки фрагменты в коде ниже на наборы данных, функцию geom, либо на соответствия по осям:
ggplot(data = <данные>) +
<функция geom>(mapping = aes(<функция geom ><соответствие>))
В дальнейшем разберем детально, как заполнить и расширить этот шаблон, чтобы построить графики различных типов. Начнем с компоненты <соответствие>.
Упражнения
1. Запустите ggplot(data=mpg). Что получится?
2. Сколько строк находится в mpg? Сколько там колонок?
3. Что описывает переменная drv? Прочитайте справку по mpg, введя в консоли ?mpg, чтобы выяснить это.
4. Сделайте диаграмму рассеяния hwy относительно cyl.
5. Что произойдет, если попытаться создать диаграмму рассеяния переменной class относительно drv? Почему такого графика нельзя построить?
С эстетической точки зрения, картина тем ценнее, чем больше она заставляет нас замечать то, чего мы никогда не ожидали увидеть. На анализируемом графике обнаруживается одна группа точек (выделенная оранжевым цветом для автомобилей класса 2-Seater, «двуместные») в которой кажется, что они выходят за пределы линейного тренда. Эти автомобили имеют более высокий пробег, чем можно было бы ожидать. Как объяснить подобное? Давайте предположим, что данные автомобили являются гибридами. Один из способов проверить эту гипотезу – посмотреть на значение переменной class для каждого автомобиля. Переменная class из набора данных mpg разделяет автомобили на такие группы, как compact, midsize и SUV. Если выделяющиеся точки являются гибридными автомобилями, их следует классифицировать как компактные автомобили или, возможно, малолитражные (имейте в виду, что эти исторические данные были собраны раньше, чем стали популярными гибридные грузовики и внедорожники).
Можно добавить третью переменную, например class, к двумерному графику исходя из эстетических соображения. Эстетика – это визуальное свойство объектов в вашей диаграмме. Эстетика включает в себя такие вещи, как размер, форма или цвет точек. Изобразим точки различными способами путем изменения перечисленных значений свойств их оформления. Так как мы уже используем это слово "значение" для описания числовых данных, то будем использовать слово "уровень" для описания художественных, нечисловых, эстетических свойств. Мы меняем уровни размера, формы и цвета точки, чтобы сделать точка маленькая, треугольная или синяя.
В результате, появляется возможность передать информацию о данных с помощью сопоставление эстетики на графике с переменными в наборе данных. Например, можно сопоставить цвета точек (color) с переменной класса автомобиля (class), чтобы выявить класс каждого автомобиля. Для этого, после x = displ, y = hwy в список аргументов функции aes() через запятую необходимо добавить color = class.
Чтобы отобразить настройки форматирования в переменную, сопоставляется имя настраиваемого параметра, например цвета (color), с именем переменной внутри aes(). ggplot2 автоматически присвоит уникальный цвет для каждого уникального значения переменной, а также добавит объяснение, какие уровни каким значениям соответствуют.
Цветом показано, что многие из необычных точек охватывают двухместные автомобили. Эти автомобили не похожи на гибриды, и выглядят, по сути, как спортивные автомобили. Спортивные автомобили имеют большие двигатели, такие как внедорожники или пикапы, но небольшие кузова, такие как средние и компактные автомобили, что улучшает их экономичность. В ретроспективе, эти автомобили вряд будут гибридами, так как у них есть большие двигатели.
В приведенном выше примере сопоставлен класс с цветом, но можно сопоставить класс с размером точки точно так же. В этом случае размер каждой точки будет демонстрировать классовую принадлежность. Достаточно лишь заменить color = class на size = class, но будет получено предупреждение от интерпретатора, так как сопоставление неупорядоченной переменной (class) с упорядоченной категорией размера (size) не самая лучшая идея.
#> Предупреждение: использование параметра size для дискретной переменной не рекомендуется.
Кроме того, можно сопоставить класс с уровнем прозрачности точек (alpha), либо с их формой (shape). Для этого достаточно заменить color = class на alpha = class, либо на shape = class соответственно. Но в последнем случае ggplot2 может использовать только до шести фигур одновременно, по умолчанию все остальные группы будут отключены.
Для каждой эстетики используется aes(), чтобы связать имя эстетического объекта с переменной для отображения. Функция aes() собирает вместе каждое из эстетических отображений, используемых слоем и передает их в аргумент отображения слоя. Синтаксис выделяет полезную информацию об осях x и y: расположение объектов x и y, точки сами по себе являются эстетикой, визуальными свойствами, которые можно отобразить к переменным для демонстрации данных. После того, как настроена эстетика, ggplot2 заботится обо всём остальном. Выбирается оптимальный масштаб для использования, строится легенда, которая объясняет условные обозначения. Для координатных осей x и y функция ggplot2 не создает легенду, но будут построены осевые линии с делениями и метками. Линия оси сама по себе выступает в качестве легенды, так как она объясняет связь между расположением и координатами точек.







