


Полная версия
Основы статистической обработки педагогической информации
(-1)^(1/2)
#> [1] NaN
(-1+0i)^(1/2)
#> [1] 0+1i
Можно создавать новые объекты с помощью оператора <-:
x <– 2*2
Все команды R, которыми создаются объекты путём присваивания, имеют одинаковую форму:
имя_объекта <– получаемое_значение
При чтении этого кода в вашей голове может прозвучать: объект «имя_объекта» получает значение «получаемое_значение». В дальнейшем понадобится решать много интересных задач, набирая большие тексты при этом. Не ленитесь, используя знак =, он тоже будет работать, но позднее приведет к путанице. Вместо этого используйте клавиатурное сокращение RStudio: Alt + – (знак минус) для быстрого набора <-. Обратите внимание, что RStudio автоматически окружает <– пробелами. Приятно читать хорошо оформленный код, поэтому недайсвоимглазамсломаться, используйте пробелы.
Имена объектов должны начинаться с буквы и могут содержат только буквы, цифры, нижнее подчеркивание «_» и точку «.», вы ведь хотите, чтобы имена объектов были информативны, поэтому понадобится соглашение для склеивания нескольких слов. Мне привычнее змеиный_стиль, в котором строчные слова разделяются нижним подчеркиванием «_».
НекоторыеЛюдиИспользуютВерблюжийСтиль,
третьи.Вовсе_ОТКАЗЫАВЮТСЯОтусловностей.
Вернемся к стилю позже, в разделе посвященном описанию функций. А пока, можно проверить содержимое ранее созданного объекта, введя его имя:
x
#> [1] 4
Выполните эксперимент, введите:
это_действительно_длинное_имя <– 777
Чтобы проверить значение этого объекта, попробуйте в RStudio средство завершения строки: введите «это» и нажмите клавишу Tab, либо Ctrl + Space (пробел), добавятся недостающие символы, так как пока этот префикс уникален, а затем нажмите клавишу Enter. А что, если это_действительно_длинное_имя должно было иметь значение 1234, а не 777. Можно использовать другое сочетание клавиш, чтобы исправить его. Введите «это» и нажмите Ctrl + ↑. Появится список всех ранее набранных команд, которые начинаются с таких букв. Воспользовавшись стрелками навигации и нажав Enter, выбранная команда наберется повторно. Тогда можно будет изменить значение параметра с 777 на 1234 и выполнить ввод.
Еще один поучительный эксперимент, вместо х введём
икс
#> Ошибка: объект 'икс' не найден
X
#> Ошибка: объект 'X' не найден
Существует негласная договоренность между пользователем и R: за вас будут делать все рутинные вычисления, но взамен, нужно быть абсолютно точным в своих инструкциях. Как видим, система чувствительна к регистру.
R имеет обширную коллекцию встроенных функций, которые вызываются так:
имя_функции(аргумент1 = значение1, аргумент2 = значение2, …)
Давайте попробуем вызвать функцию seq(), которая генерирует регулярные последовательности чисел, и на её примере узнать больше полезных особенностей RStudio. Введите se и нажмите Tab. Всплывающее окно покажет возможные завершения. Укажите seq(), введя дополнительное «q», чтобы снять двусмысленность, или используйте стрелки ↑/↓ для выбора из предложенных вариантов. Обратите внимание на всплывающую подсказку, в ней перечислены аргументы функции и их назначение. Если хотите открыть справку, то нажмите клавишу F1, чтобы получить все подробности на соответствующей вкладе в правой нижней части панели управления. Нажмите клавишу Tab еще раз, когда выбрали функция, которую хотите вызвать. RStudio добавит соответствующие открывающиеся «(» и закрывающиеся «)» скобки. Введите аргументы 1, 5 и нажмите Enter.
seq(1, 5)
#> [1] 1 2 3 4 5
Введите следующий код и обнаружите, что RStudio также помогает с кавычками:
x <– "привет мир!"
Дело в том, что кавычки и круглые скобки всегда должны следовать в паре. RStudio делает всё возможное, чтобы помочь с их расстановкой. Если произойдет какое-либо несоответствие, то R подскажет:
> x >
+
Символ «+» говорит о том, что консоль R ожидает продолжения ввода. Обычно это означает, что забыли закрыть кавычки «"», либо скобки «)». Добавьте недостающие символы, либо нажмите клавишу Esc, чтобы начать ввод заново.
При решении задач не терпится узнать результат вычислений, поэтому вводят имя объекта, чтобы увидеть его содержимое:
y <– seq(1, 5, length.out = 4)
y
#> [1] 1.000000 2.333333 3.666667 5.000000
Это частое действие сокращается путём заключения команды в круглые скобки:
(y <– seq(1, 5, length.out = 4))
#> [1] 1.000000 2.333333 3.666667 5.000000
Теперь посмотрим на панель в правом верхнем углу окна RStudio:
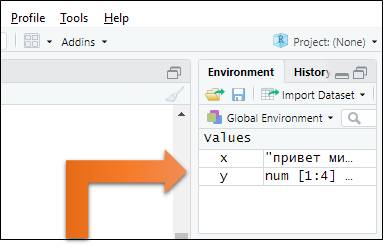
Здесь можно увидеть все объекты, которые были созданы ранее.
Упражнения
1. Скопируйте и вставьте в консоль:
label <– 1
lаbel
# > Ошибка: объект 'lаbel' не найден
Почему этот код не работает? Смотрите внимательно! Может показаться бессмысленным, но разница в написании a-латиницей и а-кириллицей для R существенна.
2. Нажмите Alt + Shift + K (латинское). Что произошло? Как добраться до того же экрана из главного меню приложения?
До сих пор использовали консоль для запуска код. Это неплохо для начала, но восприятие его оказывается невозможным довольно быстро, как только создаются более сложные конструкции ggplot2 при построении графиков с применением каналов dplyr. Чтобы использовать больше рабочего пространства, нужно открыть редактор скриптов. Откройте его, выбрав пункт меню «File», а затем «New File» и «R Script», либо с помощью сочетания клавиш Ctrl + Shift + N. Появится новая панель:
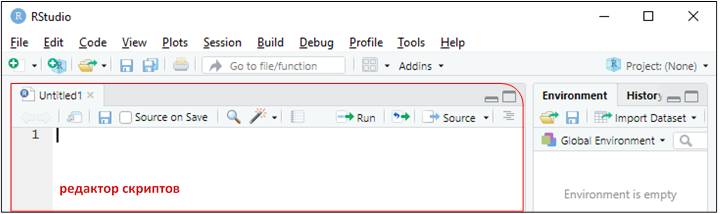
Редактор отлично подходит для просмотра кода и его набора. Можно экспериментировать в консоли, но как только написан код, который работает и делает то, что задумывалось, поместите его в редактор скриптов. RStudio автоматически сохранит содержимое редактора при выходе и будет автоматически загружать его при следующем входе. Тем не менее, чтобы не потерять набранное, лучше сохранять скрипты регулярно.
В редакторе скриптов отлично проходит сборка и отладка сложных графиков ggplot2 из длинных последовательностей команд dplyr. Ключом к эффективному использованию любого редактора является запоминание горячих клавиш и клавиатурных сокращений. Наиболее востребованным сочетанием клавиш редактора скриптов RStudio является Ctrl + Enter, оно выполняет текущее выражение R в консоли. Например, возьмем любой код из предыдущей главы. Если курсор находится внутри некоторой команды, то нажатие Ctrl + Enter запустит команду целиком и переместит курсор к началу следующей команды. Эта возможность используется для пошагового выполнения сценариев, путём многократного нажатия Ctrl + Enter.
Вместо того, чтобы запускать сценарий шаг за шагом, можно выполнить сохраненный сценарий целиком, нажав Ctrl + Shift + S. Рекомендуется делать это регулярно, чтобы проверить, все ли важные части кода сохранены. Начинать свой код желательно с команд подключения необходимых для запуска пакетов. Таким образом, если поделитесь кодом с другими исследователями, то они смогут легко увидеть, какие пакеты предстоит установить при необходимости. Однако никогда не нужно включать команды принудительной установки пакетов install.packages() или изменения рабочего каталога setwd() в распространяемом скрипте, признаком дурного тона является изменение настроек на чужом компьютере.
Работая с фрагментами кода в последующих главах настоятельно рекомендуется открывать их редактором и использовать различные клавиатурные сокращения. Со временем отправка кода на исполнение в консоль станет настолько естественной, что даже не будете думать об этом.
Редактор скриптов хорош тем, что выделяет синтаксические ошибки красной волнистой линией и крестиком на боковой панели. Наведите указатель мыши на крестик, чтобы увидеть, в чем проблема. RStudio укажет и потенциальные ошибки в программе.
Упражнения
1. Найти один совет, который выглядит интересный. Практикуйтесь в его использовании.
2. Какие распространенные ошибки показывает RStudio при диагностике кода?
В завершении главы скажем немного слов об организации и структуре хранения данных для крупных проектов. Порой приходится переключаться с R на сопутствующие задачи, возвращаясь к анализу данных на следующий день. Или вовсе работать над несколькими задачами одновременно, каждая из которых задействует R независимо друг от друга. Наступит момент, когда в R нужно будет загрузить данные с внешних источников и отправить вычисленные результаты обратно на внешние носители. Чтобы справиться с этими жизненными ситуациями, нужно ответить для себя на два вопроса:
1. Что является результатом выполненного анализа, то есть что будет сохранено в итоговом отчете о проделанной работе?
2. Где это сохранить?
Для начинающего пользователя R нормально рассматривать окно RStudio как основную рабочую область R, в которой хранятся все необходимые данные и строки кода. Однако в конечном счете гораздо лучше основными считать R-скрипты. С помощью R-скриптов и файлов исходных данных всегда можно восстановить рабочее окружение, но намного сложнее восстановить не сохранившиеся R-скрипты. Для этого либо придется перепечатать код заново, допуская ошибки при наборе, либо тщательно перебирать записи в истории консоли R. Если настроить RStudio так, чтобы рабочее пространство не сохранялось между сеансами, это причинит некоторое кратковременное неудобство, потому что теперь, когда перезапускается RStudio, не будет открываться код, который запустился в прошлый раз. Но это спасёт от мучений в будущем, так как заставляет все важные манипуляции с данными прописывать в коде и сохранять отдельно. Нет ничего хуже, чем обнаружить через несколько месяцев сохранившиеся лишь результаты важного расчета в рабочем окне RStudio, а не сам расчет.
Существует пара клавиатурных сокращений, используемых чтобы убедиться в сохранности важной части кода в редакторе RStudio:
1. Нажмите Ctrl + Shift + F10, чтобы перезагрузить сеанс RStudio.
2. Нажмите Ctrl + Shift + S, чтобы повторно запустить текущую команду скрипта.
Для R есть понятие «рабочий каталог». Именно в рабочем каталоге ищутся файлы при загрузке, сохраняются по умолчанию файлы, которые отправляют на сохранение. RStudio показывает текущий рабочий каталог в верхней части окна консоли. Можно увидеть путь к рабочему каталогу отдельно, запустив в коде R функцию getwd(). Начинающие пользователи R выбирают в качестве рабочего каталог рабочего стола, каталог документов, или любой другой странный каталог на компьютере. Но очень скоро эволюционируют в плане организации расположения проектов по каталогам и при работе над крупным проектом меняют рабочий каталог R на более подходящий. Можно сменить рабочий каталог из кода R запустив команду setwd("/путь/до/нового/рабочего/каталога"). Но никогда не делайте так, это не тот способ, которым пользуются профессионалы R для настройки пути до рабочего каталога. Адресация путей и каталогов осложнена тем, что в операционных системах Mac, Linux и Windows применяются разные форматы для их записи. Есть три основных отличия:
1) Самое главное отличие заключается в разделителях компонентов путей. Mac и Linux используют косую черту «/», а Windows использует обратную косую черту «\». R может работать с любым типом разделителя, независимо от используемой платформы, но обратные косые черты зарезервированы для ввода управляющих символов, в частности, чтобы получить одну обратную косую черту, в строке пути нужно вводить две обратные косые черты. Поэтому рекомендуется всегда использовать стиль Linux/Mac и разделять фрагменты пути символом «/».
2) Абсолютные пути, то есть пути, которые указывают на фиксированное место, независимо от рабочего каталога, выглядят по-разному. В Windows они начинаются с буквы диска, например «C:», или с двух обратных косых черт, например, «\\имя_сервера», а в Mac/Linux они начинаются с косой черты «/», например, «/users/RStudio». Никогда не используйте абсолютные пути в скриптах, потому что они мешают обмену результатами исследований с другими разработчиками, ведь ни у кого нет в точности совпадающий структур каталогов.
3) Последнее отличие – ссылки на домашний каталог. Символ «~» является удобным обозначением для домашнего каталога, но в Windows на самом деле нет понятия «домашний каталог», поэтому «~» указывает на папку документов текущего пользователя.
Специалисты хранят все файлы, связанные общими целями и задачами (входные данные, R скрипты, аналитические результаты, рисунки) в одном каталоге. Эта житейская мудрость является распространенной практикой, так как RStudio имеет встроенную поддержку для её реализации посредством создания проектов.
Для создания нового проекта, который будет использоваться при работаете с оставшейся частью книги, достаточно выбрать в главном меню приложения пункт «File», а затем «New Project…». Назовите проект «практикум по статистике» и хорошенько подумайте, в какой каталог его поместить. Если не сделаете это сознательно, то потом очень трудно будет его найти. Как только создание проекта завершено, проверьте, что путь до каталога проекта совпадает с рабочим каталогом. Всякий раз, когда в коде ссылаются на файл через относительный путь, он будет искаться в рабочем каталоге.
Теперь введите в редакторе скрипа следующие команды
library(tidyverse)
ggplot(diamonds, aes(carat, price)) +
geom_hex()
ggsave("алмазы.pdf")
write_csv(diamonds, "алмазы.csv")
И сохраните файл, назвав его «алмазы.R». Далее, запустите этот скрипт, чтобы создать файлы PDF и CSV в каталоге проекта. Не беспокойтесь о деталях, их разберем подробнее чуть позже. А пока, выйдите из RStudio и откройте папку проекта, обнаружите там файл «практикум по статистике» с расширением «.Rproj». Дважды кликните по нему для повторного открытия проекта. Заметьте, что вернулись на место, где остановились, это тот же самый рабочий каталог и история команд, открылись все файлы, над которыми работали. Следуя описанным инструкциям имейте ввиду, что начинать новый проект лучше с пустого системного окружения, как чистого листа.
Если теперь выполнить поиск файл алмазы.pdf, то найдется PDF рядом со скриптом, который его создал (алмазы.R). Одновременно сохранились график и данные, по которым он строился. Предпочтительно сохранять данные кодом R, а не с помощью мыши или через буфер обмена, чтобы не исказить информацию.
Проекты RStudio формируют крепкую основу рабочего процесса. Для повышения эффективности стоит придерживаться следующих рекомендаций:
• Создавать отдельный проект RStudio для каждого аналитического проекта.
• Хранить файлы данных в папке проекта, для удобной загрузки их в R.
• Храните там же и скрипты, редактируя их, запуская по частям или целиком.
• Сохранять там же и выходных данных (графики, очищенные данные).
• Использовать только относительные пути, а не абсолютные.
В результате, всё необходимое для работы будет находится в одном месте, изолированном от других проектов.
§4. Статистический анализ данных
Эта глава посвящена освоению основных приёмов статистического анализа информации, полученной средствами визуализации и преобразований, при систематическом изучении педагогических данных. Основная задача отдельной дисциплины, называемой «исследовательский анализ данных», заключается в открытии новых характеристик данных, и решается неоднократным повторением следующих трех шагов:
1) Сформулируйте вопросы о ваших данных.
2) Ищите ответы с помощью визуализации, преобразований и моделирования.
3) Используйте обнаруженные закономерности, чтобы уточнить имеющиеся вопросы и сформулировать новые.
Описанное не является формальным процессом со строгим набором правил, это скорее «состояние ума». Во время первого этапа нужно чувствовать себя свободно, чтобы исследовать каждую идею, что приходить на ум. Некоторые из идей будут реализованы, другие заведут в тупик, но поскольку исследование продолжится, то можно будет сконцентрироваться на нескольких особо продуктивных направлениях, которые в конечном итоге разовьются при общении с другими людьми.
Визуализация и преобразования являются важной частью любого анализа данных, даже если данные представлены «на блюдечке с голубой каёмочкой», всегда нужно исследовать качество исходных данных. Предварительная подготовка является одним из ключевых этапов. Задайте вопросы о том, соответствуют ли имеющиеся данные ожидаемым или нет. Чтобы выполнить грамотную очистку данных, будут использованы все доступные инструменты: визуализация, преобразование и моделирование.
Опыт использования пакетов dplyr и ggplot2 в интерактивном режиме для генерации вопросов, поиска ответов, с последующей формулировкой новых вопросов, показывает, что всегда нужно искать хотя бы примерный ответ на один принципиальный вопрос, чем погрузиться в поиски точных ответов на несколько риторических. Основная цель второго этапа состоит лишь в том, чтобы пришло понимание исходных данных. Самый простой способ достижения этого – использовать вопросы как инструменты для руководства к действиям. Когда спрашиваете, вопрос фокусирует внимание на определенной части набора данных и помогает решить, какие графики, модели или преобразования предстоят. Как любое частное приложение ТРИЗ (теории решения изобретательских задач) это в основном творческий процесс. И как у большинства творческих процессов, ключ к тому, чтобы задавать качественные вопросы, заключается в генерации большого количества вопросов. В любых открытых системах закон перехода количества в качество неизбежно проявляется также, как закон единства и борьбы противоположностей. Да, трудно формулировать вопросы в начале исследования, но лишь до тех пор, пока не станет известно, какая информация содержится в анализируемом наборе данных. С другой стороны, каждый новый вопрос, который задается, откроет новый фрагмент мозаики и увеличить шанс на внеочередное научное открытие. Можно детализировать наиболее интересные моменты и формулировать вопросы, наводящие на размышления, продолжая каждый вопрос новым вопросом, основанным на уточненной информации.
Не существует общего правила, какие вопросы нужно задать, чтобы продвинуться в исследовании. Тем не менее, два типа вопросов всегда полезны для совершения открытия:
1) Какова вариативность значений внутри выборки?
2) Какова ковариация между различными выборками?
Ниже рассмотрим эти два вопроса. Будет объяснено, что такое вариация и ковариация, и показано несколько способов ответа на каждый вопрос. Чтобы обсуждение сделать плодотворным, определимся с терминами:
Переменная – это количество, качество или свойство, которое можно измерить.
Значение – это состояние переменной, полученное в процессе измерения. Значение переменной может изменяться между измерениями.
Наблюдение – это набор измерений, сделанных в аналогичных условиях. Обычно все измерения наблюдений делаются в одно время на одном объекте. Наблюдение может содержать несколько значений, каждое из которых связано с разными переменными, поэтому наблюдение порой считают точкой многомерного пространства данных.
Табличные данные представляют собой набор значений, каждое из которых ассоциируется с переменной и наблюдением. Табличные данные «аккуратны» если каждое значение помещается в отдельной ячейке, а каждая переменная в своей собственной колонке, каждое наблюдение в своей собственной строке.
До сих пор все данные, которые видели, были аккуратны, но в реальной жизни большинство данных не являются аккуратными, достоверными, точными, верными, значащими, поэтому будем возвращаться к идее предварительной очистки снова и снова.
Вариативность данных представляет собой тенденцию в изменениях значений переменной при её изменении от одного измерения к другому. Можно легко наблюдать вариативность данных в реальной жизни. Если измерить любую непрерывную переменную дважды, то получатся два разных результата, даже если измерять величины, которые постоянны, например скорость света. Каждый раз в измерение войдет небольшое количество погрешностей, варьирующихся от измерения к измерению. Категориальные переменные также могут меняться если их измерять на разных предметах (например, цвет глаз у разных людей), или в разное время (например, энергетические уровни электрона в разные моменты времени). Каждая переменная имеет свой диапазон вариации, который помогает извлечь интересную информацию. Самый лучший путь к пониманию вариативности заключается в визуализации распределения значений переменной.
Как именно визуализировать распределение переменной зависит от того, является ли переменная категориальной или непрерывной. Переменная называется категориальной, если она может принимать только одно значение из небольшого набора. В R категориальные переменные обычно сохраняются как факторы или вектора символов. Обычно распределение категориальной переменной демонстрируется с помощью гистограмм, высота прямоугольников которых показывает, сколько наблюдений имело то или иное значение переменной. Переменная является непрерывной, если она может принимать любое значение из потенциально бесконечного множества упорядоченных величин. Действительные числа и время в этом смысле являются примерами непрерывных переменных. Изучить распределение непрерывной переменной тоже можно используя гистограмму, если предварительно разбить данные на непересекающиеся интервалы. Дело в том, что гистограмма поделит ось x на равные промежутки, а затем вычислит высоту прямоугольника для представления числа наблюдений, которые попадают в каждый из отдельных промежутков. Можно установить фиксированную ширину интервалов гистограммы аргументом binwidth, который измеряется в единицах измерения переменной x. Всегда стоит проверить несколько разных значений параметра binwidths при работе с гистограммами, так как разная ширина прямоугольников поможет выявить закономерности. Если необходимо наложить несколько гистограмм на один график, то рекомендуется использовать функцию geom_freqpoly() вместо geom_histogram(), так как geom_freqpoly() выполняет тот же подсчет повторений, что и функция geom_histogram(), но вместо прямоугольников для отображения результата вычислений использует линии. Гораздо проще воспринять информацию, когда перекрываются линии разных цветов, а не прямоугольники.
Проиллюстрируем сказанное на примере визуализации сведений об успеваемости по Теме 2 из приведенной в Главе 2 базы данных:
ggplot(data = filter(My_table, Класс %in% c("7а","7б")),
mapping = aes(x = Тема2, colour = Класс)) +
geom_freqpoly(binwidth = 0.5)
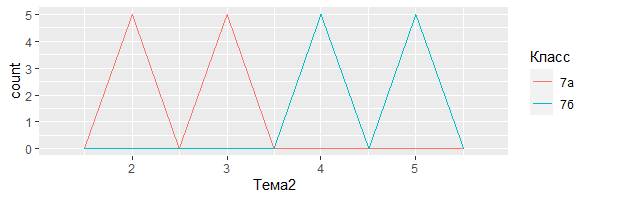
Есть несколько проблем, связанных с этим методом, но к ним ещё вернёмся, визуализируя категориальные и непрерывные переменные в дальнейшем. Теперь же, когда знаем, как визуализировать вариативность значений переменной, что следует искать на графиках? Какие вопросы задавать?
Ниже собран список типовых сведений, которые можно почерпнуть из графиков и диаграмм, с некоторыми последующими вопросами для каждого информационного блока. Ключом к хорошим формулировкам вопросов, следует считать любопытство (о чем хотите узнать больше?) и скептицизм (как это может ввести в заблуждение?).
Конец ознакомительного фрагмента.
Текст предоставлен ООО «ЛитРес».
Прочитайте эту книгу целиком, купив полную легальную версию на ЛитРес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.







