


Полная версия
Introduction
Data is perhaps the single most important aspect to your job, whether you want it to be or not. And you're likely reading this book because you want to be able to understand what it's all about.
To begin, it's worth stating what has almost become cliché: we create and consume more information than ever before. Without a doubt, we are in the age of data. And this age of data has created an entire industry of promises, buzzwords, and products many of which you, your managers, colleagues, and subordinates are or will be using. But, despite the claims and proliferation of data promises and products, data science projects are failing at alarming rates.2
To be sure, we're not saying all data promises are empty or all products are terrible. Rather, to truly get your head around this space, you must embrace a fundamental truth: this stuff is complex. Working with data is about numbers, nuance, and uncertainty. Data is important, yes, but it's rarely simple. And yet, there is an entire industry that would have us think otherwise. An industry that promises certainty in an uncertain world and plays on companies’ fear of missing out. We, the authors, call this the Data Science Industrial Complex.
THE DATA SCIENCE INDUSTRIAL COMPLEX
It's a problem for everyone involved. Businesses endlessly pursue products that will do their thinking for them. Managers hire analytics professionals who really aren't. Data scientists are hired to work in companies that aren't ready for them. Executives are forced to listen to technobabble and pretend to understand. Projects stall. Money is wasted.
Meanwhile, the Data Science Industrial Complex is churning out new concepts faster than our ability to define and articulate the opportunities (and problems) they create. Blink, and you'll miss one. When your authors started working together, Big Data was all the rage. As time went on, data science became the hot new topic. Since then, machine learning, deep learning, and artificial intelligence have become the next focus.
To the curious and critical thinkers among us, something doesn't sit well. Are the problems really new? Or are these new definitions just rebranding old problems?
The answer, of course, is yes to both.
But the bigger question we hope you're asking yourself is, How can I think and speak critically about data?
Let us show you how.
By reading this book, you'll learn the tools, terms, and thinking necessary to navigate the Data Science Industrial Complex. You'll understand data and its challenges at a deeper level. You'll be able to think critically about the data and results you come across, and you'll be able to speak intelligently about all things data.
In short, you'll become a Data Head.
WHY WE CARE
Before we get into the details, it's worth discussing why your authors, Alex and Jordan, care so much about this topic. In this section, we share two important examples of how data affected society at large and impacted us personally.
The Subprime Mortgage Crises
We were fresh out of college when the subprime mortgage crisis hit. We both landed jobs in 2009 for the Air Force, at a time when jobs were hard to find. We were both lucky. We had an in-demand skill: working with data. We had our hands in data every single day, working to operationalize research from Air Force analysts and scientists into products the government could use. Our hiring would be a harbinger of the focus the country would soon place on the types of roles we filled. As two data workers, we looked on the mortgage crisis with interest and curiosity.
The subprime mortgage crises had a lot of contributing factors behind it.3 In our attempt to offer it up as an example here, we don't want to negate other factors. However, put simply, we see it as a major data failure. Banks and investors created models to understand the value of mortgage-backed collateralized debt obligations (CDOs). You might remember those as the investment vehicles behind the United States’ market collapse.
Mortgage-backed CDOs were thought to be a safe investment because they spread the risk associated with loan default across multiple investment units. The idea was that in a portfolio of mortgages, if only a few went into default, this would not materially affect the underlying value of the entire portfolio.
And yet, upon reflection we know that some fundamental underlying assumptions were wrong. Chief among them were that default outcomes were independent events. If Person A defaults on a loan, it wouldn't impact Person B's risk of default. We would all soon learn defaults functioned more like dominoes where a previous default could predict further defaults. When one mortgage defaulted, the property values surrounding the home dropped, and the risk of defaults on those homes increased. The default effectively dragged the neighboring houses down into a sinkhole.
Assuming independence when events are in fact connected is a common error in statistics.
But let's go further into this story. Investment banks created models that overvalued these investments. A model, which we'll talk about later in the book, is a deliberate oversimplification of reality. It uses assumptions about the real world in an attempt to understand and make predictions about certain phenomena.
And who were these people who created and understood these models? They were the people who would lay the groundwork for what today we call the data scientist. Our kind of people. Statisticians, economists, physicists—folks who did machine learning, artificial intelligence, and statistics. They worked with data. And they were smart. Super smart.
And yet, something went wrong. Did they not ask the correct questions of their work? Were disclosures of risk lost in a game of telephone from the analysts to the decision makers, with uncertainty being stripped away piece by piece, giving an illusion of a perfectly predictable housing market? Did the people involved flat out lie about results?
More personal to us, how could we avoid similar mistakes in our own work?
We had many questions and could only speculate the answers, but one thing was clear—this was a large-scale data disaster at work. And it wouldn't be the last.
The 2016 United States General Election
On November 8, 2016, the Republican candidate, Donald J. Trump, won the general election of the United States beating the assumed front-runner and Democratic challenger, Hillary Clinton. For the political pollsters this came as a shock. Their models hadn't predicted his win. And this was supposed to be the year for election prediction.
In 2008, Nate Silver's FiveThirtyEight blog—then part of The New York Times—had done a fantastic job predicting Barack Obama's win. At the time, pundits were skeptical that his forecasting algorithm could accurately predict the election. In 2012, once again, Nate Silver was front and center predicting another win for Barack Obama.
By this point, the business world was starting to embrace data and hire data scientists. The successful prediction by Nate Silver of Barack Obama's reelection only reinforced the importance and perhaps oracle-like abilities of forecasting with data. Articles in business magazines warned executives to adopt data or be swallowed by a data-driven competitor. The Data Science Industrial Complex was in full force.
By 2016, every major news outlet had invested in a prediction algorithm to forecast the general election outcome. The vast, vast majority of them by and large suggested an overwhelming victory for the Democratic candidate, Hillary Clinton. Oh, how wrong they were.
Let's contrast how wrong they were as we compare it against the subprime mortgage crisis. One could argue that we learned a lot from the past. That interest in data science would give rise to avoiding past mistakes. Yes, it's true: since 2008—and 2012—news organizations hired data scientists, invested in polling research, created data teams, and spent more money ensuring they received good data.
Which begs the question: with all that time, money, effort, and education—what happened?4
Our Hypothesis
Why do data problems like this occur? We assign three causes: hard problems, lack of critical thinking, and poor communication.
First (as we said earlier), this stuff is complex. Many data problems are fundamentally difficult. Even with lots of data, the right tools and techniques, and the smartest analysts, mistakes happen. Predictions can and will be wrong. This is not a criticism of data and statistics. It's simply reality.
Second, some analysts and stakeholders stopped thinking critically about data problems. The Data Science Industrial Complex, in its hubris, painted a picture of certainty and simplicity, and a subset of people drank the proverbial “Kool-Aid.” Perhaps it's human nature—people don't want to admit they don't know what is going to happen. But a key part of thinking about and using data correctly is recognizing wrong decisions can happen. This means communicating and understanding risks and uncertainties. Somehow this message got lost. While we'd hope the tremendous progress in research and methods in data and analysis would sharpen everyone's critical thinking, it caused some to turn it off.
The third reason we think data problems continue to occur is poor communication between data scientists and decision makers. Even with the best intentions, results are often lost in translation. Decision makers don't speak the language because no one bothered to teach data literacy. And, frankly, data workers don't always explain things well. There's a communication gap.
DATA IN THE WORKPLACE
Your data problems might not bring down the global economy or incorrectly predict the next president of the United States, but the context of these stories is important. If miscommunication, misunderstanding, and lapses in critical thinking occur when the world is watching, they're probably happening in your workplace. In most cases, these are micro failures subtly reinforcing a culture without data literacy.
We know it's happened in our workplace, and it was partly our fault.
The Boardroom Scene
Fans of science fiction and adventure movies know this scene all too well: The hero is faced with a seemingly unsurmountable task and the world's leaders and scientists are brought together to discuss the situation. One scientist, the nerdiest among the group, proposes an idea dropping esoteric jargon before the general barks, “Speak English!” At this point, the viewer receives some exposition that explains what was meant. The idea of this plot point is to translate what is otherwise mission-critical information into something not just our hero—but the viewer—can understand.
We've discussed this movie trope often in our roles as researchers for the federal government. Why? Because it never seemed to unfold this way. In fact, what we saw early in our careers was often the opposite of this movie moment.
We presented our work to blank stares, listless head nodding, and occasional heavy eyelids. We watched as confused audiences seemed to receive what we were saying without question. They were either impressed by how smart we seemed or bored because they didn't get it. No one demanded we repeat what was said in a language everyone could understand. We saw something unfold that was dramatically different. It often unfolded like this:
Us: “Based on our supervised learning analysis of the binary response variable using multiple logistic regression, we found an out-of-sample performance of 0.76 specificity and several statistically significant independent variables using alpha equal to 0.05.”
Business Professional: *awkward silence*
Us: “Does that make sense?”
Business Professional: *more silence*
Us: “Any questions?”
Business Professional: “No questions at the moment.”
Business Professional's internal monologue: “What the hell are they talking about?”
If you watched this unfold in a movie, you might think wait, let's rewind, perhaps I forgot something. But in real life, where choices are truly mission critical, this rarely happens. We don't rewind. We don't ask for clarification.
In hindsight, our presentations were too technical. Part of the reason was pure stubbornness—before the mortgage crisis, as we learned, technical details were oversimplified; analysts were brought in to tell decision makers what they wanted to hear—and we were not going to play that game. Our audiences would listen to us.
But we overcorrected. Audiences couldn't think critically about our work because they didn't understand what we said.
We thought to ourselves there's got to be a better way. We wanted to make a difference with our work. So we started practicing explaining complex statistical concepts to each other and to other audiences. And we started researching what others thought about our explanations.
We discovered a middle ground between data workers and business professionals where honest discussions about data can take place without being too technical or too simplified. It involves both sides thinking more critically about data problems, large or small. That's what this book is about.
YOU CAN UNDERSTAND THE BIG PICTURE
To become better at understanding and working with data you will need to be open to learning seemingly complicated data concepts. And, even if you already know these concepts, we'll teach you how to translate them to your audience of stakeholders.
You'll also have to embrace the side of data that's not often talked about—how, in many companies, it largely fails. You'll build intuition, appreciation, and healthy skepticism of the numbers and terms you come across. It may seem like a daunting task, but this book will show you how. And you won't need to code or have a Ph.D.
With clear explanations, thought exercises, and analogies, we will help you develop a mental framework of data science, statistics, and machine learning.
Let's do just that in the following example.
Classifying Restaurants
Imagine you're on a walk and pass by an empty store front with the sign “New Restaurant: Coming Soon.” You're tired of eating at national chains and are always on the lookout for new, locally owned restaurants, so you can't help but wonder, “Will this be a new local restaurant?”
Let's pose this question more formally: Do you predict the new restaurant will be a chain restaurant or an independent restaurant?
Take a guess. (Seriously, take a guess before moving on.)
If this scenario happened in real life, you'd have a pretty good hunch in a split second. If you're in a trendy neighborhood, surrounded by local pubs and eateries, you'd guess independent. If you're next to an interstate highway and near a shopping mall, you'd guess chain.
But when we asked the question, you hesitated. They didn't give me enough information, you thought. And you were right. We didn't give you any data to make a decision.
Lesson learned: Informed decisions require data.
Now look at the data in the first image on the next page. The new restaurant is marked with an X, the Cs indicate chain restaurants, and the Is indicate independent, local eateries. What would you guess this time?
Most people guess (I) because most of the surrounding restaurants are also (I). But notice not all restaurants in the neighborhood are independent. If we asked you to rate your confidence5 in your prediction between 0 and 100, we'd expect it to be high but not 100. It's certainly possible another chain restaurant is coming to the neighborhood.
Lesson learned: Predictions should never be 100% confident.
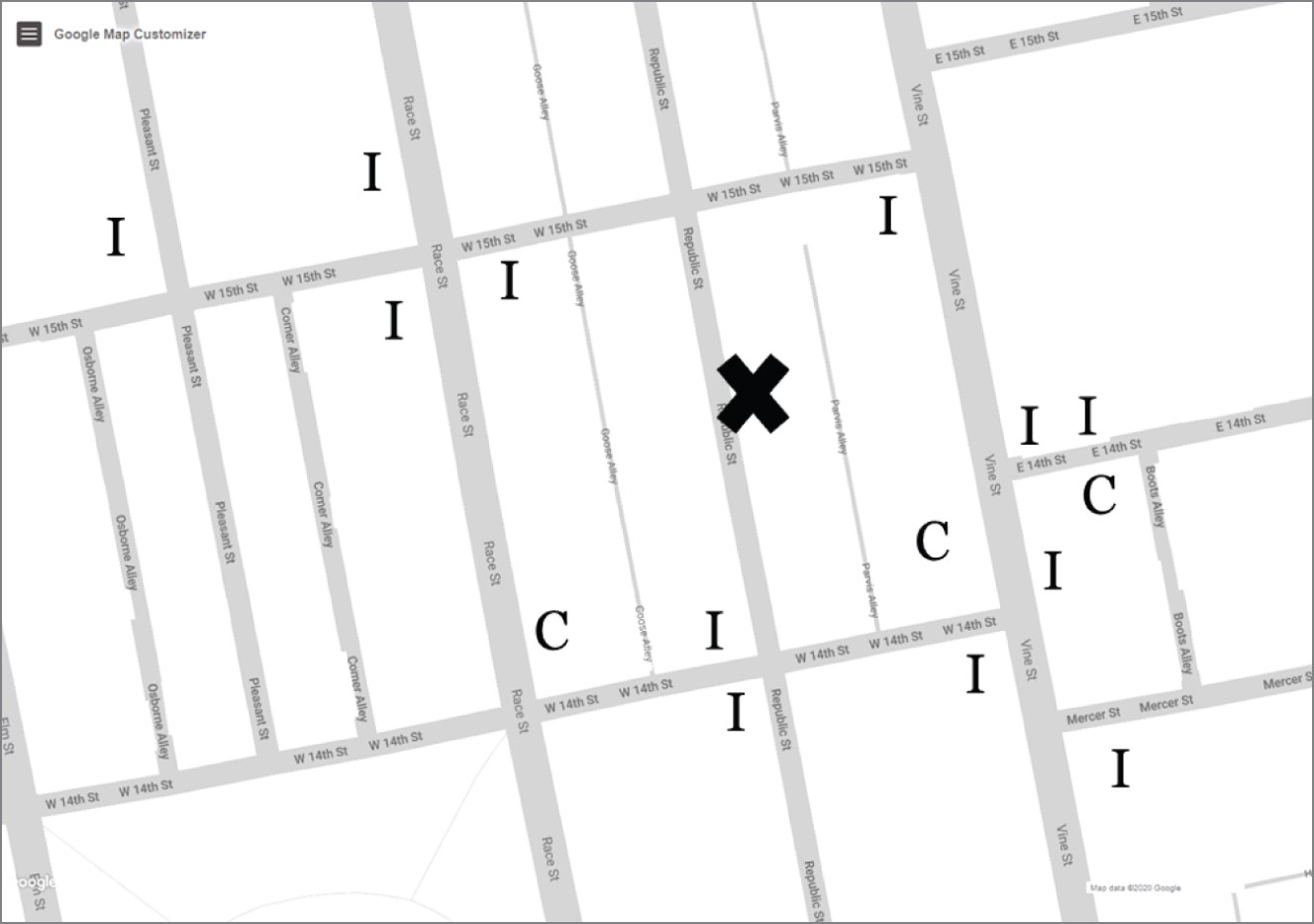
Over the Rhine neighborhood, Cincinnati, Ohio
Next, look at the data in the following image. This area includes a large shopping mall, and most restaurants in the area are chains. When asked to predict chain or independent, the majority choose (C). But we love when someone chooses (I) because it highlights several important lessons.
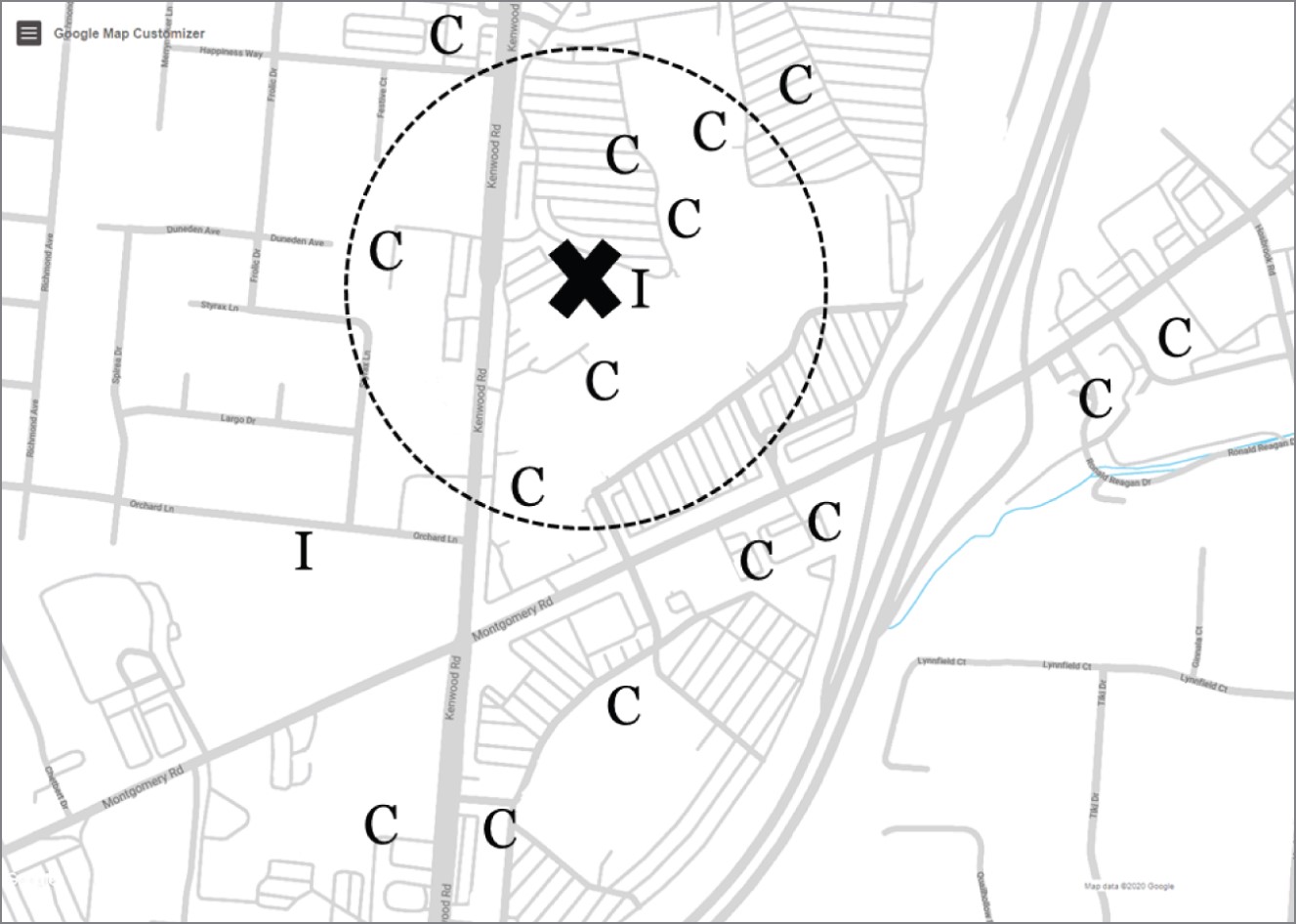
Kenwood Towne Centre, Cincinnati, Ohio
During this thought experiment, everyone creates a slightly different algorithm in their head. Of course, everyone looks at the markers surrounding the point of interest, X, to understand the neighborhood, but at some point, you must decide when a restaurant is too far away to influence your prediction. At one extreme (and we see it happen), someone looks at the restaurant's single closest neighbor, in this case an independent restaurant, and bases their prediction on it: “The nearest neighbor to X is an (I), so my prediction is (I).”
Most people, however, look at several neighboring restaurants. The second image shows a circle surrounding the new restaurant containing its seven nearest neighbors. You probably chose a different number, but we chose 7, and 6 out of the 7 are (C) chains, so we'd predict (C).
So What?
If you understand the restaurant example, you're well on your way to becoming a Data Head. Let's reveal what you learned, little by little:
■ You performed classification by predicting the label (chain or independent) on a new restaurant by training an algorithm using a set of data (restaurants’ location and their chain/independent label).
■ This is precisely machine learning! You just didn't build the algorithm on a computer—you used your head.
■ Specifically, this is a type of machine learning called supervised learning. It was “supervised” because you knew the existing restaurants were (C) chain or (I) independent. The labels directed (i.e., supervised) your thinking about how restaurant location is related to whether it's a chain or not.
■ Even more specifically, you performed a supervised learning classification algorithm called K-nearest-neighbor.6 If K = 1, look at the closest restaurant and that's your prediction. If K = 7, look at the 7 closest restaurants and predict the majority. It's an intuitive and powerful algorithm. And it's not magic.
■ You also learned you need data to make informed decisions. Realize, however, that you need more than that. After all, this book is about critical thinking. We want to show how stuff works but also how it fails. If we asked you to predict, given the data in this Introduction's images, if the new restaurant would be kid-friendly, you wouldn't be able to answer. To make informed decisions, not just any data will do. You need accurate, relevant, and enough data.
■ Remember the technobabble we wrote earlier? “… supervised learning analysis of the binary response variable …”? Congratulations, you just did a supervised learning analysis of a binary response variable. Response variable is another name for label, and it's binary because there were two of them, (C) and (I).
You learned a lot in this section, and you did it without even realizing it.
WHO THIS BOOK IS WRITTEN FOR
As established at the beginning of this book, data touches the lives of many of today's corporate workers. We came up with the following avatars to represent people who will benefit from becoming a Data Head:
Michelle is a marketing professional who works side-by-side with a data analyst. She develops the marketing initiatives and her data coworker collects data and measures the initiatives’ impact. Michelle thinks they can do more innovative work, but she can't articulate her data and analysis needs effectively to her data coworker. Communication between the two is a challenge. She's Googled some of the buzzwords floating around (machine learning and predictive analytics), but most of the articles she found used overly technical definitions, contained indecipherable computer code, or were advertisements for analytical software or consultation services. Her search left her feeling more anxious and confused than before.
Doug has a Ph.D. in the life sciences and works for a large corporation in its Research & Development division. Skeptical by nature, he wonders if these latest data trends are akin to snake oil. But Doug mutes his skepticism in the workplace, especially around his new director who wears a “Data is the New Bacon” t-shirt; he doesn't want to be viewed as a data luddite. At the same time, he's feeling left behind and decides to learn what all the fuss is about.
Regina is a C-level executive who is well-aware of the latest trends in data science. She oversees her company's new Data Science Division and interacts with senior data scientists on a regular basis. Regina trusts her data scientists and champions their work, but she'd like to have a deeper understanding of what they do because she's frequently presenting and defending her team's work to the company's board of directors. Regina is also tasked with vetting new technology software for the company. She suspects some of the vendors’ claims about “artificial intelligence” are too good to be true and wants to arm herself with more technical knowledge to separate marketing claims from reality.
Nelson manages three data scientists in his new role. A computer scientist by training, Nelson knows how to write software and work with data, but he's new to statistics (other than one class he took in college) and machine learning. Given his somewhat related technical background, he's willing and able to learn the details, but simply can't find time. His management has also been pushing his team to “do more machine learning,” but at this point, it all seems like a magic black box. Nelson is searching for material to help him build credibility within his team and recognize what problems can and cannot be solved with machine learning.
Hopefully, you can identify with one or more of these personas. The common thread among them, and likely you, is the desire to become a better “consumer” of the data and analytics you come across.
We also created an avatar to represent people who should read this book but probably won't (because every story needs a villain):
George: A mid-level manager, George reads the latest business articles about artificial intelligence and forwards his favorites up and down his management chain as evidence of his technical trendiness. But in the boardroom, he prides himself on “going with his gut.” George likes his data scientists to spoon-feed him the numbers in one or two slides, max. When the analysis agrees with what he (and his gut) decided before he commissioned the study, he moves it up the chain and boasts to his peers about enabling an “Artificial Intelligence Enterprise.” If the analysis disagrees with his gut feeling, he interrogates his data scientists with a series of nebulous questions and sends them on a wild goose chase until they find the “evidence” he needs to push his project forward.
Don't be like George. If you know a “George,” recommend this book and say they reminded you of “Regina.”
WHY WE WROTE THIS BOOK
We think a lot of people, like our avatars, want to learn about data and don't know where to start. Existing books in data science and statistics span a wide spectrum. On one side of the spectrum are non-technical books extolling the virtues and promise of data. Some of them are better than others. Even the best ones feel like the modern-day business books. But many of them are written by journalists looking to add drama around the rise of data.
These books describe how specific business problems were solved by looking at a problem through the lens of data. And they might even use words like artificial intelligence, machine learning, and the like. Don't get us wrong, these books create awareness. However, they don't delve deeply into what was done, instead focusing specifically on the problem and the solution at a high level.