

 полная версия
полная версияУмный бизнес: пострекламное перевооружение
Для активного клиента постулат о приоритетности товара уже не работает. Помимо прямого описания товара/услуги, технических и эксплуатационных характеристик клиенту может потребоваться и любая дополнительная информация: история компании, описание бизнес процессов и регламентов, новости и пресс-релизы, отзывы, аккаунты работников в социальных сетях. Возможно, клиенту нужно оценить ориентацию на клиента в компании и для этого очень пригодится фоторепортаж о корпоративном празднике. Или, клиент ищет высоко инновационный продукт и ему нужно «пощупать» интеллектуальный уровень работников, здесь здорово подошли бы резюме работников.
Идея о полезности косвенной информации уже стихийно проникает в бизнес, особенно, в умный бизнес. Зайдите на сайты дизайнеров интерьера. Естественно, там есть портфолио, то есть, образцы выполненных работ. Но теперь там полно дополнительной информации. К примеру, способы проектирования, описание материалов, виды оборудования, практические кейсы. Дизайнеры чувствуют потребность в такой информации, и, чтобы каждый раз не пересказывать её, просто выкладывают на сайт накопленный материал.
Многослойные клиенты
Интернет не только возродил активного клиента, но и сломал привычную структуризацию аудитории. Одной целевой аудитории оказывается теперь явно недостаточно. В рекламную эпоху бизнес напрямую, без промежуточных звеньев передавал информацию клиенту. Телевизионный ролик должен был смотреть непосредственно «наш» клиент, так, как только в его подсознании должен был сохраниться навязываемый образ. В пострекламную эру появляются переносчики информации. Самый очевидный пример: блогеры, сетевые активисты, отраслевые критики/аналитики. В широком смысле подобных специалистов можно было бы назвать «экспертами». Понятно, что эксперты не просто выполняют роль почтальонов, но и вносят в информацию добавленную стоимость. Например, могут включить свою эмоциональную оценку, от восторга до ненависти. Могут провести неплохое техническое или аналитическое сравнение.
Всем известный, но все равно удивительный пример переносчика информации – это контактный переносчик. Сейчас всем привычны простые инструменты для мгновенного обмена информацией: электронная почта, кнопка «поделиться» в социальных сетях и мессенджерах. Например, мужчина может переслать информацию о женских сумках женщине, если ему показалось, что у адресата может быть какой-то интерес к этим сумкам. Точно также, женщина может переслать мужчине случайно попавшую к ней информацию о бензопилах, если перед этим был какой-то разговор о ремонтной технике. В обоих случаях контактный переносчик не сохраняет в своем подсознании пересылаемую информацию. Достаточно помнить, что кому-то может быть интересна данная информация, и это уже станет побуждающим мотивом к передаче информации. Часто даже не нужно иметь в виду конкретную персону – интересанта. Можно просто «делиться» приглянувшейся информацией в социальных сетях и через один-два шага информация может найти прямого интересанта.
Важнейшим переносчиком информации становится цифровой интеллект поисковых систем, об этом подробнее в разделе Цифровой интеллект.
Наличие переносчиков информации делает структуру аудитории многоуровневой или сетевой. Примерный вид диаграммы аудитории показан на следующем рисунке.

Соответственно, возникают разные каналы для переноса информации от бизнеса к конечному клиенту. Говоря более узко, появляются разные каналы трафика на сайт компании. Сами каналы теперь перестают иметь однолинейный характер и приобретают сложный сетевой вид.
Цифровой интеллект
1. Задачей настоящего раздела является изложение темы искусственного интеллекта в максимально популярном стиле. Предполагается, что читатель ранее глубоко не погружался в детали работы цифрового разума.
К настоящему времени наука об искусственном интеллекте относится к самым сложным разделам современной математики. Для полноценного освоения механизмов работы интеллекта требуется длительное время. С другой стороны, для использования в бизнесе нет необходимости знать и понимать все детали. Достаточно сформировать ограниченное понимание о работе интеллектуальных алгоритмов.
2. Дополнительно с темой искусственного интеллекта можно ознакомится в предшествующей книге «Семантический Ренессанс», см. раздел Предшественники.
3. Искусственный интеллект прямо связан с технологией текстового поиска от компаний Яндекс и Гугл. Было бы правильно давать ссылки на обе компании, но так не получается. Автору пришлось ограничиться ссылками на Яндекс, так у Гугла мало русскоязычных материалов. Тем не менее, все сказанное в данном разделе в равной степени относится к обеим компаниям.
4. Все глаголы, связанные с интеллектуальным действием – думать, полагать, считать и им подобные – применяются без кавычек, если обозначают действие компьютера.
Яндекс в последние 1-2 года выступил с рядом кардинальных заявлений:
– поисковая технология далеко ушла от простого текстового поиска;
– текстовый поиск трансформирован в смысловое ранжирование с присвоением семантического рейтинга;
– ранг (рейтинг) каждой веб-страницы измеряет цифровой интеллект.
Человеку, еще не знакомому с проявлениями искусственного интеллекта, наверное, как-то можно согласиться с первыми двумя заявлениями, но последнее заявление может показаться уже невероятном
Попробуем пошагово разобраться со способностями цифрового разума. После знакомства нам будет несложно сделать простые выводы о последствиях применения искусственного интеллекта.
Человечество не понимает разум человека
Критический взгляд на общую теорию разума
Практическое применение науки об искусственном разуме упирается в серьезную ментальную проблему. Если взять применение в практике иных наук, то здесь ментальных проблем не возникает. Например, уже лет 50 в авиастроении применяется титана. Здесь все понятно. Титан является легким, прочным и жаростойким металлом. Поэтому этот материал и востребован при создании самолетов.
Большинство проблем искусственного разума вытекает из того, что мы до конца не понимаем работу нашего человеческого разума. На настоящий момент отсутствует удовлетворительная и сравнительно полная теория интеллекта. Есть масса исследований и разума, и умственной деятельности, но единая теория до сих пор не построена.
Во всех других областях движение идет от общей теории к частным применениям. Теория электричества и магнетизма возникла на рубеже 18-19 веков. Лишь через 50 лет Лодыгин и Эдиссон изобрели электролампы. В это же время возникли электромоторы Органическая химия, химия соединений углерода и водорода была развита задолго до появления пластмасс в нашей повседневной жизни. Соответственно, есть специальности инженер-электрик, инженер-химик, но нет специальности «инженер по разуму».
Вопрос «что такое разум, как происходит деятельность человеческого мозга» возник одновременно с другими первичными научными вопросами. С самого начала появления письменности человек ставил себе подобные вопросы. Земля – это шар или плоскость? Почему Луна не падает на Землю, а вращается вокруг нее? С тех пор наука ушла далеко. Уже известно, что Земля имеет не просто форму шара, а форму особой фигуры – геоида. Мы понимаем движение планет, существование далеких от нас черных дыр. Наши ускорители залезли в тайны микромира. Тем не менее, полноценная теория мозга и умственной деятельности отсутствует. Наверное, мы неплохо знаем какие-то эпизоды, связанные с деятельностью мозга у человека и животных, но общая картина до сих пор ускользает от наших глаз.
У нас отсутствует простые определения, начинающиеся со слов «мозг – это…» или «умственная деятельность – это…». Вероятно, все сводится к банальной формуле «человек обладает интеллектом». Нетрудно видеть, что эта формула лишь маскирует отсутствие определения. Уже на следующие вопросы – «почему человек обладает умом», «кто, кроме человека может обладать интеллектом» – общепризнанный, логически корректный ответ отсутствует.
Точно также сомнительны любые тесты по измерению уровня интеллекта, включая самый знаменитый IQ, intellect quality. Почему бы не договориться, если АйКью меньше 10, значит интеллекта нет. Если больше – интеллект присутствует. Все бы хорошо, но те же эксперименты показывают, что тесты дают правильный ответ не всегда. Есть немало примеров заведомо статусных, признанных ученых с низким IQ.
Можно было бы уйти от общих философских конструкций и попробовать ограничиться некоторой математической моделью мозга. Скажем, по аналогии со школьной геометрией, построенной на 5 аксиомах Евклида. Пусть школьная геометрия не охватывает всю реальность, но, по крайней мере, у нас есть одна, вполне понятная модель, причем с мощным практическим аппаратом. Именно на школьной геометрии построено все машиностроение и черчение. На удивление, на аксиоматическом пути вырастают свои проблемы, типа теорем Гёделя о неполноте арифметики.
Какие достижения все-таки существуют
Конечно, нельзя впадать в другую крайность и говорить об отсутствии любых продвижений в исследованиях умственной деятельности. Бесспорно, таких достижений множество. Достаточно вспомнить нашего физиолога Павлова, лауреата Нобелевской премии за теорию рефлексов.
В наше время цифровой интеллект, Artificial Intelligence является значимым научным направлением. К примеру, на самом известном агрегаторе научной информации https://arxiv.org , есть раздел, посвященный только искусственному интеллекту, https://arxiv.org/list/cs.AI/recent . Агрегатор arxiv.org управляется Cornell University, USA и дает возможность быстрой публикации практически без рецензионного фильтра. Ученые со всего мира сначала публикуют статью в arxiv.org, чтобы «застолбить» свой приоритет, и лишь затем продвигают статью в статусные, но рецензируемые журналы. Как видим, на ресурсе arxiv.org тема искусственного интеллекта позиционируется наравне с самыми продвинутыми областями физики и математики. Интерес к теме демонстрируется и количеством статей. В среднем 100 статей в одну неделю от авторов со всего мира. Это весьма немало и сравнимо с такими разделами, как биофизика.
Искусственный интеллект и СМИ
Любой вдумчивый читатель тут же спросит, почему же при отсутствии полноценной теории разума (и человеческого, и искусственного), массовая литература и СМИ заполнены упоминанием цифрового разума. Особенно, в последние несколько лет искусственный интеллект появился даже в тех разделах бытия, где непонятно, при чем тут-то искусственный интеллект.
Есть три причины упоминания в массовых СМИ искусственного интеллекта, как реально существующего аналога человеческого разума.
Первая причина связана со сложностью знаний о разуме. Часто, можно понять журналиста, у которого просто физически нет времени разобраться с точным позиционированием вопроса, о котором он пишет. Проще применить универсальную отсылку «это искусственный интеллект». Такой ссылкой журналист сразу выводит за скобки необходимость погружения в цифровые детали.
Вторая причина вызвана простыми коммерческими соображениями. Журналист может и понимать науку искусственного разума, но ему выгоднее представить тему в грандиозном стиле. Написал про цифровой интеллект, а у читателя начинает шевелиться пещерный страх или тело охватывает необъяснимый восторг и возникает неустранимое желание прочитать весь текст.
Третья причина философски сложная: можно говорить об отсутствии общей теории и одновременно говорить о существовании верифицированных интеллектуальных компонент, другими словами, говорить об ограниченном подобии человеку. Детально говорим об этом в следующем разделе.
Вывод:
термин «искусственный разум» можно использовать как в общих теориях, так и в частных применениях, но, говоря о его применении на практике, стоит всегда помнить про отсутствие общей теории разума.
Точное понимание – человекоподобие
Вероятно, вместо термина «искусственный интеллект» стоило бы использовать термин «человекоподобие». Конечно, этот термин не дает хайпа, но зато отражает состояние знаний о разуме значительно точнее. В любом случае, если все же приходится пользоваться громким словом «искусственный интеллект», по крайней мере для себя стоит
подразумевать вместо искусственного интеллекта ограниченное человекоподобие.
При таком подходе гораздо легче рассуждать о практических применениях.
Ограниченное человекоподобие можно описать следующим образом. Как говорилось в предыдущем разделе, человечество на текущем этапе не имеет общей теории разума. Попробуем поставить задачу с другого направления. Давайте вычленим отдельные компоненты умственной деятельности и уже для этих компонент будем строить непротиворечивые и верифицированные теории. Попробуем сравнить, насколько отдельные компоненты работы компьютера подобны процессам-аналогам в умственной деятельности человека. Оказывается, так можно делать, и именно этот путь стал кардинальным в современной науке об интеллекте.
Тьюринг
Впервые это понял Тьюринг, основатель современных направлений в науке по умственной деятельности и собственно компьютерной науки. В 1950 году он сконструировал легко реализуемую на практике ситуацию, в которой можно анализировать интеллектуальные способности компьютера, знаменитый тест Тьюринга.
Представьте три комнаты. В первой сидит простой человек, случайно отобранный. Во второй работает компьютер. В третьей действует эксперт, то есть тоже человек. Эксперт придумывает вопросы. Вопросы могут быть любыми, например, «у любого человека есть мать?» или «Лондон, это столица Англии?». Есть только одно ограничение, формулировка вопроса должна допускать строго один ответ из двух возможных, «Да» или «Нет». Эксперт набивает свои вопросы на компьютере. Вопросы тут же поступают в комнаты №1 и №2, естественно, по кабелям. Человек в первой комнате набивает свой ответ. Компьютер во второй комнате создает формулировку ответа в своей оперативной памяти. Оба ответа поступают обратно на компьютер эксперта. Каждый ответ помечен как «ответ из комнаты №1» или «ответ из комнаты №2».
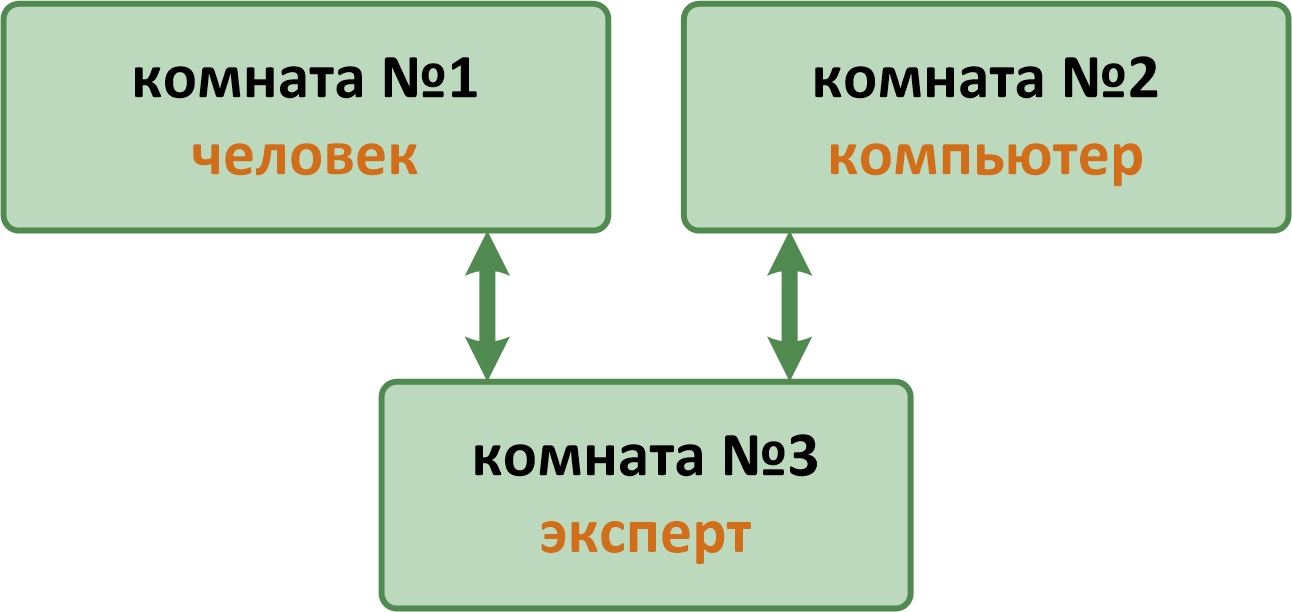
Вся хитрость в том, что эксперт не знает в какой комнате сидит человек, а в какой комнате работает компьютер. Эксперту ставят ограничение на число вопросов, скажем не более 100. Когда вопросы завершаются, эксперт должен указать в какой комнате сидел человек, а в какой комнате работал компьютер.
Считается, что машина прошла тест Тьюринга, если эксперт не может указать, в какой комнате работает машина.
В реальности и в целях точности эксперимент повторяется много раз, с разными экспертами. Если большинство экспертов правильно указали комнату компьютера, то машина не прошла тест. Если по мнению экспертов ответы из двух комнат интеллектуально равноценны, то считается, что машина прошла тест.
Если тест пройден, то у машины появляется некое основание на признание у этой машины некоторой степени интеллекта. Зато обратное утверждение носит абсолютный характер, если машина не прошла тест, то у нее нет никакого интеллекта.
Тест Тьюринга поражает своей простотой, ориентированностью на реальность и на практическое использование в отличие от общетеоретических и общефилософских построений. Именно поэтому тест Тьюринга лежит в основе всей современной и науки, и практики об искусственном интеллекте.
По Тьюрингу искусственный интеллект еще не создан
Понятно, что цель пройти тест Тьюринга мотивировала массу разработчиков. Хотя здесь очевидна необходимость в специальном процессоре, мощной памяти и особом программном обеспечении, но вряд ли для подобного проекта были бы ограничены ресурсы. Несмотря на столь мощный стимул, на 2019 год не было объявлено об успешном прохождении теста Тьюринга.
Так что, стоит повторить еще раз:
любые объявления о существовании искусственного интеллекта являются лишь маркетинговым приемом.
Ни один компьютер пока не может пройти полный тест Тьюринга. То есть, все монстры, состоящие из тысяч сверхмощных процессоров, с чудовищным по человеческим меркам быстродействием не могут обмануть человека в тесте, придуманном 70 лет назад.
Более того, в момент, когда будет создан компьютер, который пройдет тест Тьюринга, этот факт не будет означать наличие полноценного интеллекта у машины. Это лишь первый шаг на длинном пути. Тут же появятся следующие тесты. Например, по проявлению эмоций, по способности сочинять музыку, по способности производить новые знания. В конце концов, по способности решать математические задачи.
Машина может пройти ограниченный тест
Нетрудно создать ограниченный тест Тьюринга, когда эксперт может создавать вопросы только из весьма ограниченной области человеческой деятельности. Например, можно сузить тему до «классическая музыка 19 века». В этом случае известны сообщения о верифицированном прохождении теста Тьюринга. Такой «региональный» чемпион неплохо будет отвечать про Моцарта и Чайковского, но слово «электромотор» введет его в тупик.
Ограниченный тест Тьюринга хорошо демонстрирует методологию ограниченного человекоподобия. Мы выделяем ограниченную область деятельности и для этой области строим машинный аналог.
Кстати, такие ограниченные аналоги появились уже давно. Человечество просто очень быстро привыкает к подобным достижениям.
Машина складывает быстрее человека
Долгое время, буквально тысячелетия такие простые операции, как сложение и вычитание арифметических чисел казались верхом интеллектуальной деятельности. Попробуйте научить обезьяну складывать числа – не получится. До 20 века представить, что некое устройство может выполнять такие действия казалось невозможным. Затем появились механические арифмометры, которые складывали два числа, за счет вращения рукоятки. Это было удобно, но не вызывало удивления, так как механизм арифмометра был виден нашими глазами, было понятно какая шестеренка двигает рычаги. В конце концов, арифмометр можно было просто разобрать и понять действие каждой детали.
Совсем невозможным казалось, что машина может складывать и вычитать в миллионы раз быстрее человека. В первые годы после появления компьютеров, в 1950-е годы печать была заполнена объявлениями о быстродействии машин. СМИ сообщали о каждом новом и невероятном рекорде быстродействия. Эта способность машины точно также шокировала публику, как и полет в космос.
Сейчас мы уже привыкли к быстродействию компьютера, привыкли к калькуляторам. Мы даже забываем навыки быстрого устного счета.
Машина выигрывает у человека в шахматы
После победы компьютера в чемпионате на скорость сложения считалось, что компьютер может побеждать в простых операциях, но в сложной интеллектуальной работе человек не победим. Долгие века символом такой насыщенной интеллектом деятельности считалась игра в шахматы. Даже по способности играть в шахматы оценивали уровень интеллекта.
Понятно, что для компьютерных разработчиков шахматы стали следующей мишенью. Прежде всего, в силу формализуемости шахмат, все шахматные правила легко переводятся на язык формул математики и логики. Появилась цель объявить шахматный чемпионат «машина-человек» и выиграть у чемпиона мира. Это свершилось уже в далеком 1996 году, когда чемпион мира по шахматам Г. Каспаров впервые проиграл матч специально разработанному шахматному компьютеру Deep Blue. В наше время специальный компьютер уже не требуется. Программа в обычном смартфоне обыграет большинство людей.
Распознавание образов существует уже давно
Не стоит думать, что тема цифрового интеллекта, а точнее человекоподобных систем возникла лишь в последние годы. На самом деле, тема существует уже лет 60-70, правда, без громкого медийного сопровождения. Мощным стимулом было военное соревнование США – СССР. Скажем, «распознавание образов» впервые возникло как задача заблаговременного распознавания ядерной атаки. Атакуемая сторона имеет всего лишь 20 минут для принятия решения при появлении первичных сигналов об атаке. Это реальная атака, или ложное срабатывание. В силу ограничений по времени, лишь машина может получить какое-то решение. Человек может быть и является финальным контролером, но анализ всех сигналов может производить лишь машина. В те годы этой задачей занимались масса ученых и инженеров и в СССР, и в США. В наше время теория распознавания образов применяется в массе приложений. В частности, в практике распознавания лиц в системе уличного видеонаблюдения. С точки зрения технологии распознавание ракет или установление человеческих лиц вполне подобны.
Экспертные системы тоже возникли давно
Одновременно с распознаванием образов возникло немало так называемых экспертных систем. Чем выше цивилизационный уровень страны, тем выше ценность главного ресурса – экспертности. Настоящих экспертов начинает банально не хватать по мере роста собираемой информации.
Соответственно, еще 50 лет назад возникла задача замены экспертов цифровыми алгоритмами.
Простейший пример связан с анализом геологической разведки. Полезные ископаемые можно искать простейшим способом – пробурить через каждый километр скважину глубиной 5 км. Достать образцы грунта и провести их полный анализ. Способ хороший, но невозможный ввиду безумной дороговизны. Есть методы дешевле. Например, акустическая разведка. Делается малый взрыв на поверхности. Территория вокруг центра взрыва заполняется множеством датчиков, который записывают прохождение звука через землю. Аналогично можно проводить электроразведку. Здесь возникает задача восстановления подземной структуры по данным от датчиков. В какой-то степени такая разведка напоминает медицинский метод МРТ по сканированию внутренностей человека. МРТ диаграмму расшифровывает специальный врач. С данными геологической разведки сложнее. Тут нужно либо множество экспертов, либо специальные цифровые алгоритмы. Подобные экспертные системы давно созданы. В любой серьезной геологической компании могут показать 3D модель реального месторождения.
Для последующего чтения и анализа
Сейчас в Интернете представлено громадное число материалов по искусственному интеллекту. Можно самостоятельно поискать и подобрать материалы с необходимым уровнем погружения в проблему.
В качестве следующего после этой книги шага автор мог бы порекомендовать весьма серьезное интервью, которое Ольга Ускова дала Владимиру Познеру, https://youtu.be/sMd5idtt4TM . Для справки: О. Ускова, известная российская предпринимательница. Еще в 1992 году она стала основателем фирмы Cognitive Technologies, https://www.cognitive.ru/ . Нетрудно видеть близость названия компании к теме цифрового разума.
Вывод:
всякий раз, говоря о проявлении искусственного интеллекта, на самом деле мы имеем в виду какую-то ограниченную часть деятельности, где работа компьютера оказывается подобной работе человеческого мозга, где компьютер дает результат, подобный результату от человека.
Поисковые технологии
Взглянем на работу поисковых компаний с учетом небольшого ликбеза про цифровой интеллект, а точнее про человекоподобные системы, представленный в предыдущих разделах. Понятно, что под поисковыми компаниями имеются в виду два основных монстра, Яндекс и Гугл.
Для начала отметим неудачность термина «поиск». Этот термин в равной степени относится и к простому текстовому поиску, и к работе сверхмощного поискового алгоритма, основанного на самой современной, высоко профессиональной математике. Приставка «поисковые» появилась у поисковых компаний и у поисковых технологий с самого первого дня их появления в мире. Вероятно, из-за кнопки «поиск» на странице создания текстового запроса. На тот момент приставка была адекватной. Теперь алгоритм поисковых компаний только в малой степени связан с поиском, тем не менее, названия остались и компании не хотят их менять в силу очевидных маркетинговых традиций.
Посмотрим на результат поиска компанией Яндекс в ответ на запрос «ипотека».
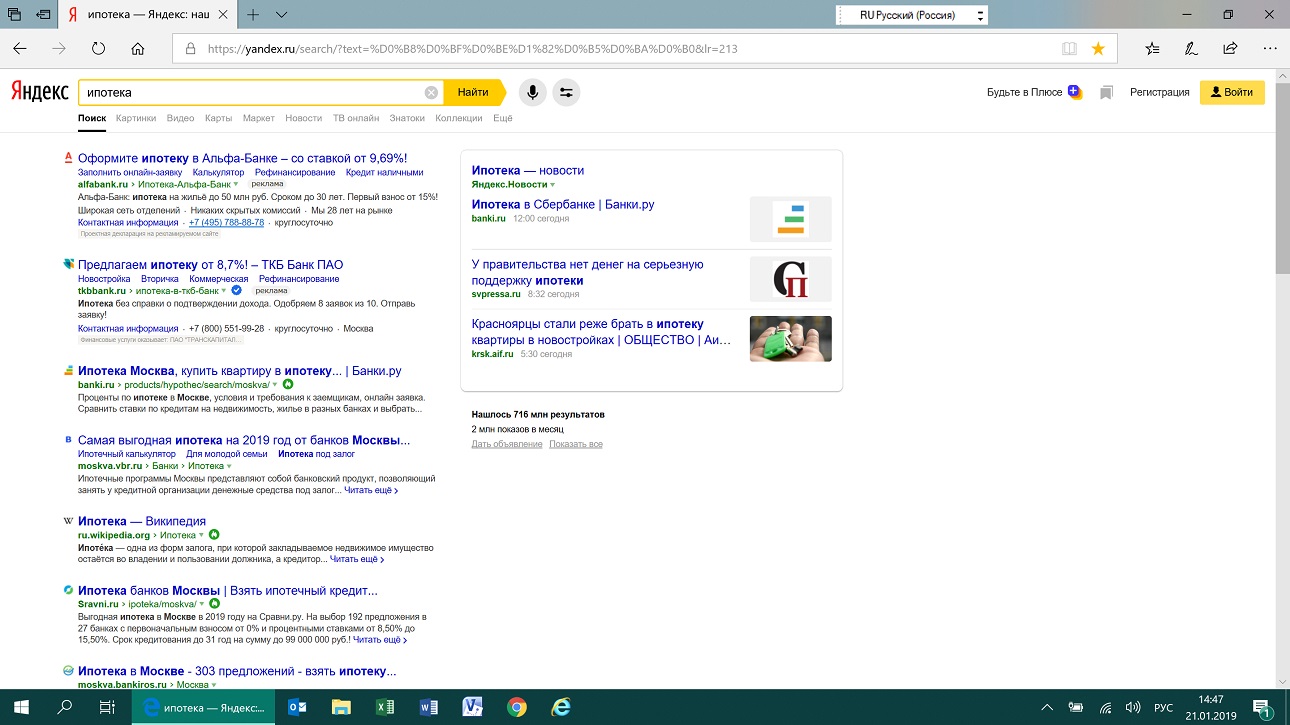
Мы сразу видим поражающий воображение факт. Более 700 миллионов веб-страниц содержат в своем тексте слово «ипотека» в той или иной словоформе. Примерно по 5 страниц на каждого жителя России, включая младенцев. Как будто мы все озабочены только ипотекой. Из этого безумного числа алгоритм Яндекса выбрал 10 страниц, что показаны на самых верхних позициях в поисковой выдаче. По мнению Яндекса – это самые важные страницы из ипотечной вакханалии. Самые полезные и информативные для пользователя
