


Полная версия
Manual of comparative linguistics
If we take each particular PAI value with corresponding coefficient of proximity we get that PAI of Austronesian is about 0.44.
If we take just arithmetical mean without proximity coefficients we get 0.6.
0.6 is obviously closer to real values of PAI of Austronesian languages than 0.44. Hence thereby it’s possible to state that just arithmetical mean is completely sufficient way to calculate PAI of a group/stock while PAI calculated with use of proximity coefficients gives results that differ seriously from reality.
2.1.6. PAI in diachrony
It can be supposed that PAI doesn’t change much in diachrony.
PAI of Late Classical Chinese is 0.5 (calculated after Pulleyblank 1995).
PAI of Contemporary Mandarin is 0.5. (calculated after Ross, Sheng Ma 2006).
PAI of Early Old Japanese is 0.13 (calculated after Syromyatnikov 2002).
PAI of contemporary Japanese is 0.13 (calculated after Lavrent’yev 2002).
Probably it should be also tested on other examples but even on the material of these examples we can see that PAI of a language is same in different stages of its history.
2.1.7. Summary of PAI method
One can probably say that Coptic has broken our hypothesis, but actually PAI just has shown us that group of Coptic language and Semitic group diverged very long ago, probably in Neolithic epoch yet.
However, the tests have shown that values of PAI of related languages are actually rather close, i.e.: they do not differ more than fourfold (pic. 3).
Thus, it is possible to say that PAI is something alike safety valve of comparative linguistics: if its values don’t differ more than fourfold then PAI has no distinction ability and actually there are no obstacles for further search for potential genetic relationship; but if values of PAI differ fourfold and more, then should be found absolutely ferroconcrete proves of genetic relationship.
Also I am specially to note that PAI method doesn’t require estimation of measurement error as far as PAI allows fourfold gap of values.
2.2. Why is it possible to prove that languages are not related?
2.2.1. Root of problem is changing of concepts
One can probably say that it is impossible to prove unrelatedness of two languages so I am to make some explanation on why it is possible.
In contemporary comparative linguistics there is a weird presupposition that it is impossible to prove that certain languages are not genetically related. As I can understand this point of view was inspired by Greenberg as well as some other obscurantist ideas of contemporary historical linguistics. It seems quite weird that it is possible to prove relatedness but it is not possible to prove unrelatedness. Let’s check whether it is so.
First of all, I am to note that statement about impossibility of proving unrelatedness is actually sophism based on changing of concepts, i.e.: when they speak about proves of relatedness then relatedness means “to belong to the same stock” and it is regular and normal meaning of the concept of relatedness in linguistics; however, when they speak about unrelatedness then meaning of relatedness suddenly changes: they start to suppose that actually all existing languages are related since they are supposed to be derivates of same proto-language that existed in a very distant epoch in past and due to this fact we can’t prove unrelatedness but can just state that a language doesn’t belong to a stock.
2.2.2. Concepts of relatedness and unrelatedness from the point of view of other sciences
In order to clear the meaning of the concept of relatedness it’s useful to pay some attention to other sciences where this concept also is used. If we take a look at, for instance: biology, physics or technical sciences we can see that many items are distributed by classes/classified despite they obviously have common origin; and considering them it is completely normal to speak about relatedness and unrelatedness. All being have common origin and so they all are relatives in a very deep level but this fact doesn’t mean they cannot be classified into kingdoms, phylums, classes, orders, suborders, families, subfamilies; the fact that ant, bear, pine tree, whale, sparrow have common ancestor doesn’t mean it is impossible to distinguish bear from whale and whale from pine tree.
However, as far as languages aren’t self replicating systems like biological systems and are closer to artifacts so any parallels between biological systems and language always should be made with certain degree of awareness since they are more allegories than analogies while correlations between languages and some artificial items are more precise, for instance: all existing cars are derivates of steam engine that existed in the middle of 19th century, but it doesn’t mean we can’t classify cars/engines and speak of relatedness and unrelatedness of certain types.
These examples evidently show us the following:
1) When they say about an item that is related with another it means “they both belong to the same class”.
2) It is possible to speak about relatedness and unrelatedness of certain items even though all classes of them have common origin.
2.2.3. Concepts of relatedness and unrelatedness from point of view of set theory and abstract algebra
Concept of relatedness is actually equivalence relation since it meets necessary and sufficient requirements for a binary relation to be considered as equivalence relation:
1) Reflexivety: a ~ a: a is related with a;
2) Symmetry: if a ~ b then b ~ a: if a is related with b then b is related with a;
3) Transitivity: if a ~ b and b ~ c then a ~ c: if a is related with b and b is related with c then a is related with c.
If an equivalence relation is defined on a set then it necessarily supposes grouping of elements of the set into equivalence classes and these classes aren’t intersected (Hrbacek, Jech: 1999).
2.2.4. Particular conclusions on the concepts of relatedness and unrelatedness for linguistics
When it is said that certain languages are genetically related (or simply related) it means that these languages belong to the same stock or even to the same group.
Taking into the consideration what has been said in 2.2.2 we should keep in mind that in the case of languages there are actually no positive evidences that all languages existing nowadays originated from the same ancestor, i.e.: monogenesis is still an unproved hypothesis, though anyway even if all languages can be reduced to the same proto-language that existed in a very distant past it doesn’t mean yet we can’t speak of their relatedness/unrelatedness.
Then, taking into consideration what has been said in 2.2.3 we can say the following:
The set of languages existing nowadays on the planet is rather well described: we know that there are about 7102 languages and about 151 stocks and 83 isolated languages (Ethnologue: 2015), so we can speak about 234 stocks; and we hardly can expect discovering of some new unknown languages. Thus, we can say that we have rather complete image of set of languages and that there are about 234 classes of equivalence/relatedness.
If we take an X stock, we obviously can show many languages which don’t belong to the stock, i.e.: languages which are not related with language x (a random language of X stock), for example: in the case of Indo-European stock there are many languages which are not related with English: Arabic, Basque, Finnish, Georgian, Turkish, Chinese, Japanese, Hawaiian, Eskimo, Quechua and so on. In the case of Sino-Tibetan stock there are many languages which aren’t related with Chinese: Arabic, English, Eskimo, Finnish, Japanese, Turkish, Vietnamese and so on.
Thus, we can conclude the following:
1) Relatedness means “language belongs to a stock” unrelatedness means “language doesn’t belong to a stock”.
2) If set of 234 classes/stocks has been set up then it obviously supposes that there should be a possibility of classification, i.e.: we can say whether a language belongs to a stock; moreover, we always can show some languages which don’t belong to the stock. If possibility to prove unrelatedness is denied then we actually can’t establish scopes of stocks and can’t distinguish one stock from another; then even a single stock hardly could have been assembled.
3) Any two randomly chosen languages can be related or not related, i.e.: there can be no “third variant” since relatedness/unrelatedness supposes the existence of classes which don’t intersect. If a language of X stock is related to a language of Y stock it means that these stocks are related.
4) Possible objection can be the following: one can probably say that it is impossible to make precise conclusions in linguistics. Actually, I don’t think someone can seriously say this, however, if someone would speak out something like this I can only point on the fact that very long ago people thought that precise conclusions are impossible in physics. Possibility of precise estimations and precise conclusions depends on scholars’ will and on scholars’ intellectual courage only, but not on material itself; any material can be represented as item that can’t be formalized, and many items have already been successfully formalized.
2.2.5. An important consequence: transitivity of relatendness/unrelatedness
If we have proven unrelatedness of an x language belonging to X stock with y language that belongs to Y stock then, due to transitivity of unrelatedness, it means that x is not related with the whole Y stock.
2.3. Applying PAI method to some unsettled hypotheses
2.3.1. PAI against Nostratic hypothesis
Basing on comparison of lexis adepts of Nostratic hypothesis state that Indo-European stock, Kartvelian stock, Uralic stock and Turkic stock are relatives. Let’s see and test whether, for instance, Indo-European and Turkic stocks could be relatives.
PAI of Indo-European is about 0.5 (calculated after data represented in 2.1.4.2);
PAI of Turkic stock is about 0.012 (calculated after Yazyki mira. Tyurkskiye yazyki 1996).
Values of PAI differ more than tenfolds so these stocks evidently can’t be genetically related.
2.3.2. Whether Ainu belongs to Altaic stock?
Having compared some randomly chosen lexemes, Patrie states that Ainu is a relative of Japanese and Korean and thus belongs to Altaic stock (Patrie 1982).
Whether Japanese and Korean are part of Altaic stock is still a discussed issue and even relationship of Japanese and Korean is still actually questionable. However, let’s accept Patrie’s proposition and let’s look at PAI of these languages.
PAI of Ainu is 0.75 (calculated after Tamura 2000);
PAI of Japanese is 0.13 (see 2.1.6);
PAI of Korean is 0.13 (calculated after Mazur 2004).
Values of PAI of Ainu and Japanese/Ainu and Korean differ sixfold.
In the case of Coptic language and Semitic group values of PAI differ fourfold and if there were no firm structural evidences relationship of Coptic language and Semitic group would be very problematic.
In the case of Ainu and Altaic stock serious difference of PAI values is obviously proof of absence of relatedness. Ainu and Korean, Ainu and Japanese are completely unrelated like, for instance, Spanish and Basque.
Moreover, we should keep in mind that Japanese and Korean have probably the highest values of PAI among languages of Altai stock so if we compare Ainu with some “true” languages of Altaic stock the difference is much more striking.
And also the fact there is almost no structural correlation between Ainu and Japanese and between Ainu and Korean corroborates conclusion made with the use of PAI.
2.3.3. PAI suggests that Buyeo stock seems to be real
Japanese and Korean seem to be closer relatives than it has been thought usually, since their PAI values completely coincide (see 2.3.2). And this fact correlates well with their structural and material correlation.
Anyway after discovering closeness of PAI values proximity of grammar systems should be shown.
The question of Japanese and Korean relationship is considered in (5.2).
2.3.4. PAI against Mudrak’s hypotheses
Mudrak believes that such languages as: Ainu, Nivkh, Chukchi-Koryak, Itelmen and Eskimo-Aleut are genetically related (Mudrak 2013).
2.3.4.1. Whether Ainu and Nivkh could be relatives
According to Mudrak Ainu and Nivkh not just belong to that hypothetical stock but belong to same group inside the stock (pic. 4).
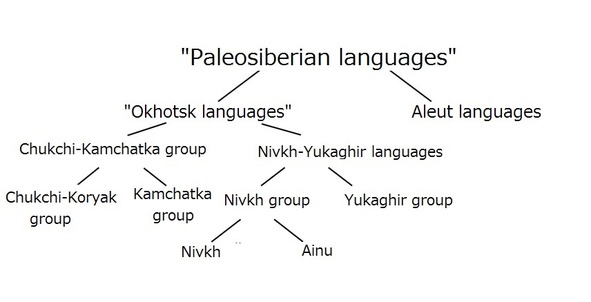
Pic. 4. Scheme representing genetic relationships of “Paleosiberian stock” languages accordingto Mudrak (source: [битая ссылка] http://polit.ru/article/2013/04/22/ps_mudrak_linguistics/ – accessed December 2015)
PAI of Nivkh is 0.07 (calculated after Gruzdeva 1997);
PAI of Ainu is 0.75.
Values differ more than tenfold.
Also grammars of Ainu and grammar of Nivkh show serious differences.
Hypothesis of Nivkh and Ainu relationship is same as for instance hypothesis of common ancestor of Estonian and Latvian spoken out by Nivkh or Ainu scientists (if Nivkh or Ainu would have scientists and European languages would be “indigenous languages”). It’s completely naïve and it’s based only on very perfunctory impression of some cultural similarities of Sakhalin Nivkh and Sakhalin Ainu.
2.3.4.2. Whether Ainu and Eskimo-Aleut could be relatives?
PAI of Aleut group and its relatives is zero (Golovko 1997: 115; Menovschikov 1997: 77). PAI of Ainu is 0.75. We have seen some well assembled groups and stocks and know how values of PAI can differ if languages really form a stock. As far as our current math, that we use to count values of PAI and estimate correlation of PAI values, doesn’t know division by zero so we can ascribe to the PAI of Aleut an obviously absurd value (for instance: 0.000001) in order to show the utmost absurdity of any attempts to represent Ainu and Aleut as languages belonging to the same stock.
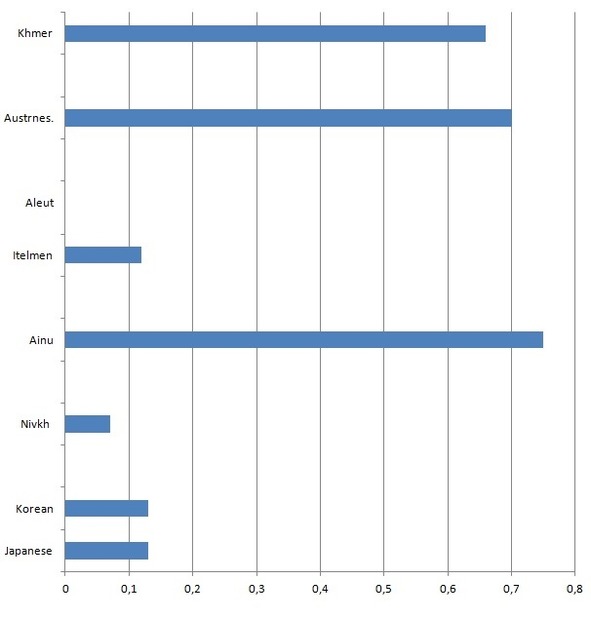
Pic. 5. Diagram representing PAI values of languages that don’t form stocks.
2.3.4.3. Against term “Paleosiberian”
The term “Paleosiberian languages” was invented to designate isolated languages of Siberia and Far East; it doesn’t mean a hypothetical stock but it is just a set of genetically unrelated languages assembled by their geographic location. Now it would be better to avoid use of this term as far as it doesn’t help to analyse and discover but just inspires development of megalocomparative obscurantism.
It would be better to use term “isolated languages and stocks of Siberia and Far East” rather than to explain every time true meaning of term “Paleosiberian” since it looks much alike name of stock, it looks too mystic and/or intriguing for random amaterish people could properly understand its meaning.
2.3.5. Potential relatives of Ainu seem to be in South
2.3.5.1. Ainu and Austronesian
Murayama believed that Ainu could be a distant relative of Austronesian (Murayama 1993).
Despite naïve lexicostatistic approach the idea potentially can be rather realistic since PAI of Ainu is 0.75 and PAI of Austronesian stock is about 0.6.
2.3.5.2. Ainu and Mon-Khmer
Vovin tried to show that Ainu was a distant relative of Austroasiatic (Vovin 1993). As well as in the case of Murayama the idea isn’t completely off base since PAI of Khmer is 0.66 that correlates well with that of Ainu. However, I am to note that such researches in the field of linguistics should be correlated with data of other sciences.
Any hypothesis about relationship of certain languages should be correlated with correspondent contexts and with data of other related sciences: physical anthropology, population genetics, cultural anthropology and archaeology: if a certain date has been set as an approximate time of existence of a Proto-Ainu then how words of contemporary Ainu can be found in preceding epochs? Also if certain ethnic group is thought to have influenced Ainu language then this group hardly could influence rice cultivating terminology (Nonno 2015: 44).
2.3.6. Particular conclusion about PAI method
1. PAI is something alike safety valve of comparative linguistics: if its values don’t differ more than fourfold then there is absolutely no obstacles for further research about genetic relationship; if values differ fourfold and more then should be found absolutely ferroconcrete proves of genetic relationship; if values differ sevenfold – tenfold or even more then those languages belong to different stocks.
It is possible to say that PAI shows direction in which looking for potential relatives of certain language can be perspectives.
2. PAI can be helpful method in those areas where are many isolated languages/stocks: in North America, in Papua and in Africa.
Конец ознакомительного фрагмента.
Текст предоставлен ООО «ЛитРес».
Прочитайте эту книгу целиком, купив полную легальную версию на ЛитРес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.
Примечания
1
Also nobody actually cares that sometimes certain lexemes can look alike just by coincidence: the shorter certain lexeme is the more is probability that it can look alike some random lexemes of other languages.
2
Megalocomparison is term invented by J. Matisoff (Matisoff 1990) specially to denote attempts to prove distant genetic relationship basing on comparison of lexis, i.e.: attempts to prove genetic relationship of certain languages in Greenberg style of so called “mass comparison”.
3
Buyeo stock is still a hypothetical stock that includes Japanese, Korean and Okinawan languages (Buyeo stock is discussed in chapter 5.2)
4
In this text I intentially use term stock instead of term family that is used in such context usually; languages are not self-replicating systems like biological systems, so I think any biological analogies should be avoided.
5
Waikuri is an extinct language that existed in Southern part of Baja California. Hokan stock is a hypothetical stock of a dozen small language families that were spoken mainly in California, Arizona and Baja California (pic. 1).
6
Due to “completely isolated” position among languages of the world Ainu is especially attractive material for perfunctory and amateurish hypotheses.
7
This type of linear model of word form is named “American type” since it has been described mainly on the material of Native American languages (especially of North America)
8
This type of linear model of word form is named “Altaiс type” since this linear model has been described mainly on the material of languages of so called Altaic stock.
9
PAN means Proto-Austronesian; “^” is sign of grammar/structure correlation