


Полная версия
Manual of comparative linguistics

Manual of comparative linguistics
Prefixation Ability Index (PAI) and Verbal Grammar Correlation Index (VGCI)
Alexander Akulov
Dedicated to the memory
of Prof. Alexander B. Valiotti
© Alexander Akulov, 2015
Created with intellectual publishing system Ridero
1. Why typology but not lexis should be the base of genetic classification of languages
In contemporary linguistics can be seen an obsession of proving relationship of certain languages by comparison of lexis and an obsession to separate typology from comparative linguistics. The main problem of all such hypotheses is that they are not based on any firmly testable methods but just on certain particular points of view and on “artist sees so” principle. Tendency to think that typology should be separated from historical linguistics was inspired by Joseph Greenberg in the West and by Segrei Starostin and Nostratic tradition in USSR/Russia. Despite followers of Nostractics insist that their methods differ from those of Greenberg actually their methods are almost the same: they take word lists, find some look-alike lexemes1 and on the base of these facts conclude about genetic relationship of certain languages. Followers of Greenberg and Starostin consider typological studies as rather useless “glass beads game”. Typological items are never considered as a system by adepts of megalocomparison2; usually some randomly chosen typological items are taken outside of their appropriate contexts. For instance, active or ergative typology, or the fact of so called isolating or polysintetic typology (i.e.: items that are not usual for native languages of researchers and that shock researchers’ minds) are considered as interesting exotic items, while no attention is paid to holistic and systematic analysis of language structures. Such approach makes typology be a “curiosity store” but not a tool of comparative linguistics, however, initially, according to founding-fathers of linguistics, it is typology that should be the main tool of comparative linguistics. According to the mythology created by adepts of megalocomparison comparative linguistics has actually little connection with typology and makes its statements with use of lexicostatistical “hoodoo”. Megalocomparativists often object on this critics saying that they also pay attention to structural issues and they also compare morphemes beside lexis. However, we know very well what actually means megalocomparative comparison of morphemes: it means analysis in a lexical way, i.e.: only material components are compared so there is no difference between such comparison of material components of morphemes and comparison of lexemes. The cause of it is the fact that megalocomparativists ignore that any morpheme consists of three components: meaning, position and material expression and reduce morpheme to their material implementation. Almost no attention is paid to the fact that grammar is first of all positional distribution of certain meanings. There is a presupposition that genetic relationship of two languages can be proved by discovering of look-alike lexemes of so called basic vocabulary and by detecting certain “regular phonetic correspondence”. However, yet Atoine Meillet pointed on the fact that lexical and phonetic correspondences can appear due to borrowings and can’t be proves of relationship:
Grammatical correspondences provide proof, and they alone prove rigorously, but only if one makes use of the details of the forms and if one establishes that certain particular grammatical forms used in the languages considered go back to a common origin. Correspondences in vocabulary never provide absolute proof, because one can never be sure that they are not due to loans (Meillet 1954: 27).
Correspondence in vocabulary and regular phonetic correspondence can be between any randomly chosen languages. For instance it is possible to find some regular correspondence between Japanese and Cantonese and even “prove” their relationship: boku Japanese personal pronoun “I” used by males – Cantonese buk “servant”, “I”; Japanese bō “stick” – Cantonese baang “stick”; Japanese o-taku “your family”, “your house” or “your husband” – Cantonese zaak “house”; Japanese taku “swamp” in compounds – Cantonese zaak “swamp”; Japanese san “three” – Cantonese sam; Japanese shin “forest” used in compounds – Cantonese sam “forest”; Japanese roku “six” – Cantonese lük; Japanese ran “orchid” – Cantonese laan “orchid”. If there would be no other languages of so called Buyeo3 stock4 and no languages of Chinese stock we would have no ability to single those words as items borrowed from Southern Chinese dialects since they have same regular and wide use as well as words of Japanese origin. In the case of Japanese and Cantonese we know history of correspondent stocks rather well and have many firm evidences that Japanese isn’t a relative of Chinese stock.
If someone thinks that the example of Japanese and Cantonese is just a weird joke, then everyone can take a look at the procedure that was used by Greenberg in order to prove that Waikuri language belonged to Hokan stock5: the conclusion was based on comparison of FOUR (!) words only (Poser, Campbell 1992: 217 – 218). Also we should keep in mind that Greenberg actually didn’t care much about precise phonetic correspondence and superficial likeness was rather sufficient for him.
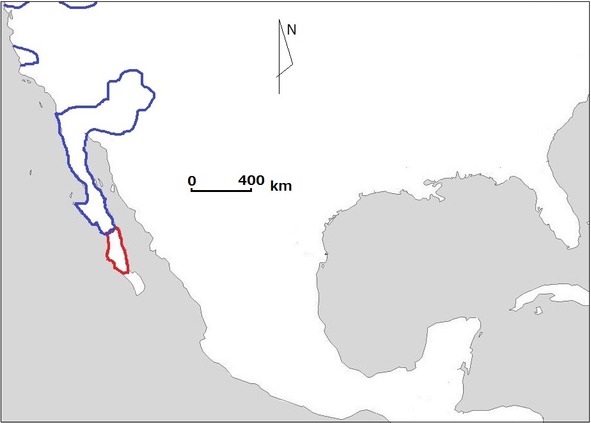
Pic.1. Map representing location of hypothetical Hokan stock (blue) and Waicuri language (red)
Phonetic correspondences themselves can be even between completely unrelated languages and so a stock can’t be proved by regular correspondences, but regular correspondences should be proven by existence of a stock since true regular phonetic correspondences exist only inside stocks.
Then, it was Swadesh yet who warned that comparison of vocabularies can’t be proof of genetic relationship of languages and some other methods should be used for it, i.e.: analysis of structures. Swadesh method is method of estimation of approximate time of divergence of languages which have been already proved to be relatives. However, Swadesh’s warning has been well forgotten. Also we should keep in mind that even so called basic lexicon is actually culturally determined (Hoijer 1956) and borrowings can be inside it (above considered example of Japanese and Cantonese).
Moreover, we should keep in mind the fact that there are thousands of languages which history is completely unknown and which are described only in their current phase and so there is no ability to distinguish borrowings in their lexicon and so it’s completely impossible to say anything about their genetic relationship basing on methodology of comparison of lexis.
Methodology that ignores structural/grammatical issues allows different scholars to make completely different conclusions about the same language, for instance: Sumerian is thought to be a relative of Kartvelian stock (Nicholas Marr), of Uralic stock (Simo Parpola), of Sino-Tibetan (Jan Braun), of Mon-Khmer (Igor M. Diakonoff) or even of Basque (Aleksi Sahala). Another notable example is Ainu that is attributed to Altaic (James Patrie), to Austronesian (Murayama Shichirō), to Mon-Khmer (Alexander Vovin)6. The most notable fact is that all such attempts coexist and all are considered by public as rather reliable in the same time, obviously it looks much a like a plot for a vaudeville sketch rather than a serious matter of a science.
Different methods can lead to different conclusions but if people use same methodology they supposedly are expected to make same conclusions about the same material, however, we don’t see it; it means only that methodology based on comparison of lexis isn’t relevant for comparative linguistics.
Also a weird issue is that such lexical methodology has never been tested in an appropriate way. Being asked “why you came to the conclusion that it is possible to conclude something about certain languages genetic relationship basing on comparison of lexis only?” megalocomparativists usually answer “morphology doesn’t matter” and don’t explain how they came to such conclusion; they actually look much alike adepts of a religion but not alike scientists since science always supposes experiments and verifications while statements “it is so because it is so” obviously don’t belong to the field of science but actually are statements of a religion.
All facts show us that comparison of lexicon is completely irrelevant methodology in the field of historical comparative studies of languages.
Why we can say that language is first of all grammar, i.e.: system of grammar meanings and their distributions but not a heap of lexemes?
Yet William Jones, founding father of linguistics, pointed on the fact that grammar is much more important than lexis:
The Sanscrit language, whatever be its antiquity, is of a wonderful structure; more perfect than the Greek, more copious than the Latin, and more exquisitely refined than either; yet bearing to both of them a stronger affinity, both in the roots of verbs, and in the forms of grammar, than could possibly have been produced by accident; so strong, indeed, that no philologer could examine them all three without believing them to have sprung from some common source, which perhaps no longer exists. There is a similar reason, though not quite so forcible, for supposing that both the Gothick and the Celtick, though blended with a very different idiom, had the same origin with the Sanscrit; and the old Persian might be added to the same family, if this were the place for discussing any question concerning the antiquities of Persia (Jones 1798: 422 – 423).
Main function of any language is to be mean of communication, but in order to be able to communicate we have to set a system of rubrics/labels/markers first of all, that’s why main function of any language is to rubricate/to structurize reality. Structural level/grammar is the mean that rubricates reality and so it is much more important than lexicon. I suppose we can even say that structure appeared before languages of modern type, i.e.: when ancestors of Homo sapiens developed possibility of free combination of two signals inside one “utterance” it already was primitive form of modern language. Structure is something alike bottle while lexicon is liquid/matter which is inside the bottle; in a bottle can be put wine, water, gasoline or even sand but the bottle always remains bottle.
To those who think that structure is not important I can give the following example taken from Japanese language: Gakusei ha essei wo gugutte purinto shita. “Having googled an essay student printed [it]”. What makes this phrase be a Japanese phrase? “Japanese” words gakusei “student” (a word of Chinese origin), essei “essay” (a word of English origin), purinto “print” or, may be, “Japanese” verb guguru “to google”? One can probably say that this example is very special since it was made without so called “basic lexicon”; however, such words are of everyday use and also, as it has been noted above, it is impossible to distinguish so called “basic lexicon” since all lexis is culturally determined and borrowings can be even inside of so called “basic lexis”. Any language can potentially accept thousands of foreign words and still remains the same language until its structure remains the same.
All the above considered facts mean that comparison of lexis should not be base of genetic classification of languages and any researches about genetic affiliation should be based on comparative analysis of structures/grammar, i.e.: analysis and comparison of grammatical systems of compared languages is completely obligatory procedure to prove/test some hypothesis of genetic affiliation of a language. That’s why in current monograph two powerful typological tools are represented.
2. Prefixation Ability Index (PAI) allows us to see whether two languages can potentially be genetically related
2.1. PAI Method
2.1.1. PAI method background
A. P. Volodin pointed on the fact that all languages can be subdivided into two sets by the parameter of presence/absence of prefixation: one group has prefixation and the other has not (Volodin 1997: 9).
The first set was conventionally named set of “American type” linear model of word form7.
According to Volodin American type linear model of word form is the following:
(p) + (r) + R + (s).
The second one was conventionally named set of “Altaiс type” linear model of word form8.
According to Volodin it is the following:
(r) + R + (s)
(p – prefix, s – suffix, R – main root, r – incorporated root; brackets mean that corresponding element can be absent or can be represented several times inside a particular form).
Volodin supposed that there was a border between two sets and that languages belonging to the same set demonstrate certain structural similarities. Also he supposed that typological similarities could probably tell us something about possible routes of ethnic migrations.
2.1.2. PAI hypothesis development
Having got Volodin’s notion about two types of linear model of word form, I for quite a long time thought that there was a pretty strict water parting between languages that have prefixation and those that have not. For instance, I seriously thought that Japanese had no prefixes and tried to consider all prefixes of Japanese as variations of certain roots, i.e. as components of compounds; until one day I finally realized that so called “variations of roots” actually could never be placed in nuclear position and so they all should be considered as true prefixes, so strict dichotomy was broken and I had to elaborate new theory.
As far as any language actually has some ability to make prefixation so there is no strict border between languages with prefixation and languages without prefixation and we should give up ideas of strict subdivision of all existing languages into two sets that have no intersection.
Hence thereupon, linear model of word forms have the following structures:
(P) + (R) + r + (s) – linear model of word form of American type;
(p) + (r) + r + (S) – linear model of word form of Altaic type.
Capital letters are markers of positions that are used more than positions marked by small letters.
Thereby, there is no principal structural difference between languages of American type and Altaic type, difference is in degree of manifestation of certain parameters and so, in order to our conclusion will not be speculative, we should speak about degree of prefixation producing ability / prefixation ability degree / prefixation ability index, i.e.: of certain measure of prefixation.
I suppose that each language has its own ability to produce prefixation and that this ability doesn’t change seriously during all stages of its history.
Also I suppose that prefixation ability demonstrates itself in any circumstances, i.e.: it is manifested by any means: by means of original morphemes existing in a certain language or by borrowed morphemes.
If a language has certain prefixation ability it is shown anyway. That’s why I don’t make difference between original and borrowed affixes.
Also for current consideration is not principal whether this or that affix is derivative or relative: if we take into account relative affixes only, then, for instance, Japanese is a language without prefixes.
That’s why we should define prefixes not by its derivative or by its relative role but by its positions inside word form, prefix is any morpheme that meets the following requirements:
1) it can be placed only left from nuclear position;
2) it never can be placed upon nuclear position;
3) between this morpheme and nuclear can’t be placed any meaningful morpheme with its clitics (i.e.: between nuclear root and prefix can’t be placed a meaningful morpheme with its auxiliary morphemes).
I am specially to note that there are no so called semi-prefixes. If a morpheme can be placed in nuclear position it is meaningful morpheme and any combinations with it should be considered as compounds.
Thus can be resumed the following:
1) Each language has its own ability to produce prefixation and this ability doesn’t change seriously during all stages of its history.
2) Prefixation ability is manifested by any means: by means of original morphemes existing in a certain language or by borrowed morphemes. That’s why the method doesn’t suppose distinction between original and loaned affixes.
3) Genetically related languages are supposed to have rather close values of Prefixation Ability Index.
2.1.3. PAI calculation algorithm
How Prefixation Ability Index (here and further in this text abbreviation PAI is used) can be measured?
Value of PAI is portion of prefixes among affixes of a language.
Hence, in order to estimate portion/percentage of prefixes of a certain language we should do the following:
1) Count total number of prefixes;
2) Count total number of affixes;
3) Calculate the ratio of total number of prefixes to the total number of affixes.
Why is it important to count total number of prefixes and then calculate the ratio to the total number of affixes but not to estimate PAI by frequency of prefix forms in a random text?
A certain language can have quite high value of PAI but in a particular text word forms with prefixes can be of low frequency. Our task is to estimate portion of prefixes in grammar but not portion of prefix forms in a random text. Prefixes/World index estimated by Greenberg was exactly that estimation of prefix forms frequency in a text (Greenberg 1960).
Of course, that index also can give some general notion of prefixation ability of a language, though it is extremely rough and inaccurate since in a randomly chosen text can be very little amount of words with prefixes: the longer text is the more precision is the conclusion but anyway error of such estimation still remains very high; while when we count all exiting affixes of a certain language potential error is extremely low and even if we occasionally forget some affixes it doesn’t influence seriously on our results.
Moreover I am to note that despite Greenberg made great work on the field of typology he didn’t actually use those results in his research; he was an adept of megalocomparison and made his conclusions basing on “mass comparison” of lexis but not on structural correlations; his interest in typology was a “glass beads game” and was separated from his actual field of studies.
To those who think, that it’s impossible to estimate number of morphemes since living language always changes, I am to tell that living language doesn’t invent new morphemes every day, especially auxiliary morphemes. The fact that learning a language we can use descriptions of its grammar written some decades ago is the best proof that grammar is a very conservative level of any language.
Hence, we can estimate total number of affixes of a living language as far as we can get its description where all stable forms are represented. And there is no need to care of what can be in a certain language in future, i.e.: we consider current stage of living language and don’t care of possible future stages since they simply don’t exist yet.
As for possibility of count, I am to tell that even set of words is countable set while set of morphemes and especially auxiliary morphemes is not just countable set but also is finite set.
2.1.4. PAI method testing: from a hypothesis toward a theory
In order to test PAI hypothesis I paid attention to some languages of firmly assembled stocks: Austronesian, Indo-European and Afroasiatic.
2.1.4.1. PAI of languages of Austronesian stock
Polynesian group
Eastern Polynesian Subgroup
Hawaiian 0.82 (calculated after Krupa 1979)
Maori 0.88 (calculated fater Krupa 1967)
Tahitian 0.66 (calculated after Arakin 1981)
Samoan-Tokelauan subgroup
Samoan 0.5 (calculated after Arakin 1973)
Tongic subgroup
Niuean 0.8 (calculated after Polinskaya 1995)
Tongan 0.78 (calculated after Fell 1918)
Philippine group
South Mindanao subgroup
T’boli 0.72 (calculated after Porter 1977)
Northern Luzon subgroup
Pangasinan 0.6 (calculated after Rayner 1923)
Malayo-Sumbawan group
Malay subgroup
Indonesian 0.53 (calculated after Ogloblin 2008)
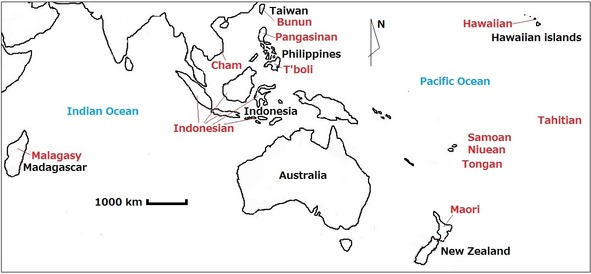
Pic. 2. Map representing location of Austronesian languages mentioned in current chapter: languages are marked by red, place names are maked by black.
Chamic subgroup
Cham 0.6 (calculated after Aymonier 1889; Alieva, Bùi 1999)
Formosan group
Bunun 0.8 (calculated after De Busser 2009)
Eastern Barito group
Malagasy 0.74 (calculated after Arakin 1963)
2.1.4.2. PAI of languages Indo-European stock
German group
Dutch 0.49 (calculated after Donaldson 1997)
German 0.51 (calculated after Donaldson 2007)
English 0.61 (calculated after Barhkhudarov et al. 2000)
Icelandic 0.63 (calculated after Einarsson 1949)
Slavonic group
Czech 0.52 (calculated after Harkins 1952)
Polish 0.57 (calculated after Swan 2002)
Celtic group
Irish 0.67 (McGonage 2005)
Welsh 0.35 (calculated after King 2015)
Roman group
Latin 0.26 (calculated after Bennet 1913)
Spanish 0.34 (calculated after Kattán-Ibarra, Pountain 2003)
2.1.4.3. PAI of languages of Afroasiatic stock
Semitic group
Central Semitic subgroup
Arabic (Classical) 0.26 (calculated after Yushmanov 2008)
Phoenician 0.26 (calculated after Shiftman 2010)
Eastern Semitic subgroup
Akkadian (Old Babylonian dialect) 0.2 (calculated after Kaplan 2006)
Egypt group
Coptic (Sahidic dialect) 0.87 (calculated after Elanskaya 2010)
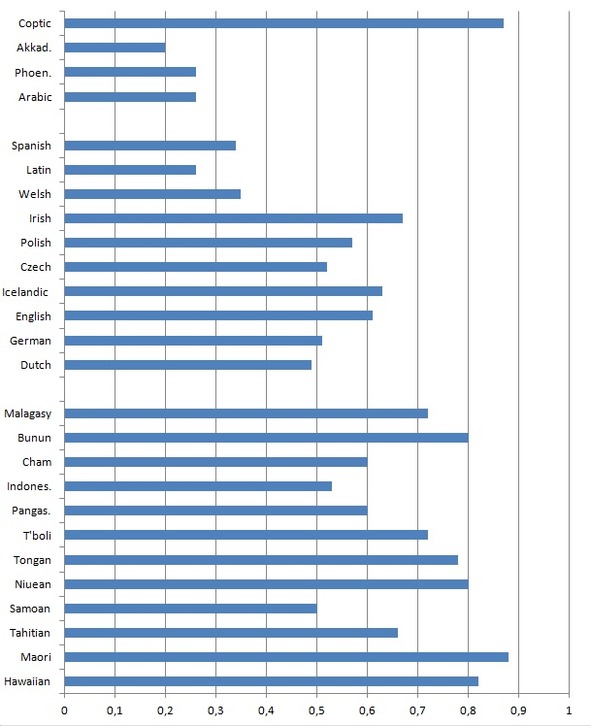
Pic. 3. Diagram representing PAI values of some firmly assembled stocks
2.1.5. PAI of a group/stock
PAI of a group or a stock can be calculated as arithmetical mean and it’s quite precise for rough estimation.
One can probably say that just arithmetic mean is quite rough estimation and in order to estimate PAI in a more precise way it would be better to take values of PAI of particular languages with coefficients that show proximity of particular languages to the ancestor language of the stock. Coefficient of proximity is degree of correlation of grammar systems.
Let’s test this hypothesis and see whether it so.
For instance, in the case of Austronesian it would be somehow like the following:
Malagasy^PAN9 ≈ 0.5;
Bunun^PAN ≈ 0.8;
Philippine group^PAN ≈ 0.7;
Indonesian^PAN ≈ 0.6;
Cham^PAN ≈ 0.4;
Polynesian languages^PAN ≈ 0.5.
Indexes show degree of proximity of languages (grammatical systems). In current case these indexes are not results of any calculations but just approximate speculative estimation of degrees of proximity of modern Austronesian languages with Proto-Austronesian; it is supposed that Formosan languages and so called languages of Philippines type are the closest relatives of PAN among modern Austronesian.