


Полная версия
ChatGPT: Что я такое? Первая книга об ИИ, написанная самим ИИ!
3. Предварительная обработка данных: Этот этап включает в себя очистку данных (удаление ошибок, сильных отклонений, пропущенных значений), преобразование данных (например, преобразование текста в числовые значения или приведение разнородных данных к единому формату) и нормализацию данных (например, масштабирование значений на определенный диапазон).
4. Выделение признаков: Признаки – это характеристики или атрибуты, которые машина использует для обучения. Например, если вы создаете модель для классификации изображений кошек и собак, признаками могут быть размеры животных, цвета, текстуры и формы, присутствующие на изображении. Этап выделения признаков включает в себя выбор и создание эффективных признаков, которые помогут модели делать более точные прогнозы.
5. Выбор модели: В зависимости от типа проблемы и задачи (регрессия, классификация, кластеризация и т.д.) и специфики данных, вы выбираете тип (вид) Машинного обучения (Supervised, Unsupervised, Semi-supervised, Self-supervised или Reinforcement Learning) и конкретную подходящую Модель машинного обучения этого вида.
6. Обучение модели: На этом этапе алгоритм машинного обучения сам «обучает» модель, используя ваши данные и целевые значения. Это происходит путем настройки параметров модели таким образом, чтобы минимизировать ошибку между прогнозируемыми моделью результатами и реальными значениями результатов (взятыми из обучающих примеров).
7. Оценка модели: После обучения модели вам нужно оценить ее качество и производительность. Это обычно делается с помощью сравнения ответов модели с отложенным набором данных (тестовым набором), который не использовался при обучении. Метрики оценки могут включать точность, полноту и другие показатели работы модели. Важно получить модель, которая не будет переобученной, но и не будет недообученной – чтобы получать от нее потом хорошие результаты предсказаний
8. Тонкая настройка и оптимизация: После первоначального обучения и оценки модели вы можете оптимизировать и настраивать свою модель, изменяя параметры и используя различные техники, такие как кросс-валидация и регуляризация.
9. Развертывание модели (Деплой): После того, как модель была обучена, оценена и оптимизирована, она может быть «развернута» (на компьютерных системах и вычислительных мощностях) и использована для предсказаний на новых данных.
10. Процесс работы модели (Инференс): Обычно этот термин используют при работе с нейронными сетями. Инференсом называется непрерывная работа какой-либо нейронной сети на конечном устройстве. То есть, это процесс исполнения сети, когда она уже развернута и готова к проведению полезной работы. Для инференса используются процессоры общего назначения (CPU), графические процессоры (GPU) или специализированные процессоры для Машинного обучения и нейросетей (TPU).
Все эти шаги могут потребовать различных навыков и инструментов: знания основ математики, статистики, программирования, поддержки работы компьютерных систем, обработки и анализа данных и, конечно же, знания самого машинного обучения и предметной области, в которой вы решаете задачу.
4. Расскажи про основные параметры, определяющие качество и эффективность моделей Машинного Обучения?
Машинное обучение – это процесс, в ходе которого компьютерные модели «учатся» на данных и делают свои прогнозы или решения на основе этого обучения.
При создании моделей машинного обучения одним из самых важных этапов является оценка их работы. Без правильной оценки результатов есть риск начать использовать модель, которая может давать неверные прогнозы, принимать неправильные решения, пропускать важные случаи (в задачах выявления нужных объектов).
Чтобы узнать, насколько хорошо модель справляется со своей задачей – используют метрики качества моделей машинного обучения. Оценка моделей не только позволяет понять их эффективность, но и выявить возможные недостатки, которые стоит устранить.
Вот примеры метрик качества для моделей в машинном обучении:
Средняя абсолютная ошибка – Для задач, где модель предсказывает численные значения, эта метрика показывает, насколько в среднем прогнозы модели отличаются от истинных значений. Например, если модели нужно предсказывать температуру воздуха в течение какого времени, эта метрика покажет на сколько в среднем отклоняются предсказания модели (неважно – в большую или в меньшую стороны) от реальной температуры воздуха. Чем меньше отклонения – тем лучше модель.
Точность модели – Для задач, где нужно выбрать определенный тип объектов в общей выборке и не ошибаться с типом этих объектов (но можно что-то и пропустить), эта мера показывает, какой процент прогнозов модели был правильным. Например, нужно определить и выбрать клиентов, которые с большей вероятностью купят определенный товар. Так, если модель правильно предсказала 85 из 100 случаев, то её точность составляет 85%.
Полнота модели – Когда модели нужно обнаружить определенный тип объектов в общей выборке и важно не пропустить объекты этого типа (но при этом, допускается ошибаться и обнаружить лишние объекты, которые на самом деле не относятся к искомому типу). Эта метрика показывает, сколько случаев из выборки модель учла. Например, когда модель применяется в медицине и ей нельзя пропустить больных с определенным диагнозом (так как в этом случае человек не узнает о своем диагнозе и не получит вовремя соответствующего лечения), но вполне можно предположить наличие болезни у здорового человека (так как потом его перепроверят и снимут ошибочно поставленный диагноз).
Перплексия (Perplexity) – это популярная метрика для оценки качества языковых моделей в задачах прогнозирования следующего слова. Перплексия интерпретируется как среднее число выборов, которые модель рассматривает при предсказании следующего слова. Например, перплексия, равная 10, означает, что при прогнозировании следующего слова модель в среднем «колеблется» между 10 словами. Меньшее значение перплексии указывает на лучшую модель. Модель с перплексией 1 была бы идеальной и всегда бы правильно предсказывала (знала вполне определенно) следующее слово.
Кроме этого, один из основных вызовов в машинном обучении – избежать недообучения и переобучения моделей.
Недообучение модели (Underfitting): Это происходит, когда модель слишком проста для сложности данных, и не может выучить закономерности в них. В результате такая модель плохо справляется как с обучающими, так и с тестовыми данными.
Переобучение модели (Overfitting): Здесь проблема противоположная. Модель становится слишком «узкоспециализированной» под обучающие данные и начинает «запоминать» их, но уже не может «понять» более общую закономерность и предсказать то, чего не было в обучающих данных. Поэтому переобученная модель может идеально работать на обучающем наборе данных, но плохо на новых-тестовых данных.
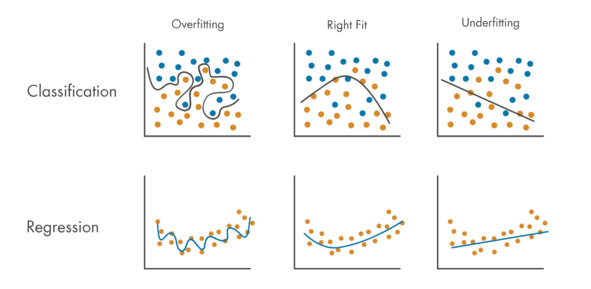
Оценка качества моделей машинного обучения – ключевой этап в процессе их создания. Выбор правильной метрики поможет понять, насколько получена правильная и эффективна модель, и, при необходимости, внести коррективы в её обучение или заменить модель.
5. Расскажи, какие вообще есть Типы (виды) Машинного Обучения?
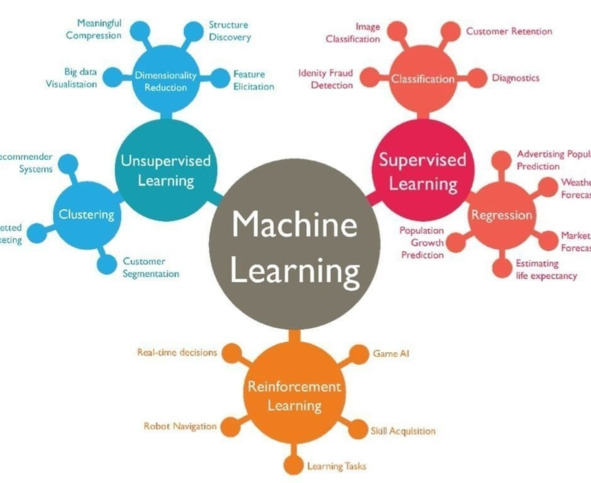
Изначально в Машинном Обучении выделяли три основных типа: Обучение с учителем (Supervised Learning), Обучение без учителя (Unsupervised Learning) и Обучение с подкреплением (Reinforcement Learning). Со временем еще 2 типа получили развитие: Обучение с частичным привлечением учителя (Semi-supervised Learning) и Самостоятельное/автоматическое обучение (Self-supervised Learning).
Рассмотрим все эти Виды Машинного Обучения:
1. Обучение с учителем (Supervised Learning)
Модели на вход даются примеры размеченных данных, где каждый пример уже помечен правильным ответом. Задача модели – научиться самой также предсказывать эти ответы для данных. Например, если мы обучаем модель распознавать кошек и собак на фотографиях, то сначала мы показываем ей множество изображений кошек и собак, где каждое изображение уже с соответствующей меткой («кошка» это или «собака»). Или, если модель учится отличать спам-письма от не спама, то на входе ей дается множество писем с имеющимися метками – спам это или не спам. Модель пытается предсказать ответы для примеров с уже известными метками и каждую итерацию сравнивает свои ответы с существующими ответами и пытается улучшить себя, чтобы на следующей итерации предсказывать ответы еще точнее. Итоговая задача модели – найти зависимость между данными и метками классов и использовать эту зависимость для дальнейшего самостоятельного предсказания классов для новых (неразмеченных) входных данных.
2. Обучение без учителя (Unsupervised Learning)
Здесь модели обучаются на наборе данных, в котором известны только неразмеченные входные данные, и нет конкретных выходных данных (меток классов и т.п.). Задача модели состоит в том, чтобы самостоятельно найти структуру или взаимосвязи в данных. Примеры включают кластеризацию (например, сегментацию клиентов для маркетинга по разным подгруппам или определение количества разных видов подгрупп в очень большой группе людей) и понижение размерности (например, упрощение данных для их понятного представления и визуализации).
3. Обучение с подкреплением (Reinforcement Learning)
В этом случае модель (часто в этом случае ее называют ИИ-агентом) обучается сама, взаимодействуя со своей «средой обитания». Модель выполняет различные действия и в результате этих действий получает от среды отклик – награды («подкрепление») за правильные (полезные или эффективные) действия или штрафы за неправильные (вредные или не эффективные) действия. Модель стремится максимизировать сумму получаемых наград – то есть выполнять действия (или последовательности действий), которые дают как можно лучший результат. Примеры включают управление роботами (которые получают отклик от среды – плохо или хорошо они выполняют свои задачи), игровые агенты (получающие отклик от игровой среды – в случае выигрыша или проигрыша), системы рекомендаций (где отклик – это качество удовлетворения пользователей этими рекомендациями).
4. Обучение с частичным привлечением учителя (Semi-supervised Learning)
Машинное обучение с частичным привлечением учителя (также известное как обучение с полуконтролем или гибридное обучение), находится между Обучением с учителем (Supervised Learning) и Обучением без учителя (Unsupervised Learning). В этом случае модели подается комбинация помеченных и неразмеченных данных. Неразмеченные данные очень дешевы в отличие от размеченных данных (которые часто приходится помечать вручную). Процедура заключается в том, что алгоритм сначала использует все данные и алгоритмы обучения без учителя для кластеризации данных, а затем использует алгоритм обучения с учителем для определения меток для каждого класса. И если неразмеченные данные оказываются близки к одному из классов размеченных —то они с большей вероятностью принадлежат тому же классу.
5. Самостоятельное/автоматическое обучение (Self-supervised Learning)
Это относительно новый подход, где модель обучается на данных, генерируя сама себе задачи и ответы (чаще всего через маскировку части данных и попытки их угадывания). Задача модели – понять и усвоить скрытую структуру, которая есть в этих данных. Например, если данные – это связный текст, то модель может маскировать и пытаться предсказать следующее слово в предложении. Или для изображений модель может пытаться маскировать и восстанавливать части изображения. Или пытать предсказать цвет или другие параметры изображения. Таким образом, она учится на большом количестве данных (текстов, изображений, видео), без необходимости наличия внешних меток или участия человека. В результате модель усваивает структуру и внутренние связи в этих данных (которые могут быть даже неизвестны человеку). И когда эта структура усвоена – то модель можно дообучить для решения какой-нибудь специальной практической задачи (для решения которой нужно понимать эту структуру в данных). Например, можно дообучить модель для автозаполнения или перевода текстов или сделать модель для улучшения, окраски и восстановления изображений и т. д. Бурный рост приложений в области современного Генеративного ИИ (Generative AI) – больше всего обязан именно этому типу Машинного Обучения.
Каждый из этих методов обладает своими уникальными преимуществами и ограничениями и выбор метода зависит от конкретной задачи и доступности данных.
6. Какие основные виды задач решает машинное обучение? Дай определение сути и характеристику для каждого вида задач.
Машинное обучение используется для решения различных видов задач.
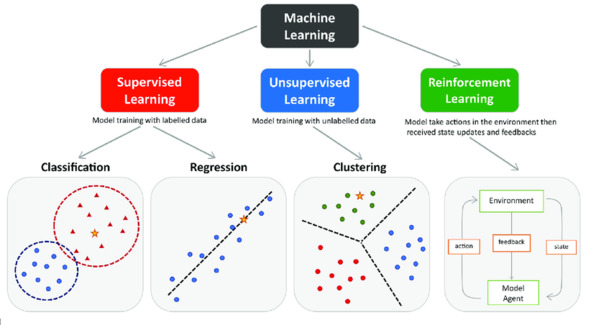
Вот основные виды задач, которые есть в современном машинном обучении:
1. Задачи классификации: В задачах классификации модель предсказывает дискретную метку или категорию. Например, задача определения, является ли электронное письмо спамом или нет, является задачей классификации. Здесь мы предсказываем дискретную переменную (спам или не спам).
2. Задачи кластеризации: Это тип задач, где модель группирует данные на основе их сходства, и эти группы называются кластерами. Этот процесс происходит без каких-либо предварительных знаний о данных, и в этом смысле он относится к обучению без учителя. Например, кластеризация может быть использована для сегментации клиентов на основе их покупательского поведения.
3. Задачи регрессии: Регрессия – это тип задачи, где модель предсказывает непрерывное значение. Например, предсказание цены на дом на основе различных характеристик, таких как площадь, количество спален, год постройки и т.д., является задачей регрессии. В этом случае, мы пытаемся предсказать непрерывную переменную (цена на дом) на основе других входных данных об этом доме.
4. Задачи Обучения с подкреплением (Reinforcement Learning): Сюда можно отнести примеры с управлением роботами (которые получают отклик от среды – плохо или хорошо они выполняют свои задачи), развитием навыков игровых агентов (получающие отклик от игровой среды – в случае выигрыша или проигрыша), систем рекомендаций (где отклик – это качество удовлетворения пользователей этими рекомендациями).
5. Задачи Генеративного ИИ: В отличие от задач классического машинного обучения (классификации, кластеризации и регрессии), Генеративные модели обучаются на данных и могут генерировать новые, ранее не встречавшиеся образцы данных. Данные могут представлять собой текст, изображения, речь и т. д. Задачи, которые могут выполнять такие модели, включают создание разнообразного контента: текстов, изображений, звука и музыки и т. д. Кроме этого, модели генеративного ИИ могут выполнять широкий класс задач, связанных с дальнейшей обработкой и преобразованием этого контента: ответы на вопросы, анализ настроений и тональности в текстах или видео; извлечение искомой информации из текста изображений, видео или аудио; маркировку изображений и распознавание объектов.
Конец ознакомительного фрагмента.
Текст предоставлен ООО «Литрес».
Прочитайте эту книгу целиком, купив полную легальную версию на Литрес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.