


Полная версия
КонтрПлагиат методом перефразирования и рерайта для антиплагиат ВУЗ. Как повысить оригинальность текста за несколько часов и пройти проверку с первого раза
Из того, что на слуху известно, что «температура» творит чудеса, есть еще ряд параметров, но GPT про них не рассказывает, а информация в интернет крайне неполная. Ниже мы приводим параметры, которые вы можете ввести в свою инструкцию промпт и получить выдающиеся результаты генерации или перефразирования.
Ниже обобщены параметры, которые могут использоваться для составления инструкций-промптов.
Adaptive Beam Search
Параметр «adaptive_beam_search» используется в алгоритмах поиска лучей (beam search) для динамического адаптирования процесса генерации текста. В отличие от статического beam search, который использует фиксированное количество лучей, адаптивный beam search может изменять количество лучей на основе качества текущего генерационного состояния.
Этот параметр позволяет алгоритму более гибко управлять поиском, улучшая как разнообразие, так и когерентность текста. Он адаптируется к процессу генерации, что помогает избежать избыточного повторения и поддерживать высокое качество.
Значение параметра может быть булевым (True/False) или числовым, указывающим степень адаптации (например, процент от общего количества лучей). Например, «adaptive_beam_search=True» включает адаптивный поиск лучей.
Bad Words
Параметр «bad_words» представляет собой список нежелательных слов или фраз, которые должны быть исключены из генерируемого текста. Он используется для фильтрации и предотвращения появления неуместных или неприемлемых выражений в результатах генерации.
Этот параметр помогает контролировать содержание и тональность текста, предотвращая включение слов или фраз, которые могут быть оскорбительными или неуместными.
Значения представляют собой список строк (например, « [«плохое_слово1», «нежелательное_слово2»]»). Параметр может быть пустым, если нет необходимости в фильтрации.
Coherence Threshold
Параметр «coherence_threshold» устанавливает порог для оценки когерентности текста, который генерируется моделью. Он помогает определить, насколько логично и последовательно текст соответствует контексту.
Позволяет настроить уровень когерентности текста, обеспечивая, чтобы выходные данные не содержали нелогичных или несогласованных частей. Полезен для поддержания высокого качества и понимания текста.
Значение может быть числовым, например, от 0 до 1, где 1 указывает на высокий уровень когерентности. Например, «coherence_threshold=0.8» означает, что текст должен соответствовать когерентности на уровне 80%.
Cohesion
Параметр «cohesion» отвечает за поддержание логической связности и плавности текста. Он управляет тем, насколько хорошо предложения и идеи соединены друг с другом в рамках текста.
Помогает обеспечить, чтобы текст не только был грамматически правильным, но и имел внутреннюю согласованность, что важно для естественного и понятного изложения информации.
Значения могут варьироваться от числовых (например, от 0 до 1) до категориальных (например, «низкая», «средняя», «высокая»). Например, «cohesion=0.7» может означать средний уровень связности.
Context Window
Параметр «context_window» определяет размер контекстного окна, который модель использует для анализа текста. Это количество слов или предложений, которые модель учитывает для генерации следующего слова или предложения.
Более широкий контекст позволяет модели захватывать более сложные зависимости и связи, что улучшает качество генерации текста, но требует больше вычислительных ресурсов.
Значение может быть числовым, указывающим количество слов или предложений в контексте (например, «context_window=50»). Большие значения дают модели больше информации, но могут замедлить процесс генерации.
Contextual Embedding Size
Параметр «contextual_embedding_size» определяет размер векторных представлений (эмбеддингов) контекста, который модель использует для анализа и генерации текста. Эмбеддинги представляют слова или фразы в виде многомерных векторов, которые учитывают контекстуальные связи.
Больший размер эмбеддингов позволяет модели захватывать более сложные и тонкие смысловые отношения между словами, что может улучшить качество генерации текста и понимания контекста. Однако, увеличение размера требует больше вычислительных ресурсов и памяти.
Значение может быть числовым, определяющим размер векторного пространства, например, «contextual_embedding_size=256» или «contextual_embedding_size=512». Размер обычно выбирается в диапазоне от 100 до 1024, в зависимости от доступных вычислительных ресурсов и требуемой точности.
Diversity Penalty
Параметр «diversity_penalty» применяется для управления разнообразием генерируемого текста. Он штрафует модель за избыточное использование одинаковых слов или фраз, способствуя созданию более разнообразных выходных данных.
Помогает предотвратить избыточное повторение слов и фраз, что делает текст более интересным и менее однообразным. Это важно для создания содержательных и разнообразных результатов.
Значение может быть числовым, где более высокие значения (например, «diversity_penalty=1.5») увеличивают штраф за повторение, а более низкие значения (например, «diversity_penalty=0.5») уменьшают его. Может также быть в диапазоне от 0 до 2.
Diversity Temperature
Параметр «diversity_temperature» регулирует уровень разнообразия в тексте, изменяя распределение вероятностей предсказанных слов. Он работает в связке с температурой для создания текстов с заданным уровнем креативности и непредсказуемости.
Более высокая температура (например, «diversity_temperature=1.2») делает распределение более равномерным, увеличивая разнообразие и креативность текста. Низкая температура (например, «diversity_temperature=0.7») делает распределение более сосредоточенным, снижая разнообразие.
Значение может быть числовым, например, от 0.5 до 2.0. «diversity_temperature=1.0» является стандартным значением, при котором модель генерирует текст с умеренным уровнем разнообразия.
Early Stopping
Параметр «early_stopping» управляет тем, когда процесс генерации текста должен завершиться, если модель достигает определенного состояния. Это предотвращает генерацию избыточно длинных текстов и помогает контролировать длину выхода.
Позволяет модели прекратить генерацию, когда достигнут определенный критерий, такой как достижение заданной длины текста или начало повторения. Это улучшает качество и релевантность текста, предотвращая его излишнюю длину.
Значение может быть булевым («True»/«False»), где «True» включает раннюю остановку, а «False» отключает. Также могут быть установлены дополнительные параметры, такие как количество токенов до остановки.
Encoder No Repeat Ngram Size
Параметр «encoder_no_repeat_ngram_size» применяется для предотвращения повторения определенных n-грамм в тексте, создаваемом моделями с энкодером-декодером. Это помогает избежать избыточного повторения последовательностей слов.
Устанавливает размер n-грамм, повторение которых в тексте будет запрещено. Это важно для поддержания разнообразия и избегания избыточного повторения в тексте, особенно при длительных генерациях.
Значение может быть числовым, указывающим размер n-грамм, например, «encoder_no_repeat_ngram_size=2» (запрещает повторение биграмм). Значения варьируются от 1 (без ограничения) до более высоких значений, таких как 3 или 4, в зависимости от требуемого уровня контроля над повторением.
Frequency Penalty
Параметр «frequency_penalty» регулирует штраф за частое использование одних и тех же слов в генерируемом тексте. Этот параметр помогает контролировать избыточное повторение слов и фраз, способствуя созданию более разнообразного текста.
При высоком значении этого параметра модель менее склонна к повторению часто встречающихся слов. Это способствует увеличению разнообразия и улучшению качества текста, особенно в длительных текстах.
Значение может быть числовым, в диапазоне от 0 до 2. Например, «frequency_penalty=0.5» обеспечивает умеренное снижение частоты повторяющихся слов, а «frequency_penalty=1.5» значительно увеличивает штраф.
Length Penalty
Параметр «length_penalty» контролирует, как длина генерируемого текста влияет на его вероятность. Этот параметр используется для управления длиной текста, обеспечивая баланс между слишком короткими и слишком длинными результатами.
Значение этого параметра позволяет модели избегать генерации слишком длинных или слишком коротких текстов. Помогает поддерживать оптимальную длину текста, что важно для соблюдения заданных требований.
Значение может быть числовым. Например, «length_penalty=1.0» означает нейтральное отношение к длине текста, «length_penalty> 1.0» стимулирует генерацию более длинных текстов, а «length_penalty <1.0» – более коротких.
Length Penalty Weight
Параметр «length_penalty_weight» управляет весом, который применяется к штрафу за длину текста. Этот параметр позволяет более точно настраивать влияние длины текста на вероятность его выбора.
Позволяет различать степень влияния длины текста на его вероятность. Чем выше значение, тем больше модель будет штрафовать за генерацию текста с несоответствующей длиной.
Значение может быть числовым, например, от 0.1 до 2.0. «length_penalty_weight=1.0» является стандартным значением, обеспечивающим нейтральное влияние длины, а значения выше 1.0 увеличивают штраф за превышение длины.
Max Length
Параметр «max_length» устанавливает максимальную длину текста, который может быть сгенерирован моделью. Этот параметр помогает ограничить размер выходных данных, чтобы текст не становился слишком длинным.
Обеспечивает контроль над длиной текста, предотвращая его чрезмерное удлинение. Полезен для соблюдения требований к длине текста или ограничений по памяти.
Значение представляет собой целое число, указывающее максимальное количество токенов в тексте. Например, «max_length=100» ограничивает текст 100 токенами.
Max Tokens
Параметр «max_tokens» определяет максимальное количество токенов, которые могут быть сгенерированы моделью. Это эквивалентно максимальной длине текста и контролирует объем выходных данных.
Позволяет ограничить длину текста, предотвращая его избыточное удлинение и управление ресурсами при генерации. Это важно для поддержания эффективности и качества.
Значение может быть числовым, указывающим количество токенов, например, «max_tokens=50» или «max_tokens=200», в зависимости от требований к длине текста.
Min Length
Параметр «min_length» устанавливает минимальную длину текста, который должен быть сгенерирован моделью. Этот параметр предотвращает генерацию слишком коротких текстов, обеспечивая минимально приемлемый объем информации.
Гарантирует, что текст не будет слишком кратким и обеспечит необходимую глубину или содержание. Полезен для генерации более содержательных и полноценных текстов.
Значение представляет собой целое число, указывающее минимальное количество токенов. Например, «min_length=20» гарантирует, что текст будет содержать не менее 20 токенов.
N-Gram Repetition Penalty
Параметр «n_gram_repetition_penalty» регулирует штраф за повторение определенных n-грамм в тексте, который генерируется моделью. Это помогает избежать избыточного повторения последовательностей слов, улучшая качество текста.
Этот параметр предназначен для контроля повторяемости фраз и словосочетаний. При высоком значении модель получает больший штраф за повторение одной и той же n-граммы, что способствует созданию более разнообразного текста.
Значение может быть числовым, например, от 0 до 2. Например, «n_gram_repetition_penalty=1.5» увеличивает штраф за повторение n-грамм, а «n_gram_repetition_penalty=0.8» снижает его. Значение 1.0 представляет стандартный уровень штрафа.
No Repeat Ngram Size
Параметр «no_repeat_ngram_size» устанавливает размер n-грамм, повторение которых в тексте запрещено. Этот параметр предотвращает генерацию текста, содержащего повторяющиеся последовательности слов.
Полезен для контроля за тем, чтобы текст не содержал избыточных повторений определенных фраз или словосочетаний, что делает текст более разнообразным и естественным.
Значение может быть целым числом, определяющим размер n-грамм. Например, «no_repeat_ngram_size=2» предотвращает повторение биграмм, а «no_repeat_ngram_size=3» – триграмм. Значение выбирается в зависимости от желаемого уровня разнообразия.
Num Beam Groups
Параметр «num_beam_groups» управляет количеством групп лучей (beam groups) в алгоритме поиска лучей (beam search). Это позволяет создавать несколько групп лучей, каждая из которых исследует различные пути генерации текста.
Позволяет улучшить разнообразие и качество текста, обеспечивая многогранный поиск и избегая избыточного сосредоточения на одном пути. Это способствует созданию более креативных и разнообразных текстов.
Значение может быть числовым, указывающим количество групп, например, «num_beam_groups=5». При значении 1 модель выполняет стандартный beam search, а значения выше 1 увеличивают разнообразие путем использования нескольких групп.
Num Beams
Параметр «num_beams» определяет количество лучей (beams) в алгоритме поиска лучей (beam search). Это влияет на качество и разнообразие текста, который генерируется моделью.
Большое количество лучей позволяет модели исследовать больше возможных последовательностей и выбрать наиболее вероятную, улучшая качество текста. Однако это также увеличивает вычислительные затраты.
Значение может быть числовым, например, «num_beams=5», что указывает на использование пяти лучей. Значения могут варьироваться от 1 (жадный поиск) до 10 или более, в зависимости от требуемого баланса между качеством и вычислительными ресурсами.
Presence Penalty
Параметр «presence_penalty» управляет штрафом за появление определенных слов или фраз в тексте. Он применяется для уменьшения частоты использования слов, которые уже появились в тексте.
Помогает предотвратить повторение и поддерживает разнообразие текста, обеспечивая более естественное и разнообразное изложение. Это важно для создания текстов без ненужных повторений.
Значение может быть числовым, например, от 0 до 2. Например, «presence_penalty=0.5» применяет умеренный штраф за повторение слов, а «presence_penalty=1.5» увеличивает штраф, уменьшая вероятность повторений.
Repetition Penalty
Параметр «repetition_penalty» используется для снижения вероятности повторения одинаковых слов или фраз в генерируемом тексте. Он применяется для повышения разнообразия и предотвращения избыточного повторения в результате работы модели.
Этот параметр настраивает степень наказания за повторение слов, что помогает избежать монотонности и однообразия в тексте. Чем выше значение, тем сильнее модель штрафует за повторения, что способствует более оригинальному контенту.
Значение может быть числовым, например, от 1.0 до 2.0. Значение «repetition_penalty=1.0» соответствует нейтральному штрафу, «repetition_penalty=1.5» увеличивает штраф за повторения, а значения выше 1.5 предоставляют значительный штраф.
Repetition Penalty Weight
Параметр «repetition_penalty_weight» регулирует степень штрафа за повторение слов или фраз в генерируемом тексте. Он позволяет более гибко настраивать, как сильно модель должна избегать повторений.
Позволяет управлять весом, который применяется к штрафу за повторение, чтобы добиться желаемого уровня разнообразия. Это помогает лучше контролировать качество и креативность текста, особенно в длинных генерациях.
Значение может быть числовым, например, от 0.1 до 2.0. Значение «repetition_penalty_weight=1.0» является стандартным, а значения выше 1.0 увеличивают штраф, в то время как значения ниже 1.0 уменьшают его.
Stop Sequences
Параметр «stop_sequences» определяет последовательности слов, при обнаружении которых генерация текста должна быть остановлена. Это позволяет предотвратить продолжение текста за пределы заданных границ или контекста.
Используется для контроля завершения текста и предотвращения появления нежелательных окончаний. Полезен для создания текстов, которые должны соответствовать определённым критериям или не выходить за рамки заданной темы.
Значение представляет собой список строк, например, «stop_sequences= [„Конец“, „Заключение“]», при обнаружении которых модель завершит генерацию. Могут быть указаны различные последовательности, в зависимости от требований к окончанию текста.
Temperature
Параметр «temperature» управляет степенью случайности в выборе следующего слова при генерации текста. Он изменяет распределение вероятностей, делая генерацию более креативной или более предсказуемой.
Высокие значения температуры (например, «temperature=1.2») делают распределение более равномерным, что увеличивает разнообразие и креативность текста. Низкие значения (например, «temperature=0.7») делают модель более детерминированной и менее разнообразной.
Значение может быть числовым, например, от 0.1 до 2.0. Значение «temperature=1.0» представляет стандартный уровень, а значения выше 1.0 повышают креативность, в то время как ниже 1.0 уменьшают её.
Temperature Decay
Параметр «temperature_decay» управляет изменением температуры в процессе генерации текста. Он позволяет динамически изменять уровень случайности, начиная с более высокого значения и уменьшая его по мере генерации.
Позволяет модели адаптироваться по мере генерации текста, обеспечивая высокий уровень креативности в начале и более предсказуемое завершение. Это помогает поддерживать баланс между разнообразием и когерентностью.
Значение может быть числовым, определяющим, как быстро температура уменьшается, например, «temperature_decay=0.9», что означает постепенное снижение температуры. Значения могут варьироваться от 0.1 до 1.0, в зависимости от желаемой динамики.
Top-K
Параметр «top_k» контролирует выбор следующего слова из фиксированного количества наиболее вероятных вариантов. Это метод ограничивает выбор слов до наиболее вероятных, что помогает улучшить качество генерации текста и избежать непредсказуемых результатов.
Параметр «top_k» задает, сколько лучших вариантов слов модель будет рассматривать при каждом шаге генерации. Это ограничивает выбор и помогает предотвратить появление низкокачественных слов или фраз.
Значение «top_k» является целым числом, определяющим количество слов в рассмотрении. Например, «top_k=50» означает, что будут рассматриваться 50 наиболее вероятных слов. Значения могут варьироваться от 1 (жадный поиск) до 100 или более, в зависимости от желаемого уровня разнообразия и качества.
Top-K Decay
Параметр «top_k_decay» управляет изменением значения «top_k» в процессе генерации текста. Этот параметр позволяет динамически изменять количество вариантов слов, которые рассматриваются на каждом шаге генерации.
Использование «top_k_decay» позволяет постепенно уменьшать количество рассматриваемых вариантов, что может улучшить стабильность и когерентность текста по мере его генерации. Это помогает достичь лучшего баланса между креативностью и точностью.
Значение «top_k_decay» может быть числовым, указывающим на скорость изменения «top_k». Например, «top_k_decay=0.95» означает, что «top_k» будет уменьшаться на 5% на каждом шаге. Значения могут варьироваться от 0.1 до 1.0, определяя, насколько быстро происходит уменьшение.
Top-P
Параметр «top_p» (также известный как «nucleus sampling») управляет выбором следующего слова из наиболее вероятных слов, сумма вероятностей которых достигает порогового значения «top_p». Это метод помогает сохранять разнообразие при генерации текста, фокусируясь на наиболее вероятных словах, которые составляют наиболее значимую часть распределения вероятностей.
Параметр «top_p» задает порог вероятности, до которого суммируются вероятности слов. Например, «top_p=0.9» означает, что будут рассматриваться слова, вероятность которых в сумме составляет 90% от всей вероятности. Это помогает избежать генерации текстов с низким качеством и повысить их разнообразие.
Значение «top_p» может быть числовым, например, от 0.1 до 1.0. Значение «top_p=0.9» обычно используется для сохранения хорошего баланса между разнообразием и когерентностью текста. Значения близкие к 1.0 приводят к более широкому выбору слов, а значения близкие к 0.1 – к более узкому выбору.
Top-P Decay
Параметр «top_p_decay» регулирует изменение значения «top_p» в процессе генерации текста. Этот параметр позволяет динамически изменять порог вероятности, который используется для выбора слов.
Использование «top_p_decay» позволяет постепенно корректировать уровень разнообразия текста, начиная с более высоких значений «top_p» и уменьшая его по мере генерации. Это может улучшить когерентность текста по мере его создания.
Значение «top_p_decay» может быть числовым, определяющим скорость изменения порога «top_p». Например, «top_p_decay=0.95» означает, что «top_p» будет уменьшаться на 5% на каждом шаге.
Рассмотрим на примерах промпты с параметрами, которые могут быть использованы для генерации и перефразирования текстов.
Пример 1, контроль длины и разнообразия, рис. 20.
Перефразируй следующий текст, используя следующие параметры:
– max_length: 120
– min_length: 80
– diversity_penalty: 0.7
– temperature: 0.9
– top_p: 0.85
Текст:
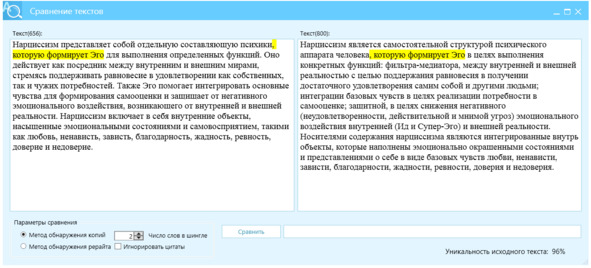
Рисунок 20 – Перефразированный текст, левое окно, источник – правое окно, отличие Ш2=96%
Пример 2, фокус на когерентности и отсутствие повторений, рис. 21.
Перефразируй данный текст с учетом следующих параметров:
– coherence_threshold: 0.8
– no_repeat_ngram_size: 2
– frequency_penalty: 0.5
– presence_penalty: 0.3
– temperature: 0.7
Текст:
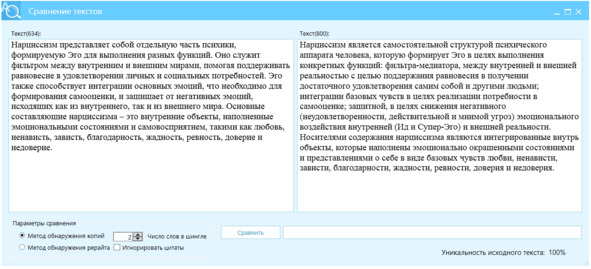
Рисунок 21 – Перефразированный текст, левое окно, источник – правое окно, отличие Ш2=100%
Пример 3, контроль за разнообразием и последовательностью, рис. 22.
Перефразируй текст, используя следующие параметры:
– diversity_temperature: 0.8
– top_k: 50
– coherence_threshold: 0.9
– early_stopping: true
– repetition_penalty: 1.2
Текст:
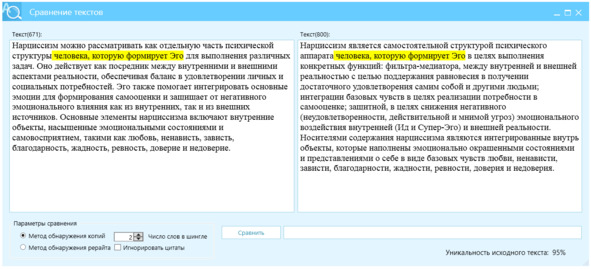
Рисунок 22 – Перефразированный текст, левое окно, источник – правое окно, отличие Ш2=95%
Пример 4, фокус на разнообразие и контекст, рис. 23.
Перефразируй текст, используя следующие параметры:
– diversity_penalty: 0.6
– diversity_temperature: 0.9
– context_window: 15
– max_length: 120
– min_length: 80
– coherence_threshold: 0.75
– stop_sequences: [».», «;»]
Текст:
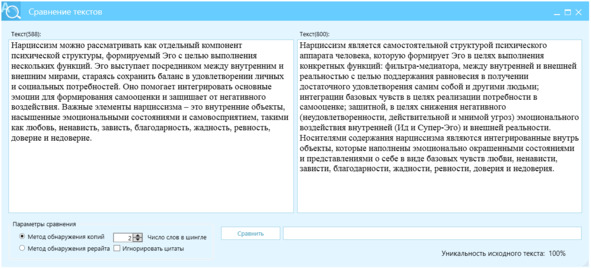
Рисунок 23 – Перефразированный текст, левое окно, источник – правое окно, отличие Ш2=100%
Пример 5, увеличение когерентности и избегание длинных предложений, рис. 24.
Перефразируй текст с использованием следующих параметров:
– coherence_threshold: 0.9
– max_length: 110
– min_length: 70
– encoder_no_repeat_ngram_size: 2
– length_penalty: 0.8
– repetition_penalty: 1.0
– temperature: 0.6
Текст:
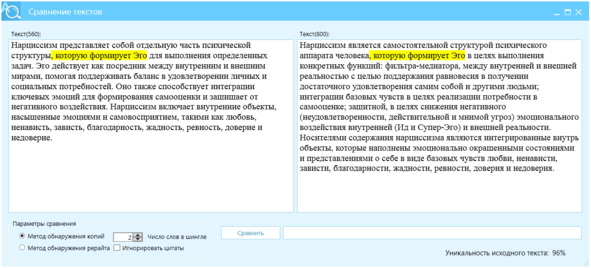
Рисунок 24 – Перефразированный текст, левое окно, источник – правое окно, отличие Ш2=96%
Пример 6, управление длиной текста и температурой, рис. 25.
Перефразируй текст, используя следующие параметры:
– max_length: 150
– min_length: 100
– temperature: 0.85
– top_k: 30
– top_p: 0.8
– diversity_penalty: 0.4
– early_stopping: true
Текст:

Рисунок 25 – Перефразированный текст, левое окно, источник – правое окно, отличие Ш2=100%