


Полная версия
Основы эконометрики в среде GRETL. Учебное пособие

А. С. Малова
Основы эконометрики в среде GRETL
Учебное пособие
Введение
Цель данного пособия – познакомить читателя с основами проведения эконометрических исследований в среде GRETL. Основная аудитория данной книги – студенты бакалавриата, обучающиеся по направлениям «Экономика», «Бизнес-информатика», «Управление персоналом», «Менеджмент», однако она может быть полезна и студентам других направлений, а также представителям бизнес-сообщества, которые по роду своей деятельности столкнулись с необходимостью проведения эконометрических исследований. Данное учебное пособие – это попытка практического изложения основ эконометрики с минимальными теоретическими выкладками, при этом предполагается, что недостаток теоретических знаний должен быть восполнен читателем самостоятельно с помощью учебников по основам эконометрики. Для обеспечения связи практических навыков с теоретическими знаниями в области эконометрики ко всем рассматриваемым темам даются ссылки на литературу. При этом основная задача данного пособия – помочь читателю в освоении эконометрики, изложить некоторые технические аспекты проведения исследований с использованием среды GRETL. Почему именно GRETL? Данный эконометрический пакет является бесплатным программным продуктом, который, с одной стороны, доступен любому пользователю, а с другой – обладает достаточно обширными возможностями для анализа данных и проведения эмпирических исследований. Немаловажным является и то, что в GRETL имеется значительный пул данных из большинства классических зарубежных учебников по основам эконометрики, что позволит достаточно легко переключиться с простейших примеров, рассмотренных в данном пособии, на более сложные содержательные задачи и кейсы из учебников.
В данном пособии весь материал излагается с точки зрения практики – то есть все основные разделы курса эконометрики для бакалавриантов даны в примерах и задачах. Поскольку невозможно приобрести навык проведения эконометрических расчетов, только изучая учебник, предполагается, что читатель должен иметь возможность проделать все излагаемые действия на практике. С этой целью в пособии использовались данные из учебника J. M. Wooldridge «Basic econometrics», которые доступны в GRETL. Все наборы данных при первом обращении к ним в пособии обозначены ссылками и указателями на источник.
Перед тем как начать осваивать основы эконометрики в среде GRETL, необходимо скачать и установить на свой компьютер сам статистический пакет. Он доступен по ссылке http://GRETL.sourceforge.net/. Вся информация о том, как установить GRETL, приводится на сайте, поэтому нет нужды в подробном изложении, стоит лишь сказать, что программа имеет версию как под ОС Windows, так и под Mac OS, а также что библиотеки данных должны быть установлены отдельно, для этого нужно перейти по ссылке http://GRETL.sourceforge.net/GRETL_data.html.
Удачи в проведении интересных, содержательных и полезных эконометрических исследований!
1. Линейная регрессионная модель
Для начала введем некоторые обозначения. Предположим, что некоторая величина Y зависит от величин
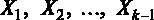
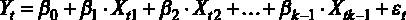
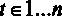
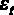
Модель такого вида называется классической линейной регрессионной моделью (ЛРМ) в случае, если выполняются следующие предпосылки:
1.
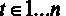
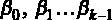
2.
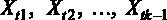
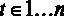
3.
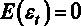
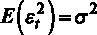
4.
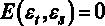
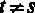
5. Если выполняется дополнительная предпосылка о нормальном распределении ошибок
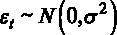
Подробнее о предпосылках линейной регрессионной модели можно прочесть в [2, 3].
2. Оценка линейной регрессионной модели
Рассмотрим множественную линейную регрессию
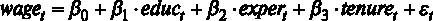
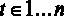
где
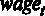
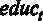
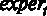
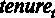
Для того чтобы оценить предложенную модель по методу наименьших квадратов (МНК), используем команду меню Модель – Метод наименьших квадратов.
В появившемся диалоговом окне в поле Зависимая переменная помещаем переменную
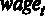
Для дальнейшего удобства можно поставить галочку в окошке Установить по умолчанию. Это делается для того, чтобы при изменении спецификации исследуемой модели зависимая переменная не менялась. В окно Регрессоры отправляем регрессоры модели – это переменные
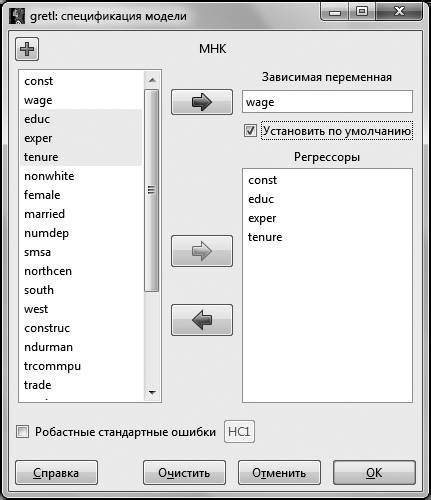
Рис. 2.1
После этого нажимаем ОК. В результате коэффициенты модели были оценены методом наименьших квадратов. Результат оценки представлен на рис. 2.2.
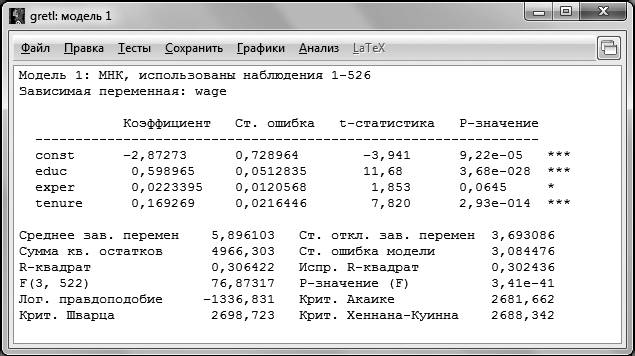
Рис. 2.2
Для того чтобы понимать, какие результаты позволяет получить GRETL, разберем информацию, представленную на распечатке по строкам сверху вниз.
В первой строке указывается метод оценки и количество наблюдений, по которым производилась оценка. Достаточно часто случается, что количество наблюдений, по которым производилась оценка, не совпадает с числом наблюдений в исходной выборке, даже если она не была ограничена. Это может быть связано, например, с наличием пропусков в данных.
Вторая строка напоминает нам о том, какая переменная была выбрана в качестве зависимой.
После двух первых строк следуют подтаблицы непосредственно с результатами оценивания. В первой подтаблице указаны регрессоры, включенные в модель, напротив каждого из них указывается его коэффициент (столбец Коэффициенты), стандартная ошибка оценки коэффициента (столбец Ст. ошибка), значение статистики Стьюдента для коэффициента (столбец t-статистика) и вероятность ошибки I рода (столбец P-значение). Стоит отметить, что константа тоже является регрессором, и для нее также рассчитываются все указанные характеристики.
По распечатке, представленной на рис. 2.2, мы можем выписать получившееся уравнение регрессии:
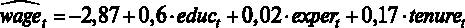
Аналогично можно получить оцененное уравнение и в GRETL, для этого выбираем в меню регрессии Файл – Просмотреть как уравнение.
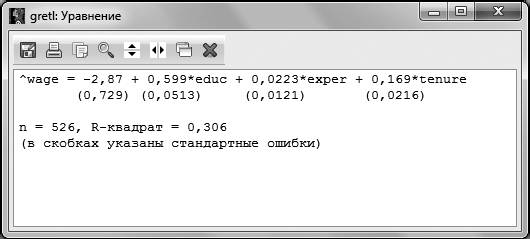
Рис. 2.3
Однако для того, чтобы иметь возможность дать интерпретацию коэффициентам регрессии и строить прогнозы, необходимо проверить, является ли полученная модель адекватной.
Для этого, в свою очередь, необходимо провести ряд эконометрических тестов, а именно проверить значимость регрессии в целом, значимость отдельных коэффициентов регрессии, оценить качество полученного регрессионного уравнения. Вообще говоря, перед проверкой значимости и качества уравнения необходимо провести тесты на выполнение основных предпосылок линейной регрессионной модели (гомоскедастичность, отсутствие автокорреляции). На данном этапе мы будем считать эти тесты проведенными и вернемся к вопросам выполнения предпосылок ЛРМ позднее.
3. Тест Фишера (Fisher test)
Для начала проверим гипотезу о незначимости регрессии в целом. Тест позволит понять, является ли построенная модель адекватной с точки зрения статистики. Для этой цели воспользуемся тестом Фишера [3].

Сформулируем гипотезы для проверки незначимости регрессии в целом в рассматриваемом примере [файл с данными wage1.gdt] модели
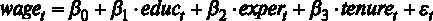
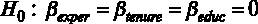
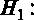
Для принятия решения о том, какую гипотезу нужно отвергнуть, построим F-статистику. Для этого нам должны быть известны (помимо уже имеющихся параметров n – объем выборки и k – число регрессоров в модели) величины RSS и ESS. В явном виде в распечатке на рис. 2.2 дано значение ESS – сумма квадратов остатков, которая составляет ESS = 4966,3, а также из распечатки известен коэффициент детерминации
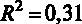
Если вспомнить, что
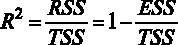
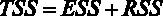
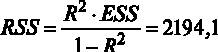
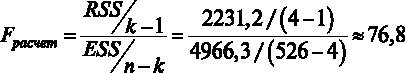
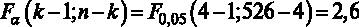
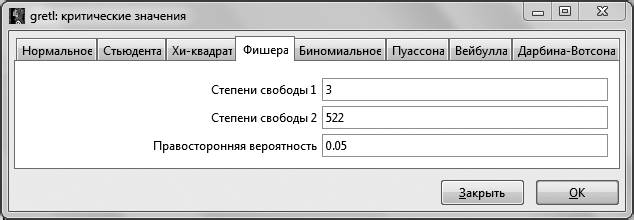
Рис. 3.1
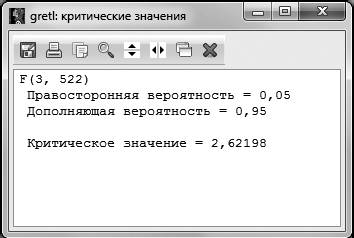
Рис. 3.2
Уровень значимости, на котором принимается решение о том, какую гипотезу не отвергать, остается на усмотрение исследователя. Как правило, если нет представления, какой именно уровень значимости брать, предлагается выбирать 5 %. В случаях работы с маленьким по объему выборками (от 30 до 100 наблюдений) предлагается брать уровень значимости 10 %. Для больших выборок (более 1000 наблюдений) можно взять уровень значимости 1 %. В нашем случае объем выборки средний (526 наблюдений, эта информация дана в первой строке распечатки на рис. 2.2.), поэтому можно было принять
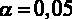
Сравниваем расчетное значение F-статистики с критическим
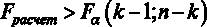
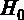
Тест Фишера можно провести также в полуавтоматическом режиме и в автоматическом режиме. Полуавтоматический режим состоит в том, что нам не нужно вручную вычислять значение расчетной F-статистики, оно дано в распечатке на рис. 2.2. В этом случае нужно лишь выяснить критическое значение F-статистики и сравнить расчетное значение с критическим.
В автоматическом режиме нужно также воспользоваться распечаткой GRETL и посмотреть на р-значение статистики Фишера на рис. 2.2 (в распечатке р-значение (F)). В р-значении содержится вероятность ошибки I рода. Таким образом, р-значение (F) для теста Фишера – это вероятность ошибки I рода при тестировании гипотезы

Конец ознакомительного фрагмента.
Текст предоставлен ООО «ЛитРес».
Прочитайте эту книгу целиком, купив полную легальную версию на ЛитРес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.