


Полная версия
Самоучитель. Курс SQL. Базы данных. ORACLE
SELECT (с англ. «выбрать») – это команда получения информации из базы данных и преобразование ее к любому удобному виду. С помощью этой команды можно выбирать данные из одной таблицы или сразу из нескольких (позже мы узнаем, что получать данные можно не только из таблиц). Получаемый результат можно сортировать, группировать, анализировать.
SELECT – это самая часто используемая команда языка SQL. С помощью нее можно получать как табличные данные (например, список клиентов с подробными сведениями о них, топ самых продаваемых товаров за прошлый год, или список доступных банковских продуктов для клиента), так и какую–либо обобщающую информацию – одним значением (например, доступный баланс на банковской карте или количество друзей друга/подруги в социальной сети, или даже оставшееся количество мест в любимом отеле на интересующую дату). Любые данные в любом виде из базы данных получает команда SELECT.
Синтаксис команды SELECT максимально прост. Чтобы выбрать какую–либо информацию из таблицы нужно написать:

Итак, чтобы выбрать информацию из некоторой таблицы, нужно написать слово SELECT, потом какие именно столбцы интересуют (через запятую), потом слово FROM и далее имя таблицы.
Любой запрос можно писать хоть весь в одну строку, хоть разбивать его на несколько строк. Если запрос получается большой и сложный, то, чтобы он был более легко читаем, его принято разбивать на несколько строк. Постепенно мы будем привыкать к хорошему стилю написания SQL–кода.
Теперь попробуем написать первую команду выборки данных:

Приведенный выше запрос выберет данные из таблицы Persons. Покажет информацию из столбцов ID и Name. Получим результат вида:

Давай выведем еще и даты рождения сотрудников:
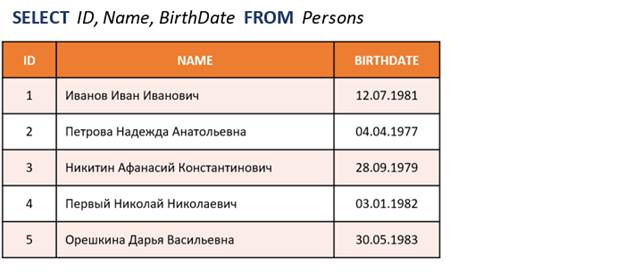
Чтобы полученный результат SQL–запроса упорядочить по одному или нескольким столбцам (сортировка данных), нужно в предложение добавить еще блок ORDER BY (с англ. «упорядочить по»):

Выборка информации из таблицы без условий, то есть всех строк данных (!) не часто бывает нужна и поэтому, почти всегда, на выбираемые строки из таблицы накладывают условие или условия, чтобы отбирать только подходящие условиям данные. Это делается с помощью блока WHERE. Именно в блоке WHERE пишутся одно или несколько (комбинация) условий, для определения отбираемых данных. Его место в запросе SELECT:

Блок ORDER BY всегда пишется в самом конце SQL–запроса!
Если к выводимым данным необходимо добавить данные еще из другой одной или нескольких таблиц (присоединить к выводящимся данным данные из других таблиц), то после того, как мы написали слово FROM и имя основной таблицы, мы можем присоединять дополнительные таблицы с помощью слова JOIN:

Ничего себе, сколько всего, скажешь ты, как это можно все запомнить и понять?! Каждый блок мы разберем по–отдельности и каждому уделим достаточно внимания!
Но и это еще не все. Есть еще одна возможность команды SELECT – это группировка.
Получаемые данные можно группировать по одному или нескольким признакам одновременно.
Для того чтобы указать по одинаковым значениям в каком столбце необходимо данные группировать, нужно команду SELECT дополнить блоком GROUP BY (с англ. «группировать по») и затем написать имя столбца, по которому необходима группировка. И теперь все строки получаемого набора данных будут группироваться по одинаковому значению в этом столбце.
Также, может понадобиться в конце года, например, отобрать «любимых» клиентов нашей организации для того, чтобы поздравить их с наступающими праздниками и сделать некоторый приятный бонус. Любимыми являются клиенты, у которых сумма заказов за прошедший год более 500.000 рублей.
Для решения подобной задачи, вначале, из таблицы «Продаж» мы отберем все сделки за прошедший год. Для выборки данных, согласно этому условию, воспользуемся блоком WHERE. Итак, когда данные будут извлечены из таблицы, за нужный нам промежуток времени, мы можем увидеть, что ни один из единичных заказов не больше 500.000 р. То есть ни в одной полученной строке в столбце «Сумма сделки» значение не больше 500.000 р. Но, если сгруппировать полученные данные по каждому клиенту (иными словами строки с одинаковым значением Клиента слить в одну, подсчитав Сумму сделок по каждому клиенту), то может получиться, что некоторые клиенты, суммарно за год, хорошо превышают этот порог.
До выполнения группировки мы видели в полученной таблице данных каждую строчку продаж, затем мы все данные сгруппировали по клиентам и стали видеть по каждому клиенту теперь только одну строку с общим итогом по нему.
Например, все выбранные продажи «Клиенту А» сгруппировались в одну строку, подсчитав сумму продаж ему, а все продажи «Клиенту Б» в другую строку, также с итогом по нему. И так по каждому клиенту. Теперь мы видим итоги с суммами продаж за год с группировкой по клиентам. Так как «Клиент А», например, в течение года каждый месяц делал заказы на 100.000 р. Поэтому, после группировки всех сумм его заказов, мы получим 1.200.000 р (100.000 × 12 месяцев).
Подробнее про группировку и ее мощные сопутствующие возможности, мы рассмотрим в отдельной главе. У нас будет сразу несколько уроков, связанных с группировкой, чтобы хорошо разобрать эту тему.
Место слова GROUP BY в предложении SELECT:

После группировки всех продаж за год в общем отчете, тем не менее, еще остается много клиентов, которые обращались в нашу компанию один или два раза, и, что самое главное, общая сумма их заказов не превышает порог «любимых клиентов». И таких клиентов много. Руководство нашей компании не хотело бы вручную из полученных итогов отбирать «Любимых клиентов». Чтобы оставить только нужные данные на основе получаемых сгруппированных итогов, мы воспользуемся опцией «HAVING» блока GROUP BY.
Важно понять, что только после группировки по клиентам мы смогли получить итоговую сумму заказов за год по каждому клиенту (до этого мы имели изначальную таблицу, где в строках были указаны стоимости единичных сделок), и, чтобы на основе уже этой полученной суммы (сгруппированной суммы) отфильтровать результирующий набор клиентов, мы можем применить HAVING.
На собеседованиях часто можно встретить такой вопрос: в чем разница между WHERE и HAVING? И теперь мы знаем ответ: WHERE выполняет первичный отбор данных из таблицы (таблиц) (в нашем примере, мы сначала отобрали данные продаж только за прошедший год), а HAVING отсеивает уже на основе сгруппированной информации.
То есть после того, как будут получены суммы по клиентам, в результирующем наборе останутся только те клиенты, у которых эти суммы более интересующего нас значения.
Конечно, мы можем отбирать строчки из таблицы заказов тех, где «Сумма сделки» больше, например, определенной. Но у нас задача была другая. Нам необходимо было получить клиентов, сумма заказов за год которых превысила 500.000 р. Поэтому мы применили сначала WHERE, для первичного отбора строчек данных из таблицы «Заказов» тех, которые относятся к прошедшему году, и затем воспользовались группировкой GROUP BY по клиентам с подсчетом «Сумм сделок» по каждому их них с опцией HAVING, чтобы на основе сгруппированной (агрегированной, то есть обобщенной) информации сделать еще одну фильтрацию данных.
HAVING следует писать после GROUP BY:

И это уже полная структура одного предложения SELECT. Полный список ключевых слов, которые можно применять при выборке данных. Из всех перечисленных ключевых слов обязательными являются только SELECT и FROM. Запросы могут быть даже без WHERE и без сортировки – ORBER BY. Главное, что всегда нужно указывать, – это какие столбцы отбирать и откуда.
Конечно, мы будем применять еще и кейсы, и подзапросы, но это все будет строиться на основе структуры, которая приведена выше. Поэтому, ее нужно запомнить.
Для Гуру: в СУБД MS SQL Server и MySQL даже FROM не обязателен при выводе данных, но это исключение и применяется при решении специфических задач. Объясню тебе про это на уроке про псевдотаблиц.
4. Написание простых запросов получения данных
4.1. Выборка некоторых или всех столбцов из таблицы
Дорогой читатель, в начале следующей главы мы разберем как установить ORACLE и создать базу данных на своем компьютере. А также, мы познакомимся с программой SQL Developer, одним из самых распространенных средств работы с базами данных ORACLE. Пройдя по ссылке, ты скачаешь скрипт и загрузишь его в свою новую, пока пустую, базу данных. После прогрузки скрипта, у тебя появятся таблицы с тестовыми (учебными) данными. И все это за несколько простых шагов!
Теперь у тебя будет фактически подготовленное рабочее (учебное) место!
В конце каждой главы для тебя подготовлены практические задачи! Их нужно постараться сделать максимально самостоятельно. К некоторым задачам будут даваться рекомендации к выполнению, к некоторым – нет. Это значит, что их можно будет решить любым способом. Некоторые задачи можно будет решить только комбинацией методов. Большинство задач – это стандартные задачи, которые решают специалисты по SQL, а некоторые – нестандартные. С помощью них, ты научишься нестандартно и более глубоко понимать SQL. Если ты в течение часа не смог решить некоторую задачу, ее можно отложить и попробовать вернуться к ней, например, попозже или завтра! Многие мои ученики иногда так справлялись с достаточно трудными запросами, и, на второй день, почти всегда говорили, что смогли взглянуть на задачу под другим углом.
После списка задач к каждой главе ты найдешь решения к задачам. Мы подробно вместе прорешаем каждую задачу. Но не нужно этим пользоваться сразу, если у тебя не получается решить задачу. Желательно, ответами пользоваться минимум завтра. Ты получишь больше пользы, если сможете решить задачу сам, пусть и дольше.
В предыдущей главе мы рассмотрели общую структуру любого предложения SELECT. Работая постоянно с запросами, через довольно короткое время, мы запомним назначение и расположение каждого блока и еще чуть позже, будем правильно и максимально эффективно их использовать! Теперь, в качестве примеров, составим несколько простых SQL–запросов.
Напишем запрос, выбирающий сотрудников из таблицы Persons, который отображал бы их Фамилию Имя Отчество, Дату рождения и идентификатор филиала, в котором они работают. Фамилия Имя Отчество лежит в колонке NAME, Дата рождения – в колонке BIRTHDATE и идентификатор филиала – в графе FilialID:

Выполняем запрос и получаем результат:
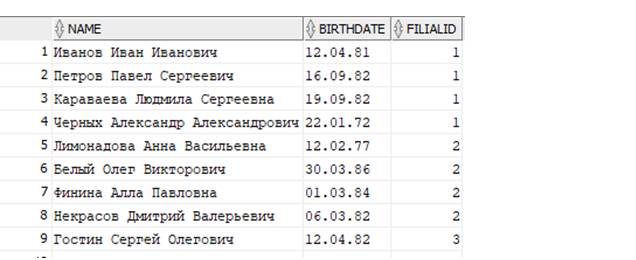
Как видим, вывелись именно запрошенные столбцы из таблицы. И еще, первый столбец, – сквозная нумерация строк возвращаемых данных. Мы его не запрашивали нашей SQL–командой. И на самом деле, это не ORACLE нам его вернул вместе с возвращаемыми запросом данными, а сама программа через которою мы работаем в базе данных (в нашем случае программа SQL Developer) добавила нам его для удобства. Далее не будем обращать на него внимание.
Запрос вернул 21 запись (21 строку). В целях экономии места в книге, мы иногда будем отображать не все возвращаемые данные.
4.2. Использование условий при получении данных. Ключевое слово WHERE
Теперь доработаем запрос, пусть он выведет только сотрудников, где в графе FilialID равно 2:

Как видим из получаемых данных, во втором филиале у нас работает 4 сотрудника!
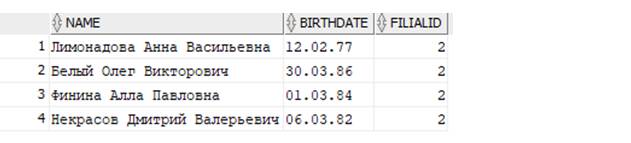
СУБД ORACLE, выполняя команду SELECT, выбирает для нас такие строчки из всей таблицы Persons, где в колонке FilialID значение равно двум!
Какие символы, помимо знака равно, можно использовать в условиях:
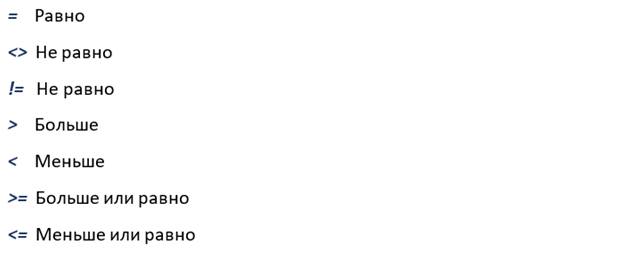
Как мы видим, если в SQL запросе нужно выбрать данные с условием на неравенство, то мы можем написать как <>, так и !=.
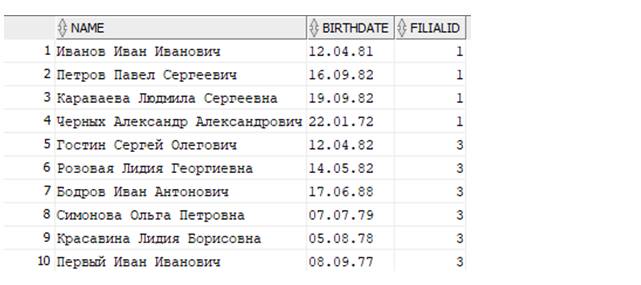
Следующей командой выберем сотрудников, работающих не во втором филиале:

Выведутся данные (всего 17 строк, для экономии места вот первых 10):
4.3. Сортировка данных. Блок ORDER BY
Теперь полученные данные мы можем еще и упорядочить по Фамилии Имени Отчеству. Для этого допишем блок ORDER BY.

В блоке ORDER BY (с англ. «упорядочить по») указали графу NAME, так как согласно значению в этом столбце нам необходимо было упорядочить строки. В результате получаем следующую таблицу с данными:
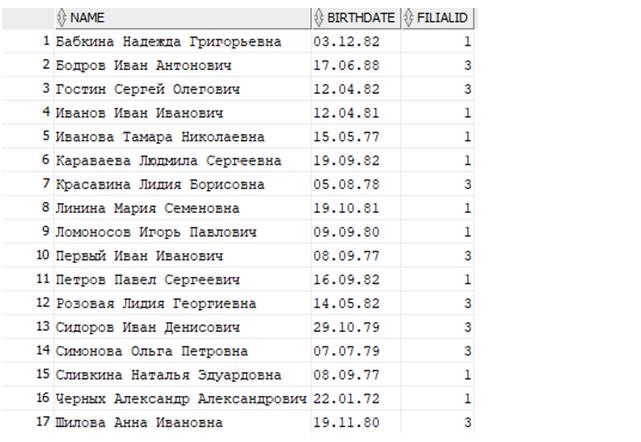
Как видим, строки упорядочены (отсортированы) по Фамилии Имени Отчеству. Точно также, если нам нужно было бы расставить сотрудников не в алфавитном порядке согласно их ФИО, а, например, согласно их дате рождения, то в боке ORDER BY указали бы BIRTHDATE.
Всякий раз, указывая значение столбца, по которому ведется сортировка строк, мы можем сортировать как в прямом порядке, так и в обратном. Для сортировки строк в обратном порядке нужно сразу после имени столбца написать слово DESC. И все!
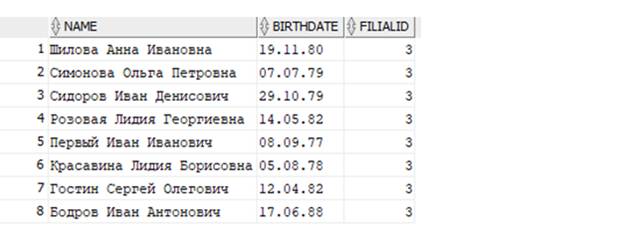
Выведем сотрудников третьего филиала, упорядоченных по Фамилии Имени Отчеству в обратном порядке:

Получаем:
А теперь выведем тех же самых сотрудников, но в прямом порядке. Не в обратном! Для этого нужно просто убрать DESC. Или вместо DESC написать ASC.

ASC и DESC – это такие «флажки» для ORACLE, указывающий на то, в каком направлении требуется упорядочить данные. Если ASC после столбца не указывать, то СУБД итак поймет, что данные нужно упорядочить в прямом порядке, ведь DESC–то нету! Так как не писать ASC проще, чем писать его, его использование уходит в прошлое. Его уже почти никто не использует. Но, если Вы придете работать в компанию, которая существует уже много лет, и Вам нужно будет в рамках некоторой задачи доработать отчет, вернее его запрос, на основе которого формируются данные, и если Вы там увидите ASC, то теперь Вы будет знать, что это означает! Язык SQL, подобно любому человеческому языку, также стремится к простоте. Отбрасывая то, что можно опустить, не использовать. И при этом сохраняя однозначность выполнения.
В процессе изучения языка SQL, мы встретим еще несколько «отмирающих» слов, неиспользование которых не является ошибкой. Эти слова попросту не несут в себе дополнительного смысла, и присутствие их даёт такой же результат, как и отсутствие.
4.4. Выборка данных по нескольким условиям. Использование AND и OR. Приоритеты операторов
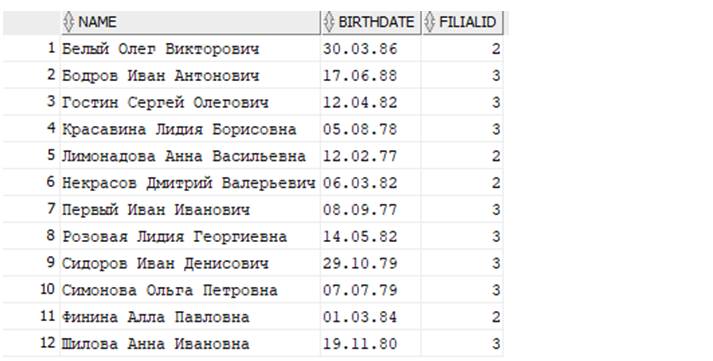
Теперь рассмотрим, как сочетать несколько условий в одном блоке WHERE. Выведем сотрудников, работающих в филиале 2 или 3, упорядоченных по ФИО. По сути, нужно вывести все строчки из таблицы Persons, в которых в столбце FilialID значение равно 2 или 3. Если в строчке в графе FilialID = 2 – показываем такую строку! Если 3 – тоже показываем!

Результат:
Одна из типичных ошибок, которую совершают начинающие специалисты SQL, они иногда пишут так:

И потом удивляются, почему запрос не может «отработать»? Так писать неправильно, так как ORACLE (или другая СУБД) не сможет однозначно понять, что имелось ввиду. ORACLE, получая такой запрос, «думает»: нужно вывести строчки в которых в столбце FilialID значение равно двум или… три. И тут не понятно, что – «три»?! Значение в каком столбце должно быть равно трем? На эту тему есть старинный анекдот:
Летят Петька и Василий Иванович в самолёте. Василий Иванович:
– Петька, приборы?
– Девять!
Летят дальше. Через некоторое время Василий Иванович снова:
– Петька, приборы?!
– Девять!
– Что «девять»–то?
– А что «приборы»?
Всегда нужно указывать и второе условие (то, что после OR) полностью! Правильно так:

В SQL запросе, для комбинации условий, мы использовали OR. С помощью него из таблицы будет выведена всякая строчка в случае, если выполняется одно, либо другое условие. То есть, минимум одно из них. ORACLE, пробегая по всей таблицы (Persons) и решая какую строчку выбрать нам в результирующий набор, будет сначала пробовать первое условие. То есть смотреть значение «2» ли в поле FilialID. Если нет, то может в поле FilialID значение «3»? Если да, то строчка будет выбрана, и мы ее увидим.
В следующем примере выведем строчки таблицы, соответствующие одновременно двум условиям. Для наглядности, добавим еще и вывод идентификатора департамента сотрудника:

Из таблицы Persons отберутся такие строчки, в которых в столбце FilialID значение равно 1 и одновременно в этой же строке в столбце DepartamentID значение равно 2. Результат:

В одном запросе можно одновременно использовать AND и OR:

Беглым взглядом не понятно, какие данные хотел отобрать разработчик: то ли сотрудников, работающих в филиале 1 и в департаменте 2 или 3, то ли сотрудников, работающих в первом филиале и втором департаменте и еще в департаменте 3 и в не важно каком филиале. На самом деле, OR имеет больший вес, чем AND, и поэтому разделит условие на два: отберутся сотрудники с филиала 1 и с одновременным отнесением ко второму департаменту, а также те, у кого просто указан третий департамент. Чтобы данный SQL–код был более наглядным, рекомендуется использовать скобки, чтобы расставить приоритеты выполнения условий. Например, если требуется вывести сотрудников только первого филиала с департаментов 2 и 3, можно написать так:

Получим данные:

Чтобы вывести значения со всех столбцов таблицы необязательно их все перечислять в секции SELECT, для этого достаточно поставить звездочку:

5. Подготовка рабочего места
5.1. Скачивание и установка СУБД ORACLE
На сегодняшний день ORACLE занимает одно из лидирующих мест на рынке производителей систем управления базами данных и, к счастью, предоставляет свой продукт для скачивания в некоммерческих целях абсолютно бесплатно. То есть начинающие специалисты могут бесплатно установить на свой домашний компьютер СУБД и попрактиковаться, например, в составлении запросов.
Для того, чтобы в максимальной степени овладеть знаниями языка SQL, крайне необходимо сейчас установить на наш домашний компьютер или ноутбук ORACLE, программу SQL Developer и закачать тестовую базу данных, на которой мы будем выполнять практические задачи каждого урока! Это очень важно! Сейчас мы подготовим рабочее место.
Если у тебя будет что-то не получаться во время скачивания СУБД ORACLE с официального сайта или во время ее установки, то зайди ко мне по ссылке ниже – я подготовил для тебя инструкцию по максимально простому скачиванию и установке: https://prime-soft.biz/how-to-install
Ниже я опишу полный процесс скачивания и установки ORACLE с официального сайта, но, если не будет получаться, то обязательно воспользуйся ссылкой выше. Я помогу тебе!
Музыкант никогда не сможет научиться играть на музыкальном инструменте, если не будет практиковаться на нем, так и мы – не сможем стать специалистами SQL, если только прочитаем книгу! Обязательно нужна практика.
Сперва заходим на сайт https://oracle.com и нажимаем на кнопку меню в виде трех горизонтальных полос (на момент написания книги она находится слева сверху).
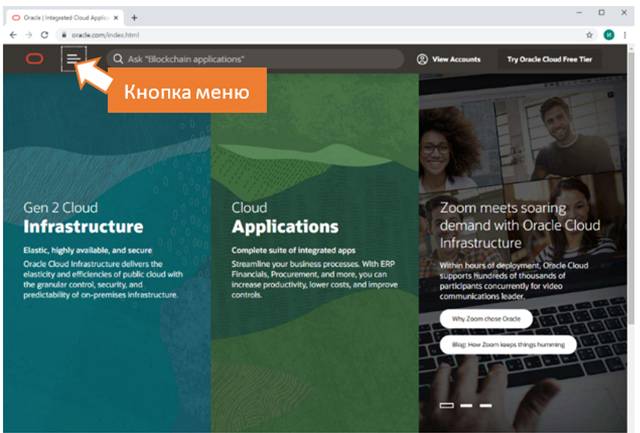
В открывшемся меню нажимаем Oracle Database.
На открывшейся странице нажимаем Download Oracle Database 19c (Загрузить Oracle версию 19c), даже если решим устанавливать другую версию. Переходим в список последних версий СУБД Oracle, доступных для закачивания для разных операционных систем. Ты должен знать какая у тебя версия операционной системы и какой битности: 32 или 64. Нам не важно какую версию СУБД ты установишь, 19.3, 18 или даже 12. Или, может быть, на момент чтения этой книги уже выйдет более новая версия Oracle. Главное, чтобы она подходила к твоей операционной системе. Например, у нас операционная система Windows 10 x64, тогда, мы можем загрузить, например, версию Oracle 19.3. Нажимаем на кнопку с надписью «Zip» напротив нашей версии ОС. В появившемся окне перед загрузкой, нужно установить галочку «I reviewed and accept the Oracle License Agreement» – это наше соглашение о неиспользовании ORACLE в коммерческих целях и дополнительная информация. И нажимаем загрузить.
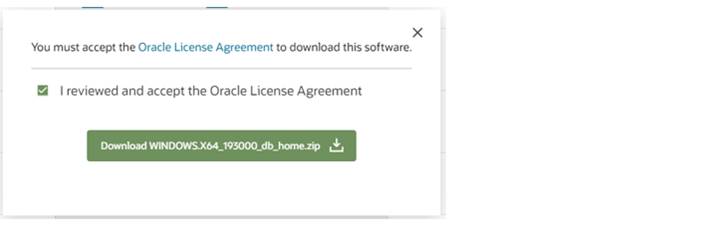
И последний шаг, который является обязательным уже несколько лет. На момент скачивания СУБД ORACLE, у тебя должен быть личный кабинет на сайте ORACLE. Если его нет, то ORACLE предложит его создать в несколько шагов. Из обязательного, тебе потребуется подтвердить адрес электронной почты и, если хочешь, при регистрации, можно установить флажок о желании получать приглашения на различные бесплатные обучающие вебинары от Oracle! Больше ничего и это займет еще несколько минут. Если регистрация в личном кабинете уже есть, нужно будет ввести адрес электронной почты и пароль, который ты ранее придумал.
Все готово, мы скачали Oracle на наш компьютер в виде стандартного zip–архивчика. Теперь его нужно распаковать. Распаковать лучше в каталог, путь до которого будет содержать только латинские буквы и цифры, то есть без пробелов и кириллицы. Например: «D:\Downloads\ORACLE» или «D:\ORACLE».
Есть еще один важный момент, который нужно учесть перед установкой Oracle. Проверь, пожалуйста, как называется твой компьютер. Каково его сетевое имя. Если он называется подобно «Мария ПК» или «Компьютер Андрея», то вначале его нужно переименовать и перезагрузить компьютер. Имя тоже должно быть дано латинскими буквами, без пробелов и спецсимволов, например: «MariaPC» или «Andry».
В каталоге, куда была распакована СУБД, найди файл setup.exe и запусти его. Сделать это лучше от имени администратора, то есть не двойным кликом, а щелкнув правой кнопкой мыши и выбрав из контекстного меню: «Запустить с правами администратора».
Через несколько мгновений, появится экран установки Oracle. В первом окне нужно выбрать пункт «Create and configure a single database» («Создать и конфигурировать базу данных»). Это самый первый пункт и далее нажать «Next» («Далее»).
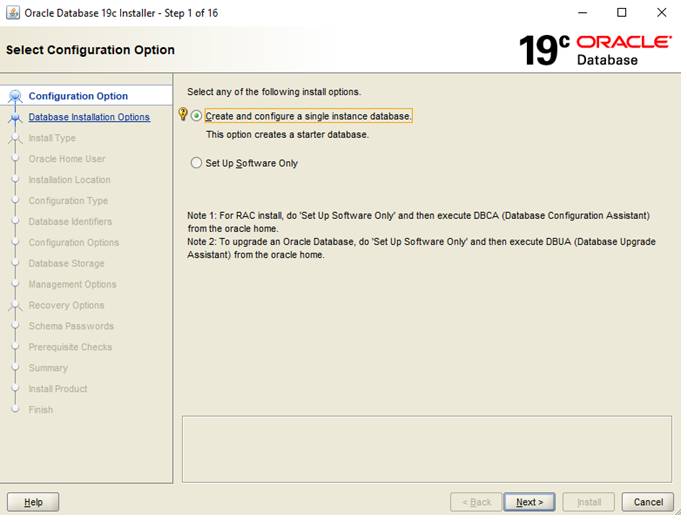
В открывшемся втором шаге мастера установки из двух пунктов «Desktop class» и «Server class» необходимо выбрать первый. Будет установлена версия СУБД с конфигурациями, максимально подходящими для домашнего компьютера или ноутбука. «Server class» используется на отдельных серверах, где устанавливаемой СУБД разрешается использовать всю мощность целевой машины. Нажимаем «Next».