




Полная версия
Думай «почему?». Причина и следствие как ключ к мышлению



Я сознательно упомянул думающие машины в предыдущем абзаце. Я пришел к этой теме, когда занимался компьютерными науками, конкретно искусственным интеллектом, что обобщает две точки отправления для большинства из моих коллег, занятых причинным анализом. Во-первых, в мире искусственного интеллекта вы по-настоящему не понимаете тему до тех пор, пока не обучите ей робота. Вот почему вы увидите, что я неустанно, раз за разом подчеркиваю важность системы обозначений, языка, словаря и грамматики. Например, меня завораживает вопрос, в состоянии ли мы выразить определенное утверждение на том или ином языке и следует ли это утверждение из других. Поразительно, сколько можно узнать, просто следуя грамматике научных высказываний! Мой акцент на язык также объясняется глубоким убеждением в том, что последний оформляет наши мысли. Нельзя ответить на вопрос, который вы не способны задать, и невозможно задать вопрос, для которого у вас нет слов. Изучая философию и компьютерные науки, я заинтересовался причинным анализом во многом потому, что мог с волнением наблюдать, как зреет и крепнет забытый когда-то язык науки.
Мой опыт в области машинного обучения тоже мотивировал меня изучать причинность. В конце 1980-х годов я осознал, что неспособность машин понять причинные отношения, вероятно, самое большое препятствие к тому, чтобы наделить их интеллектом человеческого уровня. В последней главе этой книге я вернусь к своим корням, и вместе мы исследуем, что значит Революция Причинности для искусственного интеллекта. Я полагаю, что сильный искусственный интеллект – достижимая цель, которой, к тому же не стоит бояться именно потому, что причинность – часть решения. Модуль причинного осмысления даст машинам способность размышлять над своими ошибками, выделять слабые места в своем программном обеспечении, функционировать как моральные сущности и естественно общаться с людьми о собственном выборе и намерениях.
Схема реальности
В нашу эпоху всем читателям, конечно, уже знакомы такие термины, как «знания», «информация», «интеллект» и «данные», хотя разница между ними или принцип их взаимодействия могут оставаться неясными. А теперь я предлагаю добавить в этот набор еще один термин – «причинная модель», после чего у читателей, вероятно, возникнет закономерный вопрос: не усложнит ли это ситуацию?
Не усложнит! Более того, этот термин свяжет ускользающие понятия «наука», «знания» и «данные» в конкретном и осмысленном контексте и позволит нам увидеть, как они работают вместе, чтобы дать ответы на сложные научные вопросы. На рис. 1. показана схема механизма причинного анализа, которая, возможно, адаптирует причинные умозаключения для будущего искусственного интеллекта. Важно понимать, что это не только проект для будущего, но и схема того, как причинные модели работают в науке уже сегодня и как они взаимодействуют с данными.
Механизм причинного анализа – это машина, в которую поступают три вида входных переменных – допущения, запросы и данные – и которая производит три типа выходных данных. Первая из входных переменных – решение «да/нет» о том, можно ли теоретически ответить на запрос в существующей причинной модели, если данные будут безошибочными и неограниченными. Если ответ «да», то механизм причинного анализа произведет оцениваемую величину. Это математическая формула, которая считается рецептом для получения ответа из любых гипотетических данных, если они доступны. Наконец, после того как в механизм причинного анализа попадут данные, он использует этот рецепт, чтобы произвести действительную оценку. Подобная неопределенность отражает ограниченный объем данных, вероятные ошибки в измерениях или отсутствие информации.
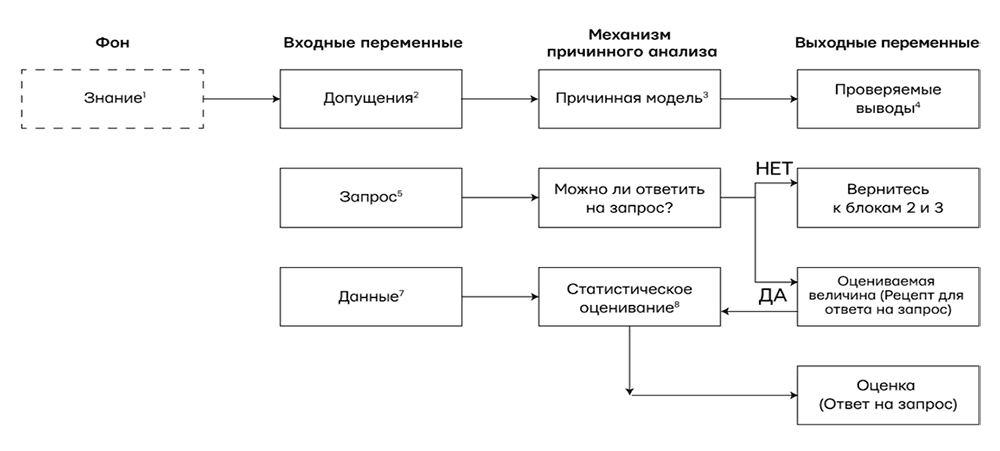
Рис. 1. Как механизм причинного анализа связывает данные со знанием причин, чтобы дать ответы на интересующие нас запросы. Блок, обозначенный пунктиром, не входит в механизм, но необходим для его построения. Также можно нарисовать стрелки от блоков 4 и 9 к блоку 1, но я решил сделать схему проще.
Чтобы объяснить схему подробнее, я пометил блоки цифрами от 1 до 9, и теперь прокомментирую их на примере запроса «Какой эффект лекарство D оказывает на продолжительность жизни L?»
1. «Знание» обозначает следы опыта, которые делающий умозаключения получил в прошлом. Это могут быть наблюдения из прошлого, действия в прошлом, а также образование и культурные традиции, признанные существенными для интересующего нас запроса. Пунктир вокруг «Знания» обозначает, что оно имеется в виду делающим умозаключения и не находит выражения в самой модели.
2. Научное исследование всегда требует упрощать допущения, т. е. утверждения, которые исследователь признает достойными, чтобы сформулировать их на основе доступного знания. Большая его часть остается подразумеваемой исследователем, и в модели запечатлены только допущения, которые получили формулировку и таким образом обнаружили себя. В принципе, их реально вычленить из самой модели, поэтому некоторые логики решили, что такая модель представляет собой всего лишь список допущений. Специалисты по компьютерным наукам делают здесь исключение, отмечая, что способ, избранный для представления допущений, в состоянии сильно повлиять на возможность правильно их сформулировать, сделать из них выводы и даже продолжить или изменить их в свете новой убедительной информации.
3. Причинные модели записываются в разной форме. Это могут быть диаграммы причинности, структурные уравнения, логические утверждения и т. д. Я убежденный приверженец диаграмм причинности почти во всех случаях – прежде всего из-за их прозрачности, но также из-за конкретных ответов, которые они дают на многие вопросы, которые нам хотелось бы задать. Для этой диаграммы определение причинности будет простым, хотя и несколько метафорическим: переменная X – причина Y, если Y «слушает» X и приобретает значение, реагируя на то, что слышит. Например, если мы подозреваем, что продолжительность жизни пациента L «прислушивается» к тому, какое лекарство D было принято, то мы называем D причиной L и рисуем стрелку от D к L в диаграмме причинности. Естественно, ответ на наш вопрос о D и L, вероятно, зависит и от других переменных, которые тоже должны быть представлены на диаграмме вместе с их причинами и следствиями (здесь мы обозначим их совокупно как Z).
4. Эта практика слушания, предписанная путями в причинной модели, обычно приводит к наблюдаемым закономерностям или зависимостям в данных. Подобные закономерности называются проверяемыми выводами, потому что они могут быть использованы для проверки модели. Это утверждение вроде «Нет путей, соединяющих D и L», которое переводится в статистическое утверждение «D и L независимы», т. е. обнаружение D не влияет на вероятность L. Если данные противоречат этому выводу, то модель нужно пересмотреть. Чтобы это сделать, требуется еще один механизм, которые получает входные переменные из блоков 4 и 7 и вычисляет «степень пригодности», или степень, до которой данные совместимы с допущениями модели. Чтобы упростить диаграмму, я не стал показывать второй механизм на рис. 1.
5. Запросы, поступающие в механизм причинного анализа, – это научные вопросы, на которые мы хотим ответить. Их необходимо сформулировать, используя термины причинности. Скажем, что такое P (L | do (D))? Одно из главных достижений Революции Причинности состоит в том, что она сделала этот язык научно прозрачным и математически точным.
6. Оцениваемая величина – это статистическая величина, которая оценивается на основе данных. После оценки данных она в состоянии обоснованно представить ответ на наш запрос. Если записать ее как формулу вероятности, например P (L | D, Z) × P (Z), то фактически получишь рецепт, как ответить на причинный запрос с помощью имеющихся у нас данных, когда механизм причинного анализа подтвердит эту возможность.
Очень важно осознавать, что, в отличие от традиционной оценки в статистике, нынешняя модель причинности порой не позволяет ответить на некоторые запросы, даже если какие-то данные уже собраны. Предположим, если наша модель покажет, что и D, и L зависят от третьей переменной Z (скажем, стадии болезни), и если у нас не будет способа измерить Z, то на запрос P (L | do (D)) нельзя будет получить ответ. В этом случае сбор данных окажется пустой тратой времени. Вместо этого придется вернуться назад и уточнить модель, либо добавив новые научные знания, которые позволят оценить Z, либо сделав допущения, которые все упростят (рискуя оказаться неправыми), например о том, что эффектом Z на D можно пренебречь.
7. Данные – это ингредиенты, которые используются в рецепте оцениваемой величины. Крайне важно осознавать, что данные абсолютно ничего не сообщают нам об отношениях причинности. Они обеспечивают нам значения, такие как P (L | D) или P (L | D, Z). Задача оцениваемой величины – показать, как «испечь» из этих статистических значений одну формулировку, которая с учетом модели будет логически эквивалентна запросу о причинности, скажем P (L | do (D)).
Обратите внимание, что само понятие оцениваемой величины и, более того, вся верхняя часть рис. 1 не существует в традиционных методах статистического анализа. Там оцениваемая величина и запрос совпадают. Так, если нам интересна доля тех, кто принимал лекарство D, среди людей с продолжительностью жизни L, мы просто записываем этот запрос как P (D | L). То же значение и будет нашей оцениваемой величиной. Оно уже определяет, какое соотношение данных надо оценить, и не требует никаких знаний о причинности. Именно поэтому некоторым статистикам по сей день чрезвычайно трудно понять, почему некоторые знания лежат за пределами статистики и почему одни только данные не могут заменить недостаток научного знания.
8. Оценка – то, что «выходит из печи». Однако она будет лишь приблизительной из-за еще одного свойства данных в реальном мире: они всегда относятся к ограниченной выборке из теоретически бесконечной популяции. В нашем текущем примере выборка состоит из пациентов, которых мы решили изучить. Даже если мы возьмем их произвольно, всегда останется некий шанс на то, что пропорции, которые мы определили, сделав измерения в выборке, не будут отражать пропорции в населении в целом. К счастью, статистика, как научная дисциплина, вооруженная продвинутыми приемами машинного обучения, дает нам великое множество способов справиться с этой неопределенностью: методы оценки максимальной вероятности, коэффициенты предрасположенности, интервалы доверия, критерии значимости и т. д. и т. п.
9. В итоге, если наша модель верна и если у нас достаточно данных, мы получаем ответ на запрос о причине, скажем такой: «Лекарство D повышает продолжительность жизни L у пациентов-диабетиков Z на 30 ± 20 %». Ура! Этот ответ добавит нам научных знаний (блок 1) и, если все пошло не так, как мы ожидали, обеспечит некоторые улучшения для нашей модели причинности (блок 3).
На первый взгляд, эта диаграмма может показаться сложной, и вы, вероятно, задумаетесь, необходима ли она. Действительно, в повседневной жизни мы каким-то образом способны выносить суждения о причине, не проходя через такой сложный процесс и точно не обращаясь к математике вероятностей и пропорций. Одной нашей интуиции о причинности обычно достаточно, чтобы справиться с неопределенностью, с которой мы сталкиваемся каждый день дома или даже на работе. Но, если мы захотим научить тупого робота думать о причинах или раздвинуть границы научного знания, заходя в области, где уже не действует интуиция, тщательно структурированная процедура такого рода будет обязательной.
Я хочу особенно подчеркнуть роль данных в вышеописанном процессе. Для начала примите во внимание, что мы собираем данные, предварительно построив модель причинности, сформулировав научный запрос, на который хотим получить ответ и определив оцениваемую величину. Это противоречит вышеупомянутому традиционному для науки подходу, в котором даже не существует причинной модели.
Однако современная наука ставит новые вызовы перед теми, кто практикует рациональные умозаключения о причинах и следствиях. Хотя потребность в причинной модели в разных дисциплинах становится очевиднее с каждым днем, многие исследователи, работающие над искусственным интеллектом, хотели бы избежать трудностей, связанных с созданием или приобретением причинной модели, и полагаться исключительно на данные во всех когнитивных задачах. Остается одна, в настоящий момент безмолвная надежда, что сами данные приведут нас к верным ответам, когда возникнут вопросы о причинности.
Я отношусь к этой тенденции с откровенным скепсисом, потому что знаю, насколько нечувствительны данные к причинам и следствиям. Например, информацию об эффекте действия или интервенции просто нельзя получить из необработанных данных, если они не собраны путем контролируемой экспериментальной манипуляции. В то же время, если у нас есть причинная модель, мы часто можем предсказать результат интервенции с помощью данных, к которым никто не прикасался.
Аргументы в пользу причинных моделей становятся еще более убедительными, когда мы пытаемся ответить на контрфактивные запросы, предположим: «Что бы произошло, если бы мы действовали по-другому?». Мы подробно обсудим контрфактивные запросы, потому что они представляют наибольшую сложность для любого искусственного интеллекта. Кроме того, развитие когнитивных навыков, сделавшее нас людьми, и сила воображения, сделавшие возможной науку, основаны именно на них. Также мы объясним, почему любой запрос о механизме, с помощью которого причины вызывают следствия, – самый прототипический вопрос «Почему?» – на самом деле контрфактивный вопрос под прикрытием. Таким образом, если мы хотим, чтобы роботы начали отвечать на вопросы «Почему?» или хотя бы поняли, что они значат, их необходимо вооружить моделью причинности и научить отвечать на контрфактивные запросы, как показано на рис. 1.
Еще одно преимущество, которое есть у причинных моделей и отсутствует в интеллектуальном анализе данных и глубинном обучении, – это способность к адаптации. Отметим, что на рис. 1 оцениваемая величина определяется на базе одной только причинной модели – еще до изучения специфики данных. Благодаря этому механизм причинного анализа становится невероятно адаптивным, ведь оцениваемая величина в нем подойдет для любых данных и будет совместима с количественной моделью, какими бы ни были числовые зависимости между переменными.
Чтобы понять, почему эта способность к адаптации играет важную роль, сравните этот механизм с системой, которая пытается учиться, используя только данные. В этом примере речь пойдет о человеке, но в других случаях ей может быть алгоритм глубинного обучения или человек, использующий такой алгоритм. Так, наблюдая результат L у многих пациентов, которым давали лекарство D, исследовательница в состоянии предсказать, что пациент со свойством Z проживет L лет. Но теперь ее перевели в новую больницу в другой части города, где свойства популяции (диета, гигиена, стиль работы) оказались другими. Даже если эти новые свойства влияют только на числовые зависимости между зафиксированными переменными, ей все равно придется переучиваться и осваивать новую функцию предсказания. Это все, на что способна программа глубинного обучения – приспосабливать функцию к данным. Однако, если бы у исследовательницы была модель для действия лекарства и если бы ее причинная структура оставалась нетронутой в новом контексте, то оцениваемая величина, которую она получила во время обучения, не утратила бы актуальности. Ее можно было бы применить к новым данным и создать новую функцию предсказания.
Многие научные вопросы выглядят по-другому «сквозь линзу причинности», и мне очень понравилось возиться с этой линзой. В последние 25 лет ее эффект постоянно усиливается благодаря новым находкам и инструментам. Я надеюсь и верю, что читатели этой книги разделят мой восторг. Поэтому я хотел бы завершить это введение, анонсировав некоторые интересные моменты книги.
В главе 1 три ступени – наблюдение, интервенция и контрфактивные суждения – собраны в Лестницу Причинности, центральную метафору этой книги. Кроме того, здесь вы научитесь основам рассуждений с помощью диаграмм причинности, нашего главного инструмента моделирования, и встанете на путь профессионального овладения этим инструментом. Более того, вы окажетесь далеко впереди многих поколений исследователей, которые пытались интерпретировать данные через линзу, непрозрачную для этой модели, и не знали о важнейших особенностях, которые открывает Лестница Причинности.
В главе 2 читатели найдут странную историю о том, как научная дисциплина статистика развила в себе слепоту к причинности и как это привело к далеко идущим последствиям для всех наук, зависящих от данных. Кроме того, в ней излагается история одного из величайших героев этой книги, генетика Сьюалла Райта, который в 1920-е годы нарисовал первые диаграммы причинности и долгие годы оставался одним из немногих ученых, осмелившихся воспринимать ее серьезно.
В главе 3 рассказывается равно любопытная история о том, как я обратился к причинности, работая над искусственным интеллектом – особенно над байесовскими сетями. Это был первый инструмент, который позволил компьютерам понимать «оттенки серого», и какое-то время я полагал, что они содержат главный ключ к искусственному интеллекту. К концу 1980-х годов я пришел к убеждению, что ошибался, и эта глава описывает мой путь от пророка до отступника. Тем не менее байесовские сети остаются очень важным инструментом для искусственного интеллекта и по-прежнему во многом определяют математическое основания для диаграмм причинности. Помимо постепенного знакомства с правилом Байеса и байесовскими методами рассуждения в контексте причинности, глава 3 представит увлекательные примеры того, как байесовские сети можно применить в реальной жизни.
Глава 4 рассказывает о главном вкладе статистики в причинный анализ – рандомизированном контролируемом исследовании (РКИ). С точки зрения причинности РКИ – это созданный человеком инструмент, позволяющий вскрыть запрос P (L | do (D)), возникший в природе. Главная его цель – отделить интересующие нас переменные (скажем, D и L) от других переменных (Z), которые в противном случае повлияли бы на обе предыдущие. Избавление от осложнений, вызванных такими неочевидными переменными, было проблемой в течение 100 лет. Эта глава показывает читателям удивительно простое ее решение, которое вы поймете за 10 минут, играючи проходя по путям в диаграмме.
Глава 5 повествует о поворотном моменте в истории причинности (и даже в истории всей науки), когда статистики столкнулись со сложностями, пытаясь выяснить, приводит ли курение к раку легких. Поскольку они не могли использовать свой любимый инструмент, РКИ, им было трудно прийти не только к единому выводу, но и к общему пониманию вопроса. Миллионы жизней оборвались или сократились из-за того, что ученым недоставало подходящего языка и методологии для ответов на вопросы о причинности.
Глава 6, надеюсь, даст читателям приятный повод отвлечься от серьезных вопросов из главы 5. Это глава о парадоксах – Монти Холла, Симпсона, Берксона и др. Классические парадоксы такого рода можно рассматривать как занимательные головоломки, однако у них есть и серьезная сторона, которая видна особенно хорошо, если взглянуть на них с точки зрения причинности. Более того, почти все они отражают столкновения с причинной интуицией и таким образом обнажают анатомию этой интуиции. Словно канарейки в шахте, они сигнализировали ученым, что человеческая интуиция укоренена в причинной, а не статистической логике. Я полагаю, читателям понравится новый взгляд на любимые парадоксы.
Главы 7–9 наконец-то позволят читателю совершить увлекательный подъем по Лестнице Причинности. Мы начнем в главе 7 с интервенции, рассказывая, как я со студентами 20 лет пытался автоматизировать запросы типа do. В итоге нам удалось добиться успеха, и в этой главе объясняется, как устроен механизм причинного анализа», который дает ответ «да/нет», и что такое оцениваемая величина на рис. 1. Изучив этот механизм, читатель получит инструменты, которые позволят увидеть в диаграмме причинности некие структуры, обеспечивающие немедленный ответ на причинный запрос. Это «поправки черного входа», «поправки парадного входа» и инструментальные переменные – «рабочие лошадки» причинного анализа.
Глава 8 поднимет вас на вершину лестницы, поскольку в ней рассматриваются контрфактивные суждения. Они считаются одной из необходимых составляющих причинности по меньшей мере с 1748 года, когда шотландский философ Дэвид Юм предложил для нее несколько искаженную дефиницию: «Мы можем определить причину как объект, за которым следует другой объект, если за всеми объектами, схожими с первым, следуют объекты, схожие со вторым. Или, другими словами, если бы не было первого объекта, второй бы не существовал». Дэвид Льюис, философ из Принстонского университета, умерший в 2001 году, указал, что на деле Юм дал не одно, а два определения: во-первых, регулярности (т. е. за причиной регулярно идет следствие) и, во-вторых, контрфактивности («если бы не было первого объекта…»). Хотя философы и ученые в основном обращали внимание на определение регулярности, Льюис предположил, что определение контрфактивности лучше сопрягается с человеческой интуицией: «Мы считаем причиной нечто, вызывающее перемену, и это перемена относительно того, что случилось бы без нее».
Читателей ждет приятный сюрприз: теперь мы можем отойти от научных дебатов и вычислить настоящее значение (или вероятность) для любого контрфактивного запроса – и неважно, насколько он изощрен. Особый интерес вызывают вопросы, связанные с необходимыми и достаточными причинами наблюдаемых событий. Например, насколько вероятно, что действие ответчика было неизбежной причиной травмы истца? Насколько вероятно, что изменения климата, вызванные человеком, являются достаточной причиной аномальной жары?
Наконец, в главе 9 обсуждается тема медиации. Возможно, когда мы говорили о рисовании стрелок в диаграмме причинности, вы уже задавались вопросом, стоит ли провести стрелку от лекарства D к продолжительности жизни L, если лекарство влияет на продолжительность жизни только благодаря воздействию на артериальное давление Z (т. е. на посредника). Другими словами, будет ли эффект D, оказываемый на L, прямым или непрямым? И если наблюдаются оба эффекта, как оценить их относительную важность? Подобные вопросы не только представляют большой научный интерес, но и могут иметь практические последствия: если мы поймем механизм действия лекарства, то, скорее всего, сумеем разработать другие препараты с тем же эффектом, которые окажутся дешевле или будут иметь меньше побочных эффектов. Читателя порадует тот факт, что вечный поиск механизма медиации теперь сведен до упражнения в алгебре, и сегодня ученые используют новые инструменты из набора для работы с причинностью в решении подобных задач.
Глава 10 подводит книгу к завершению, возвращаясь к проблеме, которая изначально привела меня к причинности: как автоматизировать интеллект человеческого уровня (его порой называют сильным искусственным интеллектом). Я полагаю, что способность рассуждать о причинах абсолютно необходима машинам, чтобы общаться с нами на нашем языке о политических мерах, экспериментах, объяснениях, теориях, сожалениях, ответственности, свободной воле и обязанностях – и в конечном счете принимать собственные этические решения.
Если бы я мог суммировать смысл этой книги в одной лаконичной и многозначительной фразе, она была бы такой: «Вы умнее ваших данных». Данные не понимают причин и следствий, а люди их понимают. Я надеюсь, что новая наука о причинном анализе позволит нам глубже осознать, как мы это делаем, ведь нет более эффективного способа понять себя, чем смоделировать себя. В эпоху компьютеров это новое знание также добавляет перспективу усилить наши врожденные способности, чтобы лучше постигать данные – как в больших, так и в малых объемах.
Глава 1. Лестница причинности
В начале…
Мне было, наверное, шесть или семь лет, когда я впервые прочел историю об Адаме и Еве в Эдемском саду. Мы с одноклассниками абсолютно не удивились капризным требованиям Бога, который запретил им есть плоды с древа познания. У божеств на все есть свои причины, думали мы. Но нас заинтриговал тот факт, что, когда Адам и Ева вкусили запретный плод, они, как и мы, стали осознавать свою наготу.
