


ИИ-2041. Десять образов нашего будущего



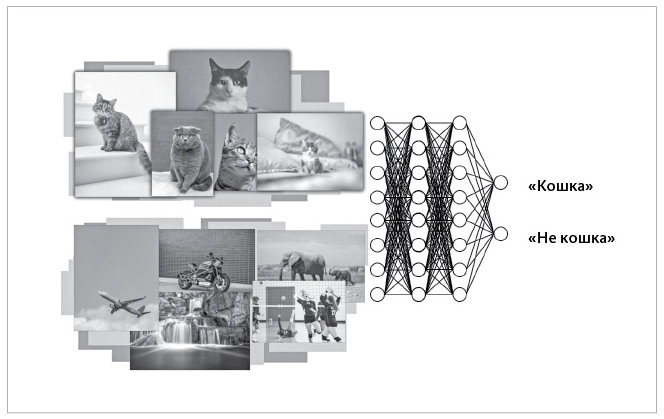
Нейронная сеть глубокого обучения, обученная отличать фото кошек от фотографий, на которых изображено что-то другое
В ходе этого процесса глубокая нейросеть математически обучается (или «тренируется») максимизировать значение «целевой функции». В нашем примере с распознаванием кошки такой целевой функцией является вероятность правильного распознавания «кошка» – «не кошка».
После такой тренировки сеть глубокого обучения, по сути, становится гигантским математическим уравнением; его можно протестировать на изображениях, которых она до этого не видела, и убедиться, что сеть путем «умозаключений» способна определить наличие или отсутствие в этих изображениях кошки.
С появлением глубокого обучения совершенно непрактичные ранее возможности ИИ стали пригодными для применения во многих областях и сферах. На следующей диаграмме наглядно показано, как резко сократилось число ошибок распознавания образов, когда начали использовать технологии глубокого обучения.
Глубокое обучение – это технология универсального применения, ее можно использовать практически в любой области для распознавания образов, прогнозирования, классификации данных, принятия решений или синтеза. Возьмем сферу страхования, о которой идет речь в рассказе «Золотой слон».
ИИ в приложениях Ganesh Insurance предобучили оценивать вероятность развития у клиента компании серьезных проблем со здоровьем и соответствующим образом корректировать его страховой взнос.
Чтобы сеть научилась отделять тех, у кого с большой вероятностью возникнут такие проблемы, от тех, у кого они, скорее всего, не возникнут, ИИ «тренируют» на обучающих данных, включающих в себя информацию обо всех прошлых заявителях на получение страховки, обо всех их обращениях в медицинские учреждения с разными жалобами и об их семьях. Каждый случай маркируют на выходном слое меткой «обращался с серьезными медицинскими проблемами» или «не обращался с серьезными медицинскими проблемами».
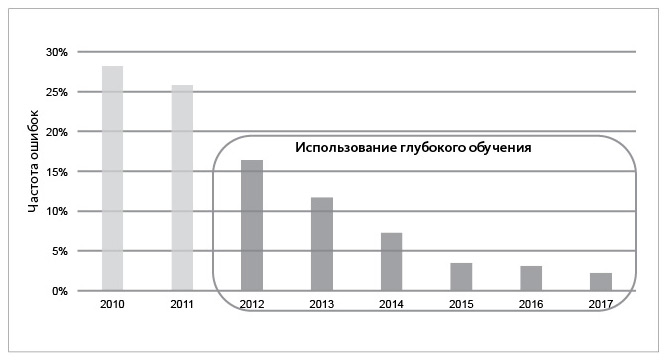
Использование глубокого обучения привело к существенному снижению частоты ошибок при распознавании объектов компьютерным зрением
Впитав в себя в процессе предобучения весь этот набор данных, ИИ может делать предсказания вероятности возникновения у заявителя серьезных проблем со здоровьем и решать, одобрять заявку на страхование или нет, и если да, то каким при этом должен быть страховой взнос.
Обратите внимание: в данном сценарии ни одному человеку не придется маркировать претендента на оформление страховки как объект, имеющий риски с точки зрения здоровья или же не имеющий таковых. Эти метки основываются исключительно на «достоверной информации» (например, были ли у претендента на оформление страховки серьезные жалобы на здоровье в прошлом).
ГЛУБОКОЕ ОБУЧЕНИЕ: ПОТРЯСАЮЩИЕ ВОЗМОЖНОСТИ. НО – С ОГРАНИЧЕНИЯМИПервая научная статья о глубоком обучении вышла еще в 1967 году. Потребовалось более полувека, чтобы эта технология проявила себя. Это заняло так много времени, потому что для обучения искусственной нейронной сети требуется огромное количество данных и вычислительных мощностей. И если вычислительные мощности – двигатель ИИ, то данные – его топливо.
Вычисления стали достаточно быстрыми для эффективного применения технологии глубокого обучения только в последнее десятилетие, и мы наконец научились собирать достаточное количество данных. Смартфон, которым вы пользовались сегодня, обладает в миллионы раз большей вычислительной мощностью, чем компьютеры НАСА, отправившие Нила Армстронга на Луну в 1969 году. А интернет 2020 года почти в триллион раз больше интернета 1995 года.
Глубокое обучение – результат озарения человеческого мозга, но работают они совершенно по-разному. Глубокому обучению требуется гораздо больше данных, чем человеку, но после обучения работе с ними технология значительно превосходит людей в решении многих задач, особенно связанных с количественной оптимизацией (например, выбор рекламного объявления для максимизации вероятности покупки или поиск нужного лица среди миллионов других).
Люди могут одновременно сосредоточиваться на ограниченном количестве объектов, а алгоритм, предобученный на океане информации, выявляет корреляции между неявными признаками, слишком незаметными или сложными для человека.
Кроме того, в процессе предобучения на огромном объеме данных глубокое обучение может подстраиваться под отдельных пользователей, базируясь на их паттернах поведения, равно как и на аналогичных шаблонах у других пользователей. Например, когда вы посещаете Amazon, ИИ этого веб-сайта выделяет или подсвечивает продукты, которые, скорее всего, должны вас заинтересовать и, соответственно, максимально увеличат ваши расходы.
А контент на вашей странице в Facebook◊[20] должен удержать вас в соцсети как можно дольше. ИИ Amazon и социальной сети таргетированный (узконаправленный); он предлагает каждому человеку разный, но персонализированный контент. Это значит, что показанный мне контент, скорее всего, сильно повлияет на меня, но может совершенно не сработать в вашем случае. Подобная узкая нацеленность гораздо эффективнее генерирует клики и покупки, чем универсальный подход традиционных статических веб-сайтов.
Каким бы мощным инструментом ни было глубокое обучение, панацеей его, увы, не назовешь. Человеку не сравниться с ИИ в деле одновременного анализа огромного количества данных, но мы обладаем уникальной способностью опираться при принятии решений на прошлый опыт, абстрактные концепции и здравый смысл.
Глубокому обучению для эффективной работы требуются огромные объемы релевантных данных, узкая конкретная сфера действия и четкая целевая функция. Если чего-то из этого нет – вероятнее всего, ничего путного не выйдет.
Мало данных? В алгоритме будет недостаточно примеров для выявления значимых корреляций. Несколько разных областей? Алгоритм не сможет учесть корреляции между примерами из разных областей и не получит достаточно данных, чтобы охватить все возможные перестановки. Слишком общая целевая функция? Алгоритм не будет иметь четких указаний для ее оптимизации.
Важно понимать, что «мозг ИИ» (собственно, глубокое обучение) работает совсем не так, как мозг человека. Их основные различия показаны в таблице 1:
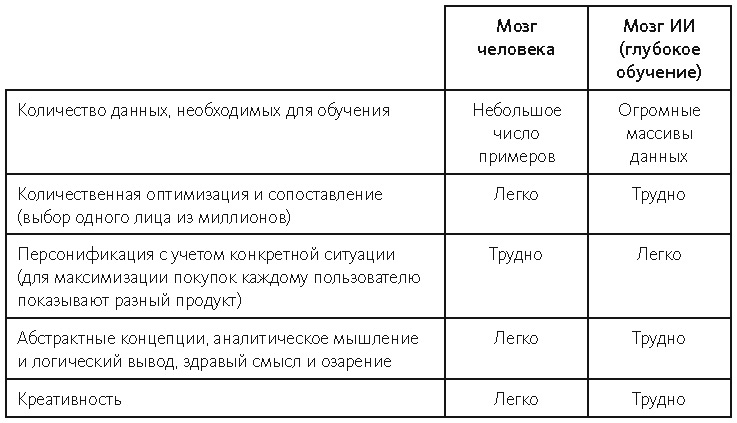
Таблица 1. Сравнение сильных и слабых сторон человеческого мышления и «мышления» ИИ
ПРИМЕНЕНИЕ ГЛУБОКОГО ОБУЧЕНИЯ В ИНТЕРНЕТЕ И ФИНАНСАХЕсли вспомнить упомянутые выше сильные и слабые стороны глубокого обучения, то станет понятно, почему первыми бенефициарами этой формы ИИ стали крупнейшие интернет-компании. Высокотехнологические гиганты вроде Facebook◊ и Amazon располагают самыми большими базами данных, которые к тому же часто размечаются автоматически в зависимости от действий пользователя (пользователь кликнул или купил? сколько минут он оставался на странице?).
Эти действия пользователей напрямую связываются с бизнес-метрикой (доход или количество кликов), которую необходимо максимизировать. Если заданные условия выполнены, приложение или платформа превращаются в денежный станок. Чем больше данных накапливается, тем большую выручку приносит платформа. Неудивительно, что интернет-гиганты вроде Google, Amazon и других за последнее десятилетие показали поистине феноменальный рост и все активнее используют ИИ.
Как мы увидели в рассказе «Золотой слон», следом за интернет-компаниями огромный потенциал ИИ взяла на вооружение финансовая сфера, в том числе банки и те самые страховые компании.
Страховая отрасль обладает теми же преимуществами, что и интернет-компании: большой объем высококачественных данных из одной сферы (страхование), привязанных к бизнес-метрикам. С появлением финансово-технологических компаний, основанных на ИИ, таких как Lemonade и Waterdrop[21], появилась возможность покупать страховку или брать ссуду в компьютерном приложении с мгновенным одобрением.
Сегодня финтех-компании всерьез нацелены на победу над традиционными финансовыми корпорациями – ведь они показывают лучшие финансовые результаты (более низкий уровень дефолтов или мошенничества), предлагают клиентам мгновенные транзакции (с использованием ИИ и приложений) и более низкие затраты (благодаря исключению из этого цикла человеческого фактора). Однако и традиционные финансовые компании не сидят сиднем, а тоже спешно внедряют ИИ – так что гонка стартовала.
Есть еще одно любопытное преимущество финтех-компаний, взявших на вооружение ИИ: возможность использовать не только те данные, которые учитывают специалисты-люди. Иначе говоря, они укрепляют свою прогностическую силу за счет анализа огромного числа разнородных данных, которые не способен учесть никакой страховой агент.
Который не сумеет оценить, например, покупаете вы больше неполезных обработанных пищевых продуктов или полезных овощей; проводите вы больше времени в казино или в тренажерном зале; есть ли у вас постоянная подруга или вы вечно пристаете к женщинам в интернете. Но эти данные могут поведать о вас много важного, в том числе и о вашем относительном риске в качестве клиента страховой компании.
Кстати, миллионы единиц информации (или «признаков») можно найти в приложениях для мобильного телефона. Вот почему в нашем первом рассказе услуги Ganesh Insurance представлены в виде группы приложений под названием «Золотой слон». Они охватывают всё – от электронной коммерции до рекомендаций и купонов, инвестиций, ShareChat (реальная популярная индийская социальная сеть на местных языках) и придуманного Чэнем приложения для гадания FateLeaf.
Каждый раз, когда Наяна что-то покупает, пользуется рекомендацией, просит приложение предсказать судьбу или заводит с кем-то дружбу, Ganesh Insurance получает очередной кусок релевантной информации, и компания использует эти данные, чтобы стать еще более умной и оптимизированной. Это очень похоже на Google, который накапливает о вас очень неплохую базу данных, собирая крохи информации, которые вы случайно «насыпали» в Google, Google Play, Google Maps, Gmail и YouTube.
Потенциально это миллионы признаков, и пусть не все они актуальны и так уж полезны и большая часть имеет весьма скромную прогностическую силу, но даже среди последних глубокое обучение зачастую находит полезные и вполне информативные комбинации, которые между тем совершенно неуловимы и непостижимы для человека.
НЕДОСТАТКИ ГЛУБОКОГО ОБУЧЕНИЯКак известно, любая палка – о двух концах, что уж говорить о мощной технологии. Мы не можем представить себе жизнь без электричества – но соприкосновение с источником тока смертельно опасно. Интернет делает наше существование комфортным – но одновременно мешает нам сосредоточиться. Каковы же недостатки глубокого обучения?
Когда кто-то (ИИ) знает тебя лучше, чем ты сам, – это уже большой риск. Очевидны преимущества ИИ: он может порекомендовать новые полезные продукты быстрее, чем ты их заметишь; присоветовать совместимые варианты романтических партнеров и друзей – исходя из того, что ему известно о твоих нынешних близких. Но у такой осведомленности, безусловно, имеется и обратная сторона.
С вами когда-нибудь бывало такое: садишься посмотреть на YouTube одно видео и застреваешь на три часа? Или проходишь в социальной сети по какой-то более-менее провокационной ссылке, а тебе тут же рекомендуют куда более экстремальный контент?
В киноленте «Социальная дилемма»[22] наглядно показано, как непревзойденные способности ИИ в деле персонификации позволяют ему манипулировать нами, а мы даже не осознаем этого. Звезда фильма Тристан Харрис, президент и соучредитель Центра гуманитарных технологий и специалист по этике технологий, так высказался по этой проблеме: «Тебе и невдомек, что твой клик нацелил суперкомпьютер на твой мозг. Он активировал миллиарды долларов вычислительной мощности, которая очень многому научилась на своем опыте заманивания двух миллиардов человеческих существ снова и снова кликать мышью».
Эта зависимость затягивает нас в порочный круг. Он весьма выгоден крупным интернет-компаниям, будучи своего рода станком для печати денег. Еще в фильме утверждается, что все это зачастую резко сужает мировоззрение, поляризует общество, искажает истину и негативно влияет на настроение и психическое здоровье.
Говоря техническим языком, суть проблемы заключается в простоте целевой функции и в опасности бездумной оптимизации целевой функции по одному критерию, так как это способно привести к вредоносным внешним эффектам. Сегодня ИИ обычно оптимизирует единственный критерий – и чаще всего для того чтобы получить больше (кликов, рекламы, доходов). ИИ маниакально сосредоточен на этой корпоративной цели и ничуть не заботится о благополучии пользователей.
В нашей истории «Золотой слон» Ganesh Insurance обещает потенциальным клиентам минимизировать страховые взносы, что в значительной степени коррелирует с минимизацией выплат по медицинскому страхованию и, следовательно, с улучшением здоровья застрахованных. На первый взгляд это подразумевает совпадение корпоративных целей с целями пользователей.
Однако в рассказе ИИ этой страховой компании определяет, что отношения между Наяной и Сахеджем с большой степенью вероятности приведут к увеличению страхового взноса семьи Наяны, и потому изо всех сил старается помешать их зарождающейся любви.
ИИ Ganesh Insurance предобучен находить причинно-следственные связи. Он может обнаружить повышенный риск заболеваний, связанных с курением, и, следовательно, будет пытаться отвратить человека от этой вредной привычки; и это хорошо. Но, руководствуясь узконаправленным анализом данных, ИИ может заставить приложение увеличить страховые взносы из-за потенциального романтического союза. Таким образом, умозаключения ИИ приводят к действиям, которые разрывают души людей на части и усугубляют неравенство.
Как же решается проблема? Один из первейших подходов – обучить ИИ сложным целевым функциям, таким как снижение страховых взносов с учетом фактора справедливости. Например, Тристан Харрис предлагает использовать в качестве метрики не просто «проведенное в интернете время», а «время, проведенное с толком».
Эти две цели можно объединить в одну сложную целевую функцию. Еще одно решение предложено экспертом в области ИИ Стюартом Расселом: гарантировать полезность каждой целевой функции путем поиска способа включить людей в цикл дизайна таких функций.
Например, можно попытаться построить целевые функции для «большего человеческого блага», такого, например, как счастье, и привлечь людей, чтобы определять, какой смысл они вкладывают в это понятие. (Эту идею мы исследуем подробнее в главе 9 «Остров счастья».)
Однако очевидно: эти идеи требуют дополнительных исследований в области сложных целевых функций и поиска способов количественной оценки таких расплывчатых концепций, как «с толком проведенное время», «справедливость» или «счастье». Более того, реализация этих идей изначально предполагает, что компании станут зарабатывать меньше денег.
Так как же нам стимулировать интернет-гигантов поступать правильно, невзирая на неизбежные финансовые потери? Один из способов – на законодательном уровне ввести нормы, предусматривающие наказание для нарушителей.
Другой путь – поощрять позитивное поведение как часть корпоративной социальной ответственности, например с помощью принципов ESG (environmental, social and corporate governance – экологическое, социальное и корпоративное управление). Сегодня принципы ESG уже набирают обороты в некоторых бизнес-кругах, и не исключено, что ответственный ИИ может стать частью будущей структуры ESG.
А еще можно привлечь третьи стороны и отвести им роль сторожевых псов: создавать информационные панели для основных показателей деятельности компаний и отслеживать такие показатели, как количество генерируемых «фейковых новостей» или «судебных исков с обвинениями в дискриминации», чтобы заставить их включать пропользовательские метрики.
И наконец, возможно, самым сложным, но и самым эффективным решением станет обеспечение стопроцентного совпадения интереса владельца ИИ с интересами каждого пользователя (подробнее об этом утопическом варианте рассказывается в главе 9).
У глубокого обучения есть еще один потенциальный недостаток – предвзятость. Поскольку ИИ основывает свои решения исключительно на данных и оптимизации целевой функции, они часто оказываются более справедливыми, чем решения, принимаемые людьми (на которых чрезмерно влияют всевозможные традиции и предрассудки).
Но ИИ тоже может быть предвзятым. Например, если использованных для обучения ИИ данных недостаточно, и, как следствие, они неверно отражают реальную картину, или данных достаточно, но расовая или гендерная демография в них искажена сторонними факторами. В результате отдел управления персоналом однажды обнаружит, что алгоритмы компании предвзяты к женщинам – потому что в обучающих данных было мало женщин.
Данные могут быть предвзятыми еще и потому, что их собирали в обществе с предрассудками. Так, чат-бот Tay компании Microsoft и алгоритм обработки естественного языка GPT-3 компании OpenAI печально прославились неуместными комментариями о национальных меньшинствах.
Недавние исследования показали, что ИИ способен с высокой степенью точности определять национальную принадлежность людей на основе анализа геометрии лица, тонких черт, структуры кожи и других биометрических характеристик. Но такие способности чреваты риском дискриминации. В рассказе «Золотой слон» примерно так и получилось с Сахеджем – ИИ путем расчетов определил его как далита. Иначе говоря, Сахеджа не назвали «неприкасаемым», но поскольку его данные и характеристики коррелировали с принадлежностью парня к этой касте, Наяну забрасывали предупреждениями. Система ИИ таким образом пыталась разлучить молодых людей.
Это, конечно, непреднамеренная несправедливость, но последствия ее могут быть чрезвычайно серьезными. Если же общество применит некорректные алгоритмы к таким сферам, как принудительная госпитализация или уголовное судопроизводство, ставки окажутся еще выше.
Решение проблем справедливости и предвзятости при использовании ИИ потребует немалых усилий. Некоторые шаги в этом направлении совершенно очевидны и понятны.
Во-первых, компании, использующие ИИ, обязаны информировать общественность, где и с какой целью используются такие системы.
Во-вторых, инженеров по разработке ИИ следует готовить на основе набора стандартных принципов вроде адаптированной клятвы Гиппократа, которую дают врачи; эти специалисты должны понимать, что их профессия подразумевает элемент этики в продуктах, серьезно меняющих жизнь людей, и, следовательно, они должны поклясться защищать права пользователей.
В-третьих, необходимо ввести тщательное тестирование всех ИИ-продуктов; оно должно быть встроено в инструменты обучения ИИ и заблаговременно предупреждать о моделях, обученных на данных с несправедливым демографическим охватом. В противном случае использование ИИ-продукта должно быть запрещено.
В-четвертых, можно принять новые законы, требующие аудита ИИ. Скажем, если на компанию поступает определенное количество жалоб, ей следует обязать пройти такой аудит (на предмет справедливости, раскрытия информации и защиты конфиденциальности) – точно так же, как фирма подпадает под налоговую проверку, если ее бухгалтерская отчетность выглядит подозрительно.
И, наконец, последняя проблема глубокого обучения – объяснения и обоснования. Люди всегда могут растолковать, почему они приняли то или иное решение – оно основано на в высшей степени конкретном опыте и правилах.
Но решения глубокого обучения базируются на сложных уравнениях с тысячами функций и миллионами параметров. «Резоном» для глубокого обучения, по сути, является многомерное уравнение, полученное на основе больших объемов данных. И вряд ли возможно как следует объяснить его людям – оно слишком сложно. Тем не менее многие ключевые решения ИИ должны сопровождаться объяснением причин – либо по закону, либо потому, что этого ожидают пользователи.
Поэтому в настоящее время проводится множество исследований, направленных на увеличение «прозрачности» ИИ, – либо путем резюмирования его сложной логики, либо посредством введения новых ИИ-алгоритмов, которые изначально проще интерпретировать.
Описанные выше недостатки и ограничения глубокого обучения привели к тому, что в обществе появилось серьезное недоверие к ИИ. Но ведь все новые технологии имели свои недостатки. История показывает, что со временем многие ранние ошибки удается исправить, а технологии – усовершенствовать.
Возьмем для примера предохранитель в любой электрической сети. Он оберегает людей от поражения током, а имущество – от пожара. Или антивирусные программы – они защищают от компьютерных вирусов. Я уверен, со временем появятся технологии и политические решения и для проблем, связанных с негативным влиянием ИИ, с предвзятостью и непрозрачностью его работы.
Но сначала нам придется пойти по стопам Наяны и Сахеджа и сообщить людям о серьезности проблем, а уж затем мобилизовать человечество на поиск их решений.
Глава 2. Боги под масками
И правда, и утро со временем проясняются.
Африканская пословицаРАССКАЗ ПЕРЕВЕДЕН ЭМИЛИ ДЖИНПримечание Кай-Фу: В этой истории рассказывается о молодом нигерийском видеопродюсере, которого наняли для создания серьезного дипфейка[23]. Одним из основных направлений ИИ является так называемое компьютерное зрение – оно учит машины «видеть», и недавние прорывы в этой сфере позволяют получать невиданные доселе результаты. Этот рассказ – фантазия о мире будущего, характерной чертой которого стали беспрецедентные высокотехнологические игры в стиле «кошки-мышки» между мошенниками и их разоблачителями; между преступниками и потенциальными жертвами. Можем ли мы избежать такого мира, в котором все визуальные линии размыты и нечетки? Я исследую этот вопрос в своем комментарии: я опишу недавние и предстоящие открытия в области компьютерного зрения, биометрии и безопасности ИИ – трех технологических сферах, которые позволяют создавать подделки-дипфейки и другие подобные технологии.
Поезд наземного метро подтягивался к станции Яба, и Амака нажал кнопку открытия дверей. Они с визгом разъехались; парень, не дожидаясь полной остановки, спрыгнул на перрон. Он больше не мог вынести в этом черепашьем поезде, в его спертом воздухе, ни одного мгновения. Почти прижавшись к какому-то пожилому мужчине, Амака ловко проскользнул через турникет на выходе из вокзала – он опять проехался зайцем.
Система распознавания лиц автоматически списывала стоимость проезда со счета каждого проходящего мимо камер человека. Но Амака был в маске – камеры его не увидели, и он опять прокатился бесплатно.
Маски давно стали обычным аксессуаром для молодежи Лагоса[24]. Для их родителей они были скорее ритуальными атрибутами, но для молодых людей, которых в последние десятилетия заметно прибавилось, маски стали модным трендом, а заодно и средством обмана камер наблюдения.
В Лагосе, крупнейшем городе Западной Африки, жило примерно от 27 до 33 миллионов человек – каждый метод подсчета давал свою цифру. Пять лет назад государство строго ограничило число приезжих, считая мигрантами даже тех, кто родился в других частях Нигерии. И странствующим мечтателям вроде Амаки пришлось постоянно находиться в состоянии поиска убежища – организовывать пристанище в нелегальных квартирах, в общежитиях, на рынках, на автобусных станциях или даже под эстакадами.
Конец ознакомительного фрагмента.
Текст предоставлен ООО «Литрес».
Прочитайте эту книгу целиком, купив полную легальную версию на Литрес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.
Notes
1
Дартмутский летний исследовательский проект по искусственному интеллекту (1956) – основополагающее событие в области ИИ как научной области. Прим. ред.
2
Британская компания, занимается искусственным интеллектом. Основана в Лондоне в 2010 году под названием DeepMind Technologies; в 2014-м приобретена Google. Прим. ред.
3
На момент этого матча Ли Седоль занимал 2-е место по количеству выигранных чемпионатов мира; считался 4-м игроком го в мире (официального рейтинга нет). Прим. ред.
4
Продолжение популярной игры DotA; киберспортивная дисциплина с миллионными призовыми фондами профессиональных турниров. Прим. ред.
