


Полная версия
See Section 2.6
Data provisioning tools
Tools for the provisioning of data (e.g. SAP Data Services, Kafka, etc.)
See Section 2.4
SAP BW/4HANA
SAP data warehousing component running only on SAP HANA
See Section 2.3
Around SAP HANA BI architectures
SAP S/4HANA
New operational system for different Lines of Business optimized for SAP HANA
See Section 2.2
SAPS/4HANA Embedded Analytics
Operational reporting component for S/4HANA modules only
See Section 2.2
SAP HANA dynamic tiering
Support of the data temperature concept including storage via Big Data
https://blogs.sap.com/2018/04/18/whats-new-sap-hana-dynamic-tiering-2.0-sp-03
SAP Edge Services
Internet of Things (IoT) data collection at the point of creation instead of at a central SAP HANA server
https://www.sap.com/products/edge-services.html
SAP HANA Data Warehousing Foundation
Manage data and memory efficiently across the application landscape
https://blogs.sap.com/2015/03/04/sap-hana-data-warehousing-foundation/
SAP HANA real-time replication
Real-time replication based on the SAP Landscape Transformation Replication Server (SLT)
https://blogs.sap.com/2017/02/01/sap-hana-2.0-editions-and-options-by-the-sap-hana-academy/
SAP Business Suite on HANA
SAP modules running on SAP HANA, not yet on S/4HANA
https://blogs.saphana.com/2014/08/29/the-benefits-of-the-business-suite-on-hana/
Change and Transport System (CTS+) and SAP HANA Transport for ABAP (HTA)
Transport of SAP HANA and ABAP managed objects
A useful guide for these tools can be found here:
https://blogs.sap.com/2015/06/11/cts-or-hta/
Intelligent Enterprise
SAP HANA Analytics plays an essential role, achieving an effective use of data throughout the enterprise
https://www.sap.com/products/intelligent-enterprise.html
Before looking into each component, we will first introduce a high-level view of our reference architecture that is further detailed in Chapter 3. Following this layer architecture, we will look at the essential building blocks of an SAP-centric BI landscape in today’s world (Figure 2.1).
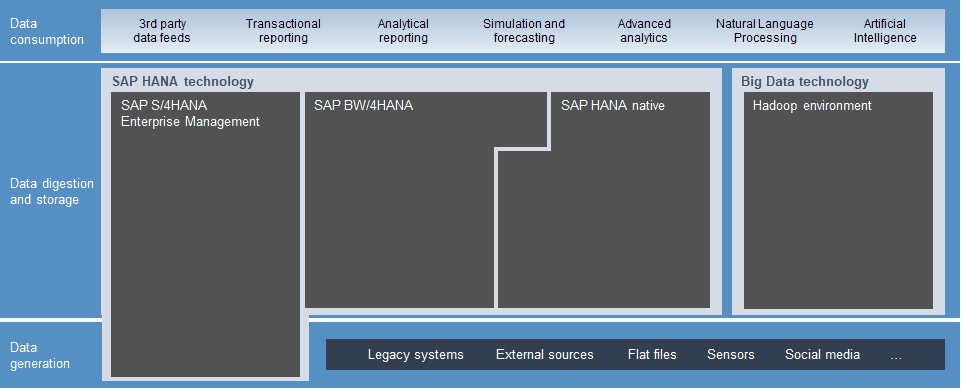
Figure 2.1: Reference layers of a BI landscape
Data generation is the sourcing layer of all data we plan to process in our BI landscape. Looking at the SAP world, SAP S/4HANA is a good example of this. In the data digestion and storage layer, data is processed, pre-calculated and stored for further use. SAP BW/4HANA, SAP HANA native or Big Data technologies provide significant features to implement this layer. Last, but not least, data consumption gives access to the data processed in the previous layers.
2.1 SAP HANA functionalities
This section introduces the SAP HANA related add-ons and features that are the most relevant for designing an SAP HANA-based BI architecture. This specifically excludes data provisioning tools, analytical tools and frontends, which are discussed separately in the following sections.
2.1.1 SAP HANA 2.0
In December 2016, SAP released SAP HANA 2.0—the digital foundation to build the next-generation of analytics applications. In the following section, we highlight selected innovations and new features of this version.
First, let’s start with the migration path. With SAP HANA 1.0 SPS 10 or higher, an upgrade to SAP HANA 2.0 SPS 00 can be performed directly. When migrating from SPS 12, you can test SAP HANA 2.0 SPS 00 with the capture and replay function before migrating. If you run SAP HANA 1.0 SPS 9 or older, you need to upgrade to SAP HANA 1.0 SPS 12 first.
One of the new features in SAP HANA 2.0 is the Active/Active (read-enabled) option, where a secondary SAP HANA system (which is synchronized with the primary through logs) is utilized to take over read-intensive processes. Whereas read and write operations are executed only on the primary SAP HANA system, the second one acts autonomously in answering queries (read operations).
Active/Active (read-enabled) option—SAP S/4HANA case

Furthermore, and especially against the background of General Data Protection Regulation (GDPR) in Europe, data security and authorization management (e.g. on LDAP groups) has improved. New encryption features have been released (e.g. full native data at rest encryption, enhanced encryption key management).
Workload management helps SAP HANA 2.0 to better avoid system-overload situations. Requests can be automatically rejected from the database when a threshold is exceeded.
With regard to data integration features, the Smart data integration (SDI), Smart data quality, and Smart data access components have been enhanced. For instance, SDI now allows virtual procedures (e.g. via BAPI) to perform read/write operations with ABAP-based systems.
In the streaming area, messages are now guaranteed via REST interface. In a real-time analysis scenario, data delivery is now ensured. New adaptors like oDATA and JSON enable greater flexibility.
Regarding administration, SAP HANA Cockpit has been re-architected and now also supports on-premise and cloud implementations. Database management has been unified.
There are many other changes and features available with SAP HANA SPS 00; for example, new solutions, improvements, and component reforms relating to Workload Capture and Replay, Backup and Recovery, SAP Enterprise Architecture Designer (Edition for SAP HANA), Dynamic Tiering, Predictive Analytics Library, High Availability and the SAP HANA Extended Application Services (see also Section 2.1.3).
SAP HANA 2.0 features
New support packages and stacks (SPS) for SAP HANA 2.0 are released twice a year, and the latest information and updates are available at: https://www.sap.com/products/hana/features/whats-new.html.
2.1.2 SAP HANA engines
The engines within SAP HANA build the foundation for any application running on the SAP HANA platform. The development of the SAP HANA engines started with the first SAP HANA revision and continuously evolved during further revisions. SAP HANA started out with the following engines: join, calculation, SQL, Online Analytical Processing (OLAP), row, column and XS. The importance of these engines, as well as the engines themselves, has gradually changed. From a definition perspective, it is hard to say what exactly constitutes an engine. When reading different lists of the SAP HANA platform features, further engines are mentioned. These include the spatial, the graph, and the planning engines; and depending on the definition of “engine”, we could even say there is a “predictive” engine. We will take a closer look at the SQL engine in the following section. Further detail about the predictive and spatial options can be found in Section 2.4.
The SAP HANA engines
Important functionalities of SAP HANA are the modeling of views, the execution of SQL statements within the database for checking results, and the ability to write more complex programming logic. In these cases, the SQL engine is utilized.
First, we need to take a step back and have a quick look at SAP HANA views. SAP started out by distinguishing attribute, analytical and calculation views in the first Service Packs. In the last two years, we have noticed a clear movement towards using only calculation and scripted SQL views. In addition, SAP has not only been promoting the use of Core Data Services (CDS) views to the customer, but has also been promising to build future extractors and embedded analytics for S/4HANA based on CDS views.
CDS views, like calculation views, are based on SQL. Due to this development, we believe that the SQL engine should be explained in more detail here.
So how does the SQL engine work? The SQL engine does not simply take SQL code and query the referenced objects within it. It combines the statements and optimizes them so that, at the end, one large query is run which has ideally been compiled into a high-performing statement. This enables the author of SQL statements to design easily readable code or views while not having to constantly think about performance. However, be aware that this will not always work, and testing with PlanViz (Plan Visualization) is a mandatory task you need to perform.
PlanViz is an SAP HANA-based tool for analyzing and visualizing the performance and execution structure of queries.
SQL Engine
2.1.3 SAP HANA Extended Application Services Advanced (XSA)
The previously-mentioned XS engine has undergone a change with Service Pack 11 and is now known as the XSA engine. The “A” in the XSA stands for “advanced”, and means that the XS engine has now completely switched its code basis and also changed ownership within SAP. Previously, the XS engine only supported JavaScript coding and oData (a data exchange protocol developed by Microsoft). The XS engine could therefore be seen as a lightweight webserver. With the switch to XSA, node.js, Java and C++ coding are now also supported. In this way, the SAP HANA platform has been enhanced and has made the XSA engine a more heavyweight webserver.
SAP HANA 2 BYOL
Figure 2.2 depicts the XSA engine and its surrounding components. As the figure shows, the main components necessary to build a web application are as follows:
A database is needed to store data and to execute changes to the data as requested by the application.
The web application itself needs to be coded. This can be done in any language supplied by the XSA engine. Another possibility involves connecting a different webserver and using HANA only as the database.
The third and final component is the presentation logic. The borders between control flow and presentation can be very fluid; for example, if you decide to build the web page using traditional client-side JavaScript (XSJS) and SAPUI5, then the code is executed on the client side and only the data exchange between client and server is handled via oData services. A second option consists of only using input from the client side, creating the webpage in HTML5 code, and implementing the more complex application logic on the server side.
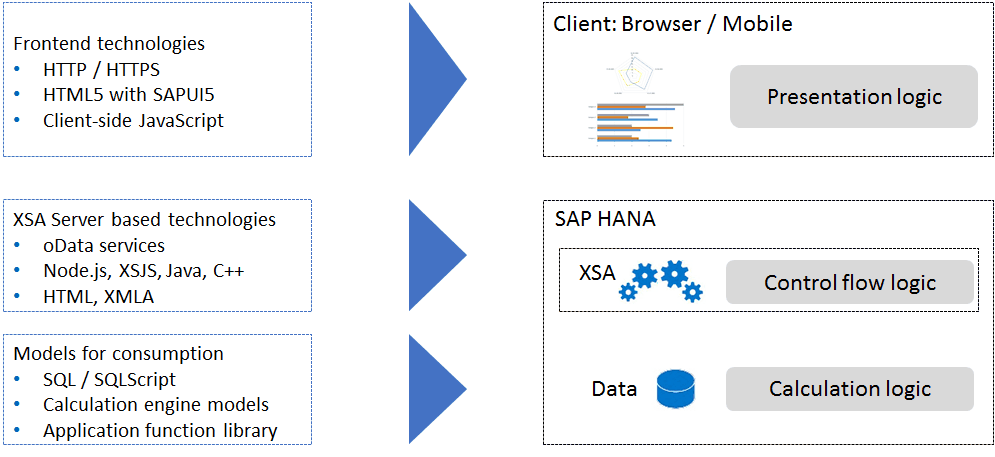
Figure 2.2: The SAP HANA XSA architecture foundation