


Полная версия
Основы программирования в СУБД Oracle. SQL+PL/SQL.
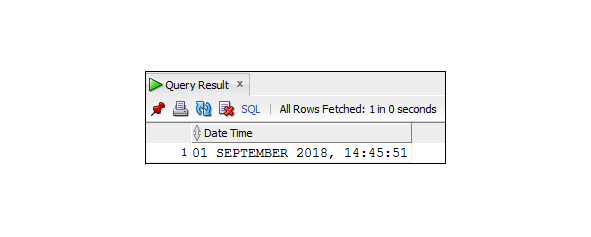
′DD-MON-YYYY HH24:MI: SS′),′DD MONTH YYYY, HH24:MI: SS′)
As Date_Time
FROM DUAL
Использование формата RR
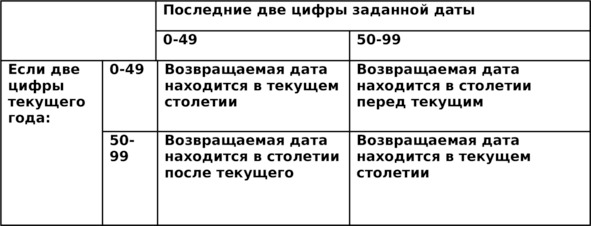
Этот формат связан с проблемой 2000 года. Определяет год, если в дате заданы две последние цифры года. Если две последние цифры лежат в диапазоне от 0 до 49, то год принадлежит текущему столетию. Если две последние цифры лежат в диапазоне от 50 до 99, то год принадлежит предыдущему столетию.
TO_DATE (′04-JUL-18′, ′DD-MON-RR′) → 04/JUL/2018
TO_DATE (′04-JUL-75′, ′DD-MON-RR′) → 04/JUL/1975
Более полная информация о правилах использования формата RR приведена в таблице 3.8.
Таблица. 3.8. Правила преобразования года в формате RR
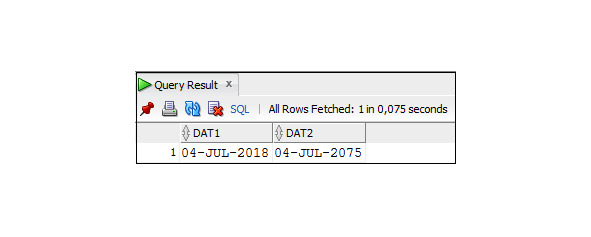
При использовании формата YY первые две цифры всегда соответствуют текущему столетию. Совет: при работе с датами всегда указывайте четыре цифры года.
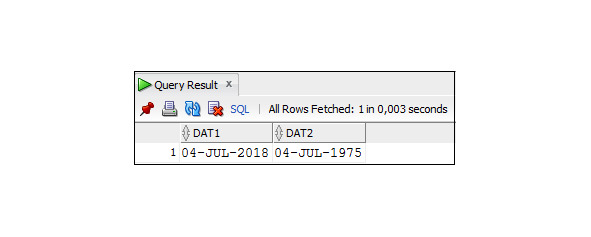
Пример 3.39. Использование формата RR при вводе двузначного значения года
SELECT TO_CHAR (TO_DATE
(′04-07-18′, ′DD-MM-RR′),′DD-MON-YYYY′) As DAT1,
TO_CHAR (TO_DATE (′04-07-75′, ′DD-MM-RR′),′DD-MON-YYYY′)
As DAT2
FROM DUAL;
Пример 3.40. Использование формата YY при вводе двузначного значения года
SELECT TO_CHAR (TO_DATE (′04-07-18′, ′DD-MM-YY′),
′DD-MON-YYYY′) As DAT1,
TO_CHAR (TO_DATE (′04-07-75′, ′DD-MM-YY′),
′DD-MON-YYYY′) As DAT2
FROM DUAL;
Преобразование даты в строку символов
Это преобразование выполняется для того, чтобы отобразить значение, имеющее тип Date в требуемом виде. Для осуществления этого преобразования используется функция:
TO_CHAR (х, {маска преобразования})
где: x – значение, имеющее тип Date, а строка {маска преобразования}) – маска, которая определяет, как нужно отобразить значение x; может содержать те же элементы, которые были определены для функции TO_DATE.
Пример 3.41. Использование функции TO_CHAR для преобразования значения, имеющего тип Date, в строку символов
SELECT TO_CHAR (SYSDATE, ′ DD/MM/YYYY′) AS RESULT1,
TO_CHAR (SYSDATE, ′ DD MON, YYYY′) AS RESULT2,
TO_CHAR (SYSDATE, ′ DD DAY MONTH, YYYY′) AS RESULT3,
TO_CHAR (SYSDATE, ′ DD – MONTH -YYYY, HH24:MI: SS′)
AS RESULT4
FROM DUAL;
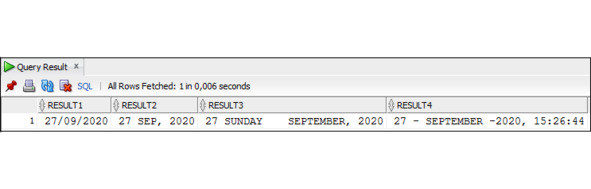
Используя функцию TO_CHAR при работе с данными, имеющими тип Date, можно выделить определенную часть даты: день, месяц, год.
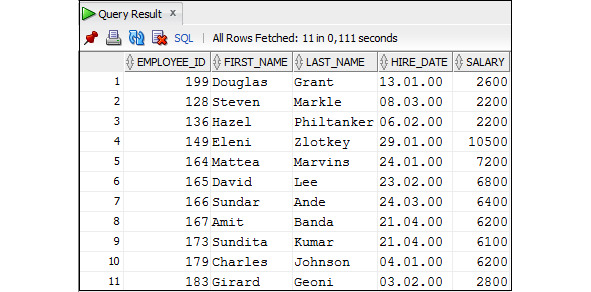
Пример 3.42. Вывести данные о сотрудниках, которые были приняты на работу в 2000 году
SELECT employee_id, first_name, last_name, hire_date, salary
FROM Employees
WHERE TO_CHAR (hire_date, ′YYYY′) = ′2000′;
Работа с неопределенными значениями
Если при вводе новой строки в таблицу столбцу не будет присвоено значение, то этот столбец будет иметь значение NULL – не определено. Это может происходить по двум основным причинам. Первая причина: в момент ввода строки значение столбца неизвестно, в этом случае значение будет присвоено позже. Вторая причина: значение не может быть присвоено исходя из правил предметной области. Для рассматриваемой базы данных вторую причину можно пояснить на примере столбца commission_pct таблицы Employees. Некоторым сотрудникам полагаются комиссионные, столбец commission_pct содержит значение комиссионных. Зарплата таких сотрудников рассчитывается по формуле: Salary * (1 + commission_pct). У сотрудников, которым комиссионные не полагаются, значение столбца commission_pct не может быть определено.
При работе с арифметическими и логическими выражениями следует иметь в виду следующее: арифметическое выражение вернет значение NULL, если один или несколько операндов будут иметь значение NULL; результатом операции сравнения будет NULL, если один или оба операнда будут иметь значение NULL.
Результат логических операций AND и OR приведен в таблицах 3.9 и 3.10 соответственно.
Таблица 3.9. Таблица истинности логической функции AND с учетом значений NULL

Таблица 3.10. Таблица истинности логической функции OR с учетом значений NULL

Для корректной обработки данных, которые могут иметь значения NULL, следует использовать специальные функции.
Функция NVL
Позволяет заменить значение NULL фактическим значением. Синтаксис:
NVL (x,y)
Возвращает x, если x не NUUL, и возвращает y, если x имеет значение NUUL, например: NVL (commission_pct,0).
Рассмотрим примеры использования функции NVL при решении конкретных задач.
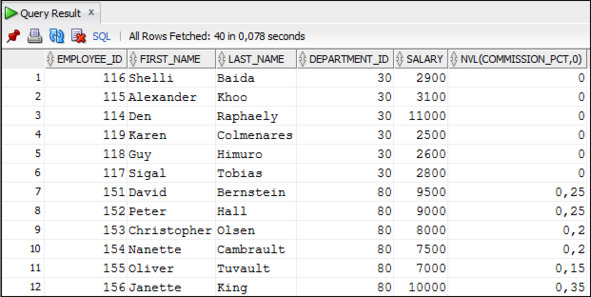
Пример 3.43. Вывести данные о сотрудниках, включая размер комиссионных, которые работают в отделах 30 и 80
SELECT employee_id, first_name, last_name, department_id,
salary, NVL (commission_pct,0)
FROM Employees
WHERE department_id IN (30,80)
ORDER BY department_id;
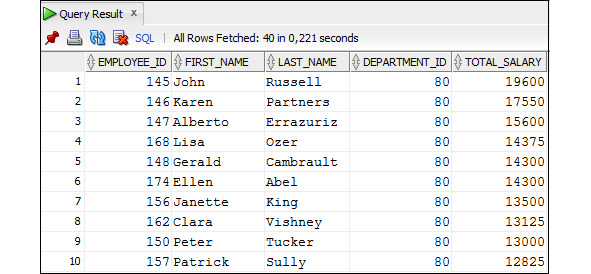
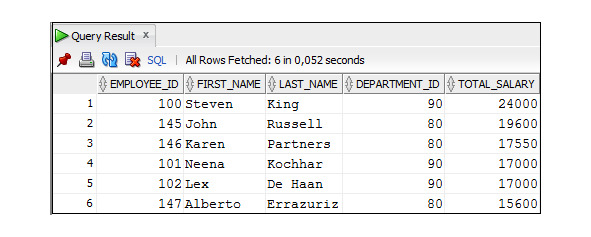
Пример 3.44. Вывести данные о сотрудниках, включая зарплату с учетом комиссионных (полная зарплата), которые работают в отделах 30 и 80, упорядочив их в порядке убывания значений зарплаты с учетом комиссионных
SELECT employee_id, first_name, last_name, department_id,
salary* (1+NVL (commission_pct,0)) AS total_salary
FROM Employees
WHERE department_id IN (30,80)
ORDER BY total_salary DESC;
Псевдонимы столбцов можно использовать в предложении ORDER BY, но нельзя использовать в предложении WHERE.
Пример 3.45. Вывести данные о сотрудниках, включая зарплату с учетом комиссионных, полная зарплата которых больше 15 000, упорядочив их в порядке убывания значений полной зарплаты
SELECT employee_id, first_name, last_name, department_id,
salary* (1+NVL (commission_pct,0)) AS total_salary
FROM Employees
WHERE total_salary> 15000
ORDER BY total_salary DESC;
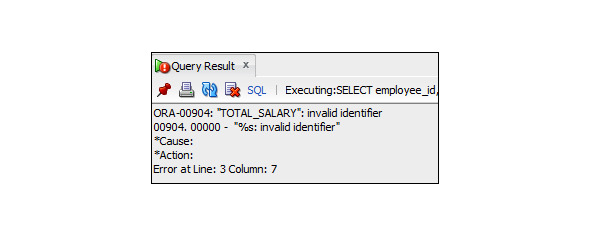
Правильный вариант решения задачи 3.45:
SELECT employee_id, first_name, last_name, department_id,
salary* (1+NVL (commission_pct,0)) AS total_salary
FROM Employees
WHERE salary* (1+NVL (commission_pct,0))> 15000
ORDER BY total_salary DESC;
Функция NVL2
Расширяет возможности функции NVL. Синтаксис:
NVL2 (x,y1,y2)
Возвращает y1, если x не NUUL, и возвращает y2, если x имеет значение NUUL.
Например:
NVL2 (commission_pct, salary* (1+commission_pct), salary)
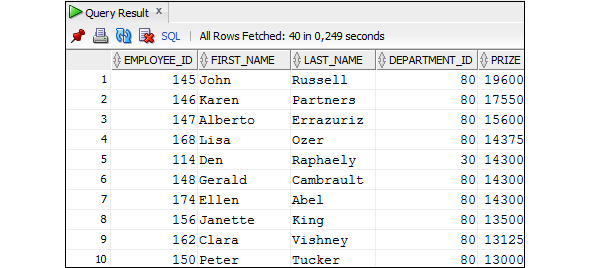
Пример 3.46. Вывести данные о сотрудниках, которые работают в отделах 30 и 80, размере премии, которую они должны получить. Размер премии, у сотрудников, которые получают комиссионные, равен зарплате с учетом комиссионных. Размер премии, у сотрудников, которые не получают комиссионные, равен зарплате, увеличенной на 30%
SELECT employee_id, first_name, last_name, department_id,
NVL2 (commission_pct, salary* (1+commission_pct), salary*1.3)
AS prize
FROM Employees
WHERE department_id IN (30,80)
ORDER BY prize DESC;
Функция COALESCE
Предназначена для обработки значений NULL и предоставляет более широкие возможности, чем функции NVL и NVL2. Позволяет отрабатывать несколько значений NULL. Синтаксис:
COALESCE (y1,y2,…yn)
Возвращает первое не NULL значение.
Для того чтобы продемонстрировать возможности этой функции, рассмотрим следующую задачу. Предположим, что таблица Employees имеет еще один столбец bonus. Значение этого столбца равно некоторой фиксированной сумме, которая должна быть прибавлена к зарплате сотрудника, может иметь значение NULL. С учетом столбца bonus зарплата сотрудников равна:
– bonus + salary * (1 + commission_pct) – если сотруднику положен бонус и он получает комиссионные;
– bonus + salary – если сотруднику положен бонус, но он не получает комиссионные;
– salary * (1 + commission_pct) – если сотруднику не положен бонус, но он получает комиссионные;
– salary – если сотруднику не положен бонус и он не получает комиссионные.
Используя функцию COALESCE, это правило начисления зарплаты можно реализовать следующим образом.
Пример 3.47. Вывести данные о сотрудниках и их полную зарплату, которая включает комиссионные и бонус
SELECT employee_id, first_name, last_name, department_id,
COALESCE (bonus + salary* (1+commission_pct),
bonus + salary, salary* (1+commission_pct), salary)
AS total_salary
FROM Employees
ORDER BY total_salary DESC;
Условные выражения
Довольно часто значение столбца, которое должен вернуть SQL-запрос, зависит от условий, которые нужно проверять для каждой строки. Для реализации подобного выбора используются выражение CASE и функция DECODE. Используя CASE и DECODE, можно реализовать условную логику if-then-else в операторе SELECT. Выражение CASE соответствует стандарту ANSI SQL, а функция DECODE специфична для Oracle.
Выражение CASE
Практически во всех современных языках программирования используется выражение CASE. Есть два варианта выражения CASE:
– выражение CASE с параметром;
– выражение CASE с условием.
Выражение CASE с параметром имеет следующий синтаксис:
CASE {параметр}
– WHEN {значение1} THEN {результат1}
– [WHEN {значение2} THEN {результат2}
– …
– WHEN {значениеN} THEN {результатN}]
– [ELSE {результат_ELSE}]
END;
Выражение CASE выполняется следующим образом: сравниваются значение {параметр} со значениями {значение i} в предложениях WHEN и возвращает результат {результатi} первого предложения, в котором будет выполнено условие {параметр} = {значениеi}.
Следует иметь в виду, что Oracle не оценивает остальные предложения WHEN. Если ни в одном из предложений WHEN не выполняется условие {параметр} = {значениеi}, то возвращается значение {результат_ELSE}. Если предложение ELSE отсутствует, то выражение CASE вернет результат NULL.
Возвращаемый результат может быть значением или выражением. Выражения {параметр} и {значение1} должны иметь один и тот же тип данных. Все возвращаемые значения {результат2} должны иметь одинаковый тип данных.
Примечание. Выражение CASE может содержать другие выражения CASE. Единственным ограничением является то, что одно выражение CASE может иметь максимум 255 условных выражений.
Пример 3.48. Вывести данные о сотрудниках и размере их премии, которая задана в виде фиксированной суммы, размер которой зависит от отдела, где работает сотрудник

Пример 3.49. Вывести данные о сотрудниках и размере их премии, которая задана как часть заработной платы, размер которой зависит от отдела, где работает сотрудник

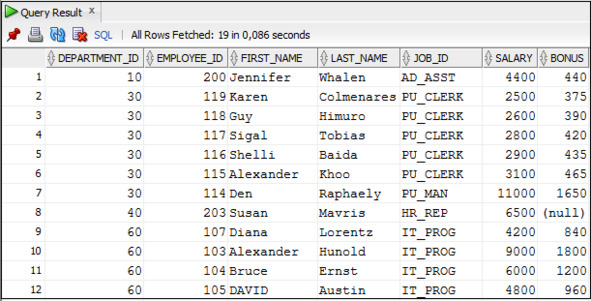
В этом примере отсутствует предложение ELSE, поэтому размер премии для сотрудников отделов, номеров которых нет в предложениях WHERE, имеет значение NULL.
Размер премии может зависеть как от отдела, в котором работает сотрудник, так и от его должности. Для решения этой задачи необходимо использовать вложенные выражения CASE.
Пример 3.50. Вывести данные о сотрудниках и размере их премии, которая зависит как от отдела, где работает сотрудник, так и от его должности.

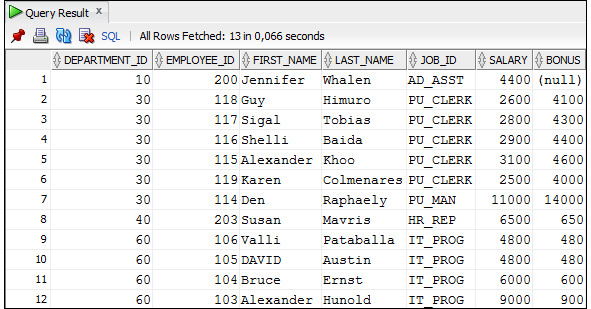
Выражение CASE с условием имеет следующий синтаксис:
CASE
WHEN {условие1} THEN {результат1}
[WHEN {условие2} THEN {результат2}
…
WHEN {условиеN} THEN {результатN}]
[ELSE {результат_ELSE}]
END
При использовании этой разновидности оператора CASE последовательно поверяются значения условных выражений в предложениях WHEN и возвращается результат из первого предложения, в котором это выражение будет иметь значение TRUE.
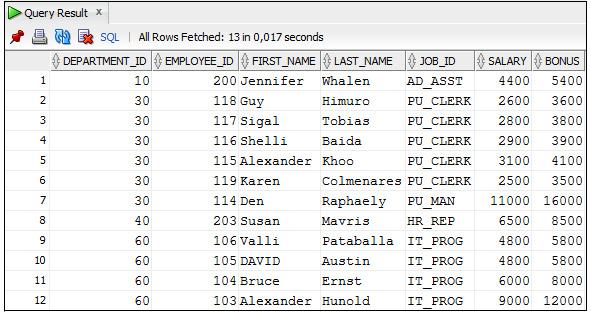
Пример 3.51. Вывести данные о сотрудниках и размере их премии, которая зависит от зарплаты сотрудника

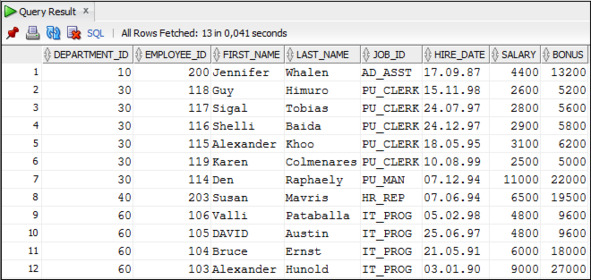
Пример 3.52. Вывести данные о сотрудниках и размере их премии, которая зависит от количества лет, которые проработал сотрудник

Функция DECODE
По своему назначению функция DECODE аналогична условному выражению CASE, но не поддерживается стандартом ANSI/ISO SQL. Синтаксис:
DECODE ({столбец} | {выражение}
{, {значение 1}, {результат 1}
[, {значение 2}, {результат2}
…
[, {значение N}, {результат N}]
[, {результат default}]);
Значение {столбец} | {выражение} сравнивается со значениями {значение i} и возвращается результат первого совпадения.
Если совпадения не будет, то возвращается значение {результат default}. Если {результат default} отсутствует, то функция DECODE вернет результат NULL.
Следует обратить внимание на то, что функция DECODE требует точного совпадения значений и не позволяет использовать операции сравнения>, <и сложные условия. Поэтому возможности функции DECODE уступают возможностям условного выражения CASE.
Пример 3.53. Вывести данные о сотрудниках и размер их премии, которая задана в виде фиксированной суммы, размер которой зависит от отдела, в котором работает сотрудник
SELECT department_id, employee_id, first_name, last_name,
job_id, salary,
DECODE (department_id, 10, 1000,30, 1200,60, 1500,500)
AS bonus
FROM Employees
WHERE department_id in (10,30,40,60,100)
ORDER BY department_id;
Результат выполнения этого запроса совпадает с результатом выполнения запроса из примера 3.50.
Рассмотрим еще один пример использования функции DECODE для решения задачи из примера 3.53. Особенностью этой задачи является использование операции сравнения>, которую нельзя использовать в DECODE. Но при решении этой задачи данное ограничение удается обойти. Обратите внимание на то, что число месяцев, которые проработал сотрудник, делится на 60, что соответствует пяти годам работы. Если целая часть результата равна пяти, то это означает что сотрудник проработал не менее 25, но не более 30. Последнее замечание означает, что запросы из примеров 3.53 и 3.55 не эквивалентны и запрос с использованием функции DECODE требует расширения списка значений.
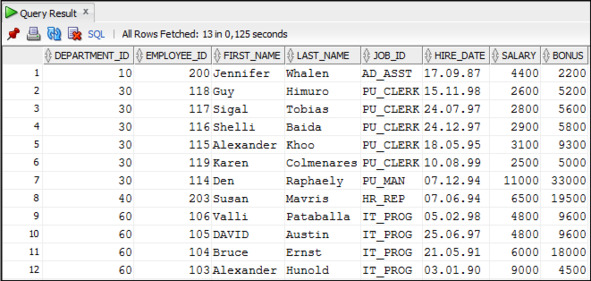
Пример 3.54. Вывести данные о сотрудниках и размере их премии, которая зависит от количества лет, которые проработал сотрудник, используя функцию DECODE
SELECT department_id, employee_id, first_name, last_name, job_id,
hire_date, salary,
DECODE (TRUNC (MONTHS_BETWEEN (SYSDATE, hire_date) /60),
6,3*salary,
5,3*salary,
4, 2*salary,
3, salary,
0.5*salary) As bonus
FROM Employees
WHERE department_id IN (10,30,40,60)
ORDER BY department_id;
Задачи для самостоятельного решения
1. Вывести значения столбцов employee_id, first_name, last_name и значение зарплаты, увеличенное на 25%. Увеличенное значение зарплаты округлить до сотен.
2. Вывести значения столбцов employee_id, first_name, last_name, salary и ту часть зарплаты сотрудника, которая меньше 1000.
3. Создать запрос, который вернет столбец name_and_salaries. Столбец должен содержать полное имя сотрудника, зарплату и несколько звездочек (*) – по одной звездочке на каждые $1000 зарплаты.
4. Вывести данные о товарах, название которых содержит слово AMD и не содержит слова RYZEN.
5. Вывести названия товаров, второе слово которых состоит из шести букв.
6. Вывести данные о товарах, второе слово в названии которых – — iPhone.
7. Вывести данные о сотрудниках, которые были приняты на работу в понедельник.
8. Вывести данные о сотрудниках, которые были приняты на работу 21 апреля.
9. Для сотрудников, работающих в отделе 50, вывести разницу между текущей датой и датой приема на работу в формате: УУ лет ММ месяцев ДД дней.
10. Вывести значения столбцов employee_id, first_name, last_name, salary и премию, которую они должны получить. Размер премии у сотрудников, которые получают комиссионные, равен зарплате с учетом комиссионных. Размер премии у сотрудников, которые не получают комиссионные, равен зарплате, увеличенной на 30%.
11. Вывести значения столбцов employee_id, first_name, last_name, salary и bonus – премию, которую они должны получить. Размер премии зависит от рейтинга и вычисляется по следующему правилу:
– если рейтинг сотрудника равен 5, то bonus = salary * 1.5;
– если рейтинг сотрудника равен 4, то bonus = salary * 1.3;
– если рейтинг сотрудника равен 3, то bonus = salary * 1.1;
– сотрудникам, рейтинг которых меньше 3, премия не полагается.
12. Вывести значения столбцов employee_id, first_name, last_name, salary и category. Значение категории (category) определяется по следующему правилу:
– если rating_e ≥ 4 и salary ≥ 10 000, то category = ′High′;
– если rating_e <3 и salary <5000, то category = ′Low′;
– у остальных сотрудников category = ′Middle′.
Глава 4. Агрегатные функции и группировка данных
Агрегатные функции
В отличие от однострочных функций, агрегатные функции обрабатывают группу строк и возвращают один результат для группы. Группа строк может включать как всю таблицу, так и ее часть.
Таблица 4.1. Агрегатные функции
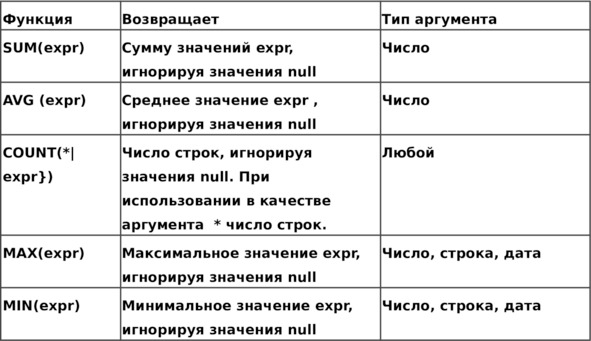
Синтаксис агрегатных функций:
{имя функции} ({Аргумент})
где: expr – аргумент агрегатной функции, который может содержать следующие элементы:
[DISTINCT] {имя столбца} | {выражение} | {однострочная функция}
Следует обратить внимание на то, что аргументом групповой функции может быть однострочная функция. Хотя стандарт языка SQL запрещает использование агрегатных функций в качестве аргумента агрегатных функций, СУБД Oracle допускает это, но только на один уровень в глубину и только в предложении SELECT. Рассмотрим примеры использования агрегатных функций.
Пример 4.1. Вывод обобщенных данных о зарплате сотрудников
SELECT MIN (salary) AS minimum, MAX (salary) AS maximum, ROUND (AVG (salary)) AS medium, SUM (salary) As summa, COUNT (salary), COUNT (*)
FROM Employees;
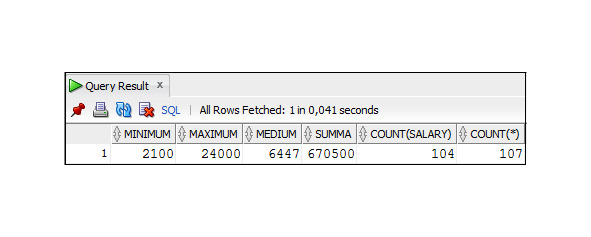
В полученном результате следует обратить внимание на то, что:
– COUNT (salary) возвращает число сотрудников, получающих зарплату, у которых значение столбца salary не NULL;
– COUNT (*) возвращает число всех сотрудников.
Этот запрос не учитывает то, что некоторые сотрудники получают комиссионные. Зарплата сотрудника с учетом комиссионных может быть вычислена путем использования выражения:
salary * (1 + NVL (commission_pct,0))
Используя это выражение в предыдущем запросе, вместо столбца salary получим:
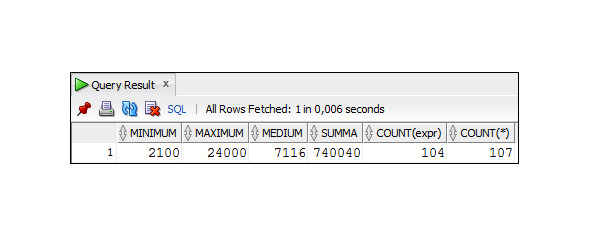
Пример 4.2. Вывод обобщенных данных о зарплате сотрудников с учетом комиссионных
SELECT MIN (salary* (1+NVL (commission_pct,0))) AS minimum,
MAX (salary* (1+NVL (commission_pct,0))) AS maximum,
ROUND (AVG (salary* (1+NVL (commission_pct,0)))) AS medium,
SUM (salary* (1+NVL (commission_pct,0))) As summa,
COUNT (salary* (1+NVL (commission_pct,0))) AS ′′COUNT (expr) ′′,
COUNT (*)
FROM Employees;
Пример 4.3. Использование функции COUNT
SELECT COUNT (*), COUNT (salary),COUNT (DISTINCT salary),
COUNT (commission_pct)
FROM Employees
WHERE department_id =80;
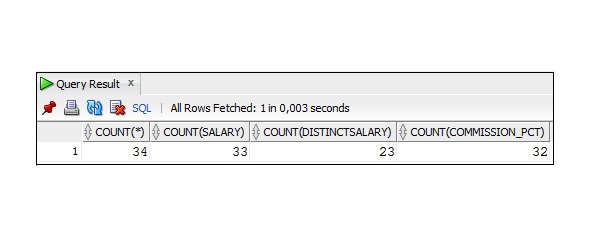
Анализ результатов этого запроса:
– COUNT (*) – вернула число сотрудников в отделе 80;
– COUNT (salary) – вернула число сотрудников в отделе 80,
у которых значение столбца salary не NULL;
– COUNT (DISTINCT salary) – вернула число различных значений в столбце salary;
– COUNT (commission_pct) – вернула число сотрудников в отделе 80, у которых значение столбца commission_pct не NULL.