


Полная версия
Внедрение искусственного интеллекта в бизнес-практику. Преимущества и сложности
Само собой, другую серьезную угрозу представляют прорывные стартапы. Как я уже заметил, активнее всего ИИ внедряют такие онлайн-гиганты, как Google, Amazon и Facebook. Мы наблюдаем, как эти ориентированные на данные компании входят в различные отрасли и бросают вызов традиционным лидерам. Так, Google нашла применение своим обширным картографическим данным и мастерству в сфере ИИ, в результате став крупным игроком в отрасли беспилотных транспортных средств.
Вероятно, в определенных секторах также появятся стартапы, которые будут ориентироваться на ИИ в качестве ключевого компонента своих бизнес-моделей. Взять хотя бы отрасль страхования имущества и ответственности, где работает множество уважаемых американских компаний, включая State Farm, Allstate, Geico, Progressive и других. Некоторые из этих компаний, например Progressive, сильны в традиционной аналитике данных, но пока неясно, начала ли хоть одна из них активно внедрять в свою деятельность технологии ИИ.
Однако конкуренцию этим уважаемым игрокам все чаще составляют стартапы вроде нью-йоркской компании Lemonade, которая сделала ИИ основой своего бизнеса. Генеральный директор и соучредитель Lemonade Дэниел Шрайбер написал в своем блоге:
В последние годы отрасль страхования уделяла огромное внимание технологическим стартапам. Они замечают, как цифровая трансформация преобразует пользовательский опыт, привлекает более молодых потребителей и способствует сокращению затрат, одновременно все ускоряя. Все это правда, но это только первое действие… Пока все восхищаются развиваемыми на этом этапе технологиями, замечательные приложения генерируют массу данных. Вскоре они накопят миллиарды записей, после машинной обработки которых и начнется второе действие… Первое действие демонстрирует способность технологии трансформировать любой бизнес путем снижения затрат, повышения скорости и удовлетворения запросов потребителей. Однако, когда начнется второе действие, мы увидим, что ИИ способен трансформировать сферу страхования уникальным образом. Его воздействие не будет ограничиваться повышением удовлетворенности клиентов и ростом производительности – он позволит оценивать риски так точно, как никогда ранее. И этот день близок[11].
Конечно же, уважаемые компании в сфере страхования имущества и ответственности не спешат уступать дорогу конкурентам. Крупная японская страховая компания Sompo Holdings (где я работаю советником) развивает технологии ИИ в нескольких направлениях (хотя стартапы вроде Lemonade пока не столь опасны в Японии). Sompo Holdings одной из первых начала эксперимент с применением интеллектуального агента IBM Watson в сфере обслуживания клиентов. Он создает прогностические модели, используя технологию автоматизированного машинного обучения. При помощи ИИ он извлекает ключевые данные из запросов на страхование бизнеса, а также моделирует метеорологические данные с применением технологий машинного обучения. Генеральный директор Sompo Кенго Сакурада и директор компании по информационным технологиям Коити Нарасаки прекрасно знают, что ИИ способен преобразовать их бизнес, и полны решимости активно исследовать технологию.
Что мы называем искусственным интеллектом и когнитивными технологиями?
Вообще говоря, ИИ и когнитивные технологии используют возможности, которыми ранее обладали только люди (а именно знание, понимание и восприятие), для решения узко определенных (при текущем состоянии технологий) задач. Как правило, это задачи, с которыми быстро справляется любой человек, – идентификация изображений или трактовка смысла предложений. Когда-то решение этих задач было под силу только человеческому мозгу (поэтому они и входят в категорию когнитивных). Немногие сегодня готовы спорить с этим громким определением, хотя не утихают дискуссии о том, насколько близко ИИ подошел к дублированию структур и функций мозга (на мой взгляд, он еще достаточно далек от этого).
Однако важно понимать, что в повседневном применении терминов «искусственный интеллект» и «когнитивные технологии» наблюдается значительная неопределенность. Кое-кто включает в спектр в высокой степени статистические технологии вроде машинного обучения, хотя машинное обучение имеет больше общего с традиционной аналитикой, чем с другими формами ИИ. Некоторые из тех, кто считает машинное обучение искусственно интеллектуальным, даже предпочитают этот термин термину «искусственный интеллект». Кое-кто включает в сферу ИИ технологию роботизированной автоматизации процессов (RPA), которая пока не демонстрировала особой интеллектуальности. Я намереваюсь использовать термин «искусственный интеллект» в самом широком смысле, отчасти потому, что мир, похоже, склоняется именно к этому, а отчасти потому, что все технологии, претендующие на звание искусственного интеллекта, со временем действительно становятся более интеллектуальными.
На основании этого можно сделать вывод о существовании еще одной сложности в использовании ИИ на предприятиях: дело в том, что технологий ИИ достаточно много и большинство из них можно применять несколькими способами, приспосабливая для выполнения различных функций. Комбинации технологий и функций достаточно сложны – настолько, что исследователь ИИ Крис Хэммонд даже предложил «периодическую систему» ИИ[12]. Далее приведена таблица, в которой перечисляются семь ключевых технологий, дается краткое описание каждой из них, а также называются сферы их применения и типичные функции.
Я также опишу, насколько распространена каждая из технологий в мире бизнеса. Я работаю со многими компаниями и прежде всего являюсь профессором в бизнес-школе, но также занимаю должность старшего советника по стратегии и аналитике в Deloitte, что предполагает оказание консалтинговых услуг по вопросам искусственного интеллекта. В 2017 г. я помог подготовить и проанализировать опрос, в котором приняли участие 250 американских работников руководящего звена, осведомленных о когнитивных технологиях, то есть работающих в организациях, активно использующих такие технологии, и понимающих принципы их применения. В первую очередь участников опроса спрашивали, какие технологии используются в их компаниях.
Ниже приведена таблица, в которой подробнее описывается каждая из технологий и сфера ее применения.
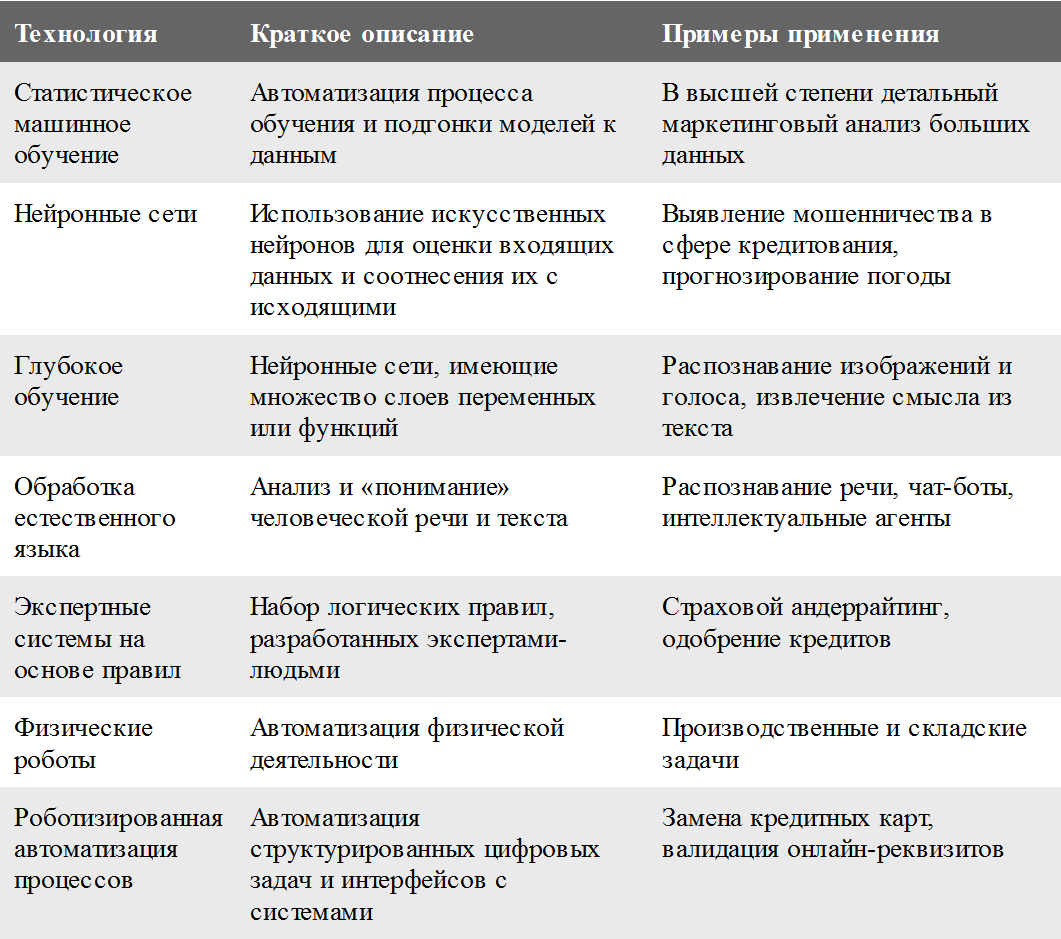
Машинное обучение – это техника автоматической подгонки моделей к данным и «обучения» посредством тренировки моделей данными. Машинное обучение представляет собой одну из самых распространенных форм ИИ: в проведенном в 2017 г. опросе Deloitte 58 % из 250 «осведомленных о когнитивных технологиях» руководителей, компании которых уже внедряли ИИ, ответили, что в их бизнесе используется машинное обучение. Эта техника лежит в основе многих решений в сфере искусственного интеллекта и имеет множество вариантов. Резкий рост объемов данных внутри компаний и – особенно – за их пределами сделал возможным и необходимым применение машинного обучения для осмысления всей этой информации.
Более сложную форму машинного обучения представляет собой нейронная сеть – доступная с 1960-х гг. технология, которая используется для категоризации, например для выявления мошенничества в сфере кредитных операций. Она рассматривает каждую задачу как совокупность входящих и исходящих данных, а также переменных или «функций» различного веса, которые связывают входящие данные с исходящими. Работа этой технологии напоминает процесс обработки сигналов нейронами мозга, но аналогия с мозгом не слишком удачна.
Наиболее сложные формы машинного обучения предполагают глубокое обучение, или построение моделей нейронных сетей, имеющих множество уровней функций и переменных, предсказывающих результаты. В таких моделях могут быть тысячи функций, которые обеспечиваются более быстрой работой современных компьютерных архитектур. В отличие от более ранних форм статистического анализа, каждая функция модели глубокого обучения, как правило, мало что значит для человека. В связи с этим модели очень трудно или невозможно интерпретировать. В опросе Deloitte 34 % компаний использовали технологии глубокого обучения.
Модели глубокого обучения прогнозируют и классифицируют результаты с применением техники обратного распространения ошибки[13]. Именно эта технология ИИ стоит за целым рядом недавних прорывов – от победы над человеком при игре в го до классификации изображений в интернете. Отцом глубокого обучения часто называют Джеффри Хинтона из Университета Торонто и компании Google – и отчасти как раз из-за ранней работы над техникой обратного распространения ошибки.
В машинном обучении задействуется более сотни возможных алгоритмов, и большинство из них весьма причудливы. Спектр этих алгоритмов весьма широк и охватывает все – от повышения градиента (метода построения моделей, которые устраняют ошибки предыдущих моделей, тем самым повышая их способность к прогнозированию и классификации) до случайных лесов (моделей, которые представляют собой ансамбль моделей дерева принятия решений). Все чаще программное обеспечение (включая DataRobot, SAS и AutoML от Google) позволяет автоматизировать построение моделей машинного обучения, в ходе которого происходит апробация различных алгоритмов с целью выявить наиболее удачный[14]. Как только обнаруживается лучшая модель для прогнозирования или классификации тренировочных данных, ее используют для прогнозирования и классификации новых данных (иногда это называют скорингом).
Однако важен не только используемый алгоритм, но и принцип обучения создаваемых моделей. Модели обучения с учителем (на сегодняшний день наиболее распространенные в бизнесе) учатся на основе набора тренировочных данных с маркированным результатом. Например, модель машинного обучения, которая пытается предсказать мошенничество в банке, необходимо учить на системе, где мошенничество в некоторых случаях было однозначно установлено. Это непросто, поскольку частота мошенничества может составлять 1 случай на 100 000, и порой эту проблему называют проблемой несбалансированности классов.
Обучение с учителем очень похоже на традиционный аналитический метод регрессионного анализа, который используется в модели оценки. Цель регрессионного анализа заключается в том, чтобы создать модель, предсказывающую известный результат, используя набор входных переменных с известными значениями, которые могут быть связаны с этим результатом. Когда модель разработана, ее можно использовать для предсказания неизвестного результата на основе известных значений тех же входных переменных. Например, можно разработать регрессионную модель, предсказывающую вероятность заболевания диабетом в зависимости от возраста пациента, уровня его физической активности, количества потребляемых калорий и индекса массы тела. При разработке этой модели мы будем ориентироваться на пациентов, которые уже заболели или не заболели диабетом, используя все доступные данные для построения регрессионной модели. Обнаружив хорошую предсказательную регрессионную модель, мы сможем использовать ее на новом наборе данных, чтобы предсказать неизвестный результат – вероятность заболевания диабетом в зависимости от определенных значений входных переменных. Это называется скорингом (как в регрессионном анализе, так и в машинном обучении).
Регрессионный процесс напоминает машинное обучение с учителем, но имеет ряд особенностей:
● В машинном обучении данные, используемые для разработки (тренировки) модели, называются тренировочными данными и могут представлять собой подмножество данных, необходимых исключительно для тренировки системы.
● В машинном обучении тренировочная модель часто утверждается при помощи другого подмножества данных, для которого известен подлежащий предсказанию результат.
● В регрессионном анализе может и не возникнуть желание использовать модель для предсказания неизвестных результатов, тогда как в машинном обучении наличие этого желания подразумевается.
● В машинном обучении может использоваться множество различных алгоритмов, которые не ограничиваются простым регрессионным анализом.
Модели обучения без учителя, как правило, более сложны в разработке. Они распознают закономерности в данных, которые не маркированы заранее и для которых неизвестен результат. Третий способ обучения, обучение с подкреплением, предполагает, что система машинного обучения имеет определенную цель и каждое продвижение к этой цели вознаграждается. Такой способ весьма полезен в играх, однако он также требует огромного объема данных (и из-за этого порой теряет практичность)[15]. Важно отметить, что модели машинного обучения с учителем обычно не учатся непрерывно: они учатся на основе набора тренировочных данных, а затем продолжают использовать ту же модель, если только не задействуется новый набор тренировочных данных, на основе которого обучаются новые модели.
Модели машинного обучения опираются на статистику. Оценить их растущую ценность можно в сравнении с традиционной аналитикой. Как правило, они точнее традиционных «кустарных» аналитических моделей, основанных на человеческих предположениях и регрессионном анализе, но при этом они сложнее и хуже поддаются интерпретации. Автоматизированные модели машинного обучения могут создаваться намного быстрее и описывать более детализированные наборы данных, чем в случае с традиционным статистическим анализом. При наличии необходимого объема данных для обучения модели глубокого обучения очень хорошо справляются с такими задачами, как распознавание изображений и голоса. Они работают гораздо лучше, чем ранние автоматизированные системы для решения этих задач, а в некоторых сферах их возможности уже сравнимы с человеческими или даже превосходят их.
Обработка естественного языка (ОЕЯ)С 1950-х гг. перед исследователями ИИ стояла цель научить машину распознавать язык человека. В эту сферу, называемую обработкой естественного языка, входят такие варианты использования технологий, как распознавание речи, текстовый анализ, перевод, генерация текста и решение других языковых задач. ОЕЯ использовали 53 % компаний, участвовавших в опросе об осведомленности о когнитивных технологиях. Есть два основных подхода к ОЕЯ – статистический и семантический. Статистическая ОЕЯ основана на машинном обучении и сегодня совершенствуется быстрее семантической. Она требует большого корпуса, или совокупности, текстов, на которых учится. Например, для перевода требуется большой объем переведенных текстов, статистически анализируя которые система узнает, что испанское и португальское слово amor находится в тесной статистической взаимосвязи с английским словом love. Этот метод использует «грубую силу», однако часто он довольно эффективен.
До последнего десятилетия внимание уделялось исключительно семантической ОЕЯ, и она демонстрирует умеренную эффективность, если система удачно натренирована на распознавание слов, синтаксиса и концептуальных связей. Однако обучение языку и инженерия знаний (которая часто предполагает создание графа знаний в определенной области) требуют много времени и сил. Для этого необходима разработка онтологий или моделей отношений между словами и фразами. Хотя создавать семантические модели ОЕЯ нелегко, сегодня этим занимаются несколько систем интеллектуальных агентов.
Производительность систем ОЕЯ следует измерять двумя способами. Первый – оценивать процент произнесенных слов, которые система понимает. Этот показатель возрастает при использовании технологии глубокого обучения и часто превышает 95 %. Второй способ – проверять, на какое количество различных типов вопросов система в состоянии ответить, а также сколько задач она может решить. Как правило, для этого необходима семантическая ОЕЯ, а поскольку в этой сфере нет серьезных технических прорывов, системы, которые отвечают на вопросы или решают конкретные задачи, контекстно обусловлены и требуют тренировки. Компьютер IBM Watson прекрасно справился с ответами на вопросы Jeopardy! но не сможет отвечать на вопросы Wheel of Fortune, если его не тренировать, а эти тренировки часто весьма трудоемки. Возможно, в будущем для ответов на вопросы будет применяться метод глубокого обучения, однако пока этого еще не делали.
Экспертные системы на основе правилВ 1980-х гг. экспертные системы на основе наборов правил «если – то» были доминирующей технологией ИИ и долгое время широко использовались в коммерческих целях. Сегодня их обычно не считают последним словом техники, но проведенный в 2017 г. опрос Deloitte об осведомленности о когнитивных технологиях показал, что их по-прежнему используют 49 % американских компаний, работающих с ИИ.
Экспертные системы требуют, чтобы эксперты и инженеры знаний разработали набор правил для конкретной области знаний. Они широко распространены, к примеру, в страховом андеррайтинге и банковском кредитном андеррайтинге, но также используются в нетрадиционных областях вроде обжарки кофе в Folgers или приготовлении супов в Campbell's. Они неплохо работают и просты для понимания. Однако, если количество правил велико (обычно больше нескольких сотен) и правила начинают конфликтовать друг с другом, системы не справляются с задачами. Кроме того, если меняется область знаний, приходится менять и все правила, а это сложно и трудоемко.
Системы на основе правил не слишком усовершенствовались с момента своего раннего расцвета, но представители активно применяющих их отраслей (вроде страхования и банковского дела) надеются, что вскоре появится новое поколение технологий на основе правил. Исследователи и поставщики технологий уже обсуждают возможность создания «адаптивных машин обработки правил», которые будут постоянно модифицировать правила на основе новых данных, или комбинаций машин обработки правил с машинным обучением (но все это пока не получило широкого распространения).
Физические роботыФизическими роботами сегодня никого не удивить, ведь каждый год по всему миру внедряется более 200 000 промышленных роботов. В том или ином качестве физических роботов используют 32 % компаний, руководители которых приняли участие в опросе об осведомленности о когнитивных технологиях. На заводах и складах роботы выполняют такие задачи, как подъем и перемещение грузов, а также сварка и сборка объектов. Ранее они управлялись детализированными компьютерными программами, которые позволяли им выполнять конкретные задачи, но в последнее время роботы более тесно сотрудничают с людьми, а обучать их стало легче, поскольку можно просто пройти с ними весь цикл необходимой задачи. Они также становятся более интеллектуальными по мере того, как в их «мозг» (то есть в операционную систему) встраиваются другие возможности ИИ. Кажется весьма вероятным, что со временем интеллект физических роботов будет улучшен так же, как интеллект других систем.
Роботизированная автоматизация процессов (РАП)Эта технология выполняет структурированные цифровые задачи (то есть задачи, связанные с информационными системами) так, как если бы их выполнял человек, следующий сценарию или правилам. Не все согласны, что РАП принадлежит к семейству технологий ИИ и когнитивных технологий, поскольку она не слишком интеллектуальна. Однако системы РАП популярны и автоматизированы, а их интеллектуальность растет, поэтому я включаю их в мир ИИ. Иногда их называют цифровой рабочей силой. В сравнении с другими формами ИИ они не слишком дороги и просты в программировании. При этом их работа прозрачна. Если вы умеете пользоваться мышкой, понимаете графические модели технологических процессов и готовы создать несколько бизнес-правил «если – то», вы в состоянии разобраться в этой технологии и, возможно, даже разработать РАП. Настраивать и внедрять такие системы также гораздо проще, чем разрабатывать собственные программы, используя язык программирования.
РАП не задействует роботов – только компьютерные программы на серверах. Опираясь на сочетание рабочего процесса, бизнес-правил и интеграции «уровня представления» с информационными системами, она функционирует как полуинтеллектуальный пользователь этих систем. Порой РАП сравнивают с макрокомандами электронных таблиц, но я считаю такое сравнение некорректным, поскольку РАП может справляться с гораздо более сложными задачами. Ее также сравнивают с инструментами управления бизнес-процессами, которые могут управлять рабочим процессом, но на самом деле технология была создана для того, чтобы документировать и анализировать процесс, а не автоматизировать его[16].
Некоторые системы РАП уже в определенной степени наделены интеллектом. Они могут «наблюдать» за тем, как работают их коллеги-люди (например, как они отвечают на частые вопросы клиентов), и имитировать их действия. Другие сравнивают процесс автоматизации с машинным зрением. Как и физические роботы, системы РАП постепенно становятся более интеллектуальными, а для управления их поведением начинают использоваться другие типы технологий ИИ.
Я описал эти технологии по отдельности, но все чаще они объединяются и интегрируются. Однако сегодня человеку, принимающему бизнес-решения, очень важно знать, какие технологии какие задачи выполняют. Директор по информационным технологиям Global Inc. Кришна Натан отмечает, что в 2018 г. один из ключевых приоритетов его компании – «помочь акционерам понять, на что способен и не способен ИИ, чтобы использовать его должным образом»[17]. Возможно, в будущем эти технологии окажутся так тесно переплетены, что необходимость в таком понимании исчезнет, а возможно, технологии вообще станут неотделимы друг от друга.
ИИ в сообществе поставщиков технологий
В этой книге я в основном рассказываю об использовании когнитивных технологий крупными предприятиями в таких сферах, как предоставление финансовых услуг, производство и телекоммуникация. Но большая часть работы, выполняемой крупными коммерческими предприятиями, стала возможной благодаря исследованиям и разработкам, проводившимся в тех же местах, где в 2000-х гг. развивались технологии больших данных (включая Hadoop, Pig и Hive). В этот период Google, Facebook и в меньшей степени Yahoo! направляли значительные усилия на развитие технологий ИИ. Эти компании располагали огромным объемом данных для анализа, огромным количеством денег (по крайней мере в случае Google и Facebook) и прочными связями с учеными.
GoogleПожалуй, не стоит удивляться, что компания Google стала самым активным разработчиком и пользователем технологий ИИ среди интернет-гигантов (а возможно, и среди всех компаний мира). Работая в сотрудничестве со стэнфордским профессором Эндрю Ыном, Google начала исследовать ИИ (в частности, глубокое обучение) в лабораториях Google X еще в 2011 г. Этот проект получил название Google Brain. Главным образом в рамках него изучалась технология глубокого обучения, которая использовалась для распознавания изображений и решения других задач. К 2012 г. группа исследователей решила одну из самых важных проблем человечества – как заставить машину распознать фотографию кота в интернете.
В следующем году Google наняла исследователя из Университета Торонто Джеффри Хинтона, который помог возродить нейронные сети. В 2014 г. Google купила лондонскую компанию DeepMind, весьма компетентную в сфере глубокого обучения. Инструменты группы были использованы, чтобы помочь созданной Google программе AlphaGo, играющей в древнюю игру го, победить одного из лучших игроков в мире. В 2016 г. команда Google Brain помогла Google существенно улучшить точность переводов Google-переводчика. К тому году Google и ее материнская компания Alphabet использовали машинное обучение более чем в 2700 проектах, включая разработку алгоритмов поиска (RankBrain), создание беспилотных автомобилей (теперь этим занимается Waymo – дочерняя компания Alphabet) и усовершенствование медицинской диагностики (дочерняя компания Calico)[18]. Как это принято в Кремниевой долине, в 2015 г. Google также открыла бесплатный доступ к своей библиотеке машинного обучения TensorFlow, которая стала проектом с открытым кодом и завоевала популярность среди компаний более узкой направленности, использующих ИИ.
FacebookВозможно, Facebook внедряет когнитивные технологии в свои продукты и процессы не столь успешно, как Google, но получается все же довольно неплохо. Вместо Эндрю Ына и Джеффа Хинтона исследованиями ИИ в компании занимается Ян Лекун, который также преподает в Нью-Йоркском университете. Лекун уделяет особое внимание распознаванию изображений, что стало ключевым направлением разработок Facebook. У компании есть приложение для распознавания изображений Lumos, которое анализирует фотографии в Facebook и Instagram и предлагает пользователям персонализированную рекламу на основании их материалов. Lumos также помогает идентифицировать запрещенные порнографические материалы или материалы, содержащие насилие (хотя в этом процессе по-прежнему задействовано и большое количество людей), неправомерное использование брендов и логотипов и материалы террористической направленности.




