

Полная версия
Подготовка набора данных для обучения и тестирования программного обеспечения на основе технологии искусственного интеллекта. Учебное пособие
4. Подготовка и разметка должны быть проведены техническими и медицинскими специалистами, имеющими соответствующие навыки и компетенции.
Наборы данных для обучения и тестирования алгоритмов искусственного интеллекта можно классифицировать различными способами. Например, выделяют наборы со структурированными, частично структурированными и неструктурированными данными; либо разделяют их по источникам формирования, условиям использования, типам биомедицинских и клинических данных, по временным характеристикам, файловой структуре, наконец, по видам задач, для решения которых наборы сформированы и т. д.
Рекомендуется использовать две классификации: по диагностической ценности (подробнее см. параграф 1.2 «Классификация разметки и наборов данных») и по целевому назначению (подробнее см. параграф 3.1 «Этап инициирования создания набора данных»).
Контрольные вопросы
1. Дайте определение понятию «Набор данных».
2. Дайте определение понятию «Разметка данных».
3. Перечислите нормативно-правовые акты, регулирующие создание набора данных.
4. Что такое эталонный набор данных?
5. Перечислите основные требования к эталонному набору данных.
1.2. Классификация разметки и наборов данных
Под разметкой в контексте классификации медицинских наборов данных понимается установка категориального или визуального признака в данных, выполненная медицинским персоналом и/или врачом-экспертом.
Класс разметки варьируется в зависимости от задачи, поставленной ПО на основе ТИИ, и основывается на методах верификации данных. В таблице 1 представлены принципы классификации методов верификации, разработанные на основе собственного опыта, а также рекомендаций Управления по санитарному надзору за качеством пищевых продуктов и медикаментов (Food and Drug Administration, FDA [5]). Под верификацией понимают проверку данных на достоверность, правильность и точность. На рисунке 1 изображены методы верификации данных по возрастанию их ценности.

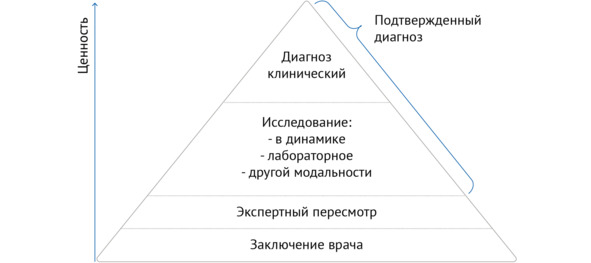
Рисунок 1 – Диаграмма методов верификации НД
Наименьшей ценностью обладает верификация по заключению врача, т.е. вывод о наличии или отсутствии патологии делается на основании заключения врача, описывавшего исследование. Как правило, такой способ разметки используется на первых этапах отбора данных и может быть осуществлен с помощью алгоритмов автоматического анализа текстовых протоколов, например MedLabel12. Следующим по ценности методом верификации является экспертный пересмотр: слепой анализ исследований врачами-экспертами с достижением заданного уровня согласованности их решений (подробно описан в подпараграфе 3.3.2 «Разметка данных»). Следующие две группы методов являются наиболее достоверными, и их можно условно назвать «подтвержденный диагноз»: исследование той же модальности в динамике, исследование другой модальности, лабораторное исследование, которые в совокупности с остальными данными медицинской карты дают клинический диагноз. Стоит отметить, что для верификации каждой патологии существует свой метод «золотого стандарта», который позволяет подтвердить диагноз.
На рисунке 2 представлена классификация видов разметки на примере рака молочной железы (РМЖ) с учетом ценности разметки.
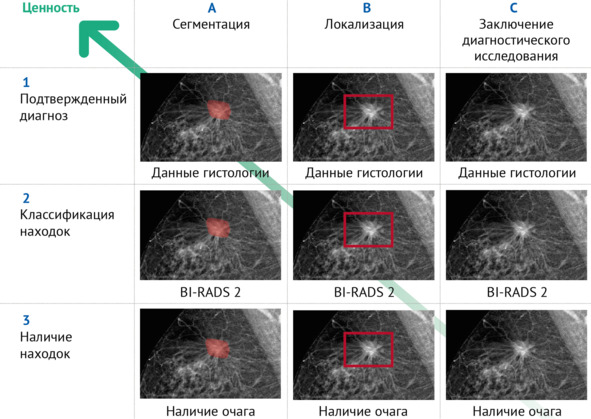
Рисунок 2 – Классификация видов разметки в медицинской диагностике по диагностической ценности
В наиболее общем виде разметка данных может проводиться на основании:
А. Информации об имеющейся целевой патологической находке, представленной на изображении в виде пиксельной маски (оконтуренной области изображения). Дополнительно может содержаться в метаданных (аннотации).
B. Информации об имеющейся целевой патологической находке, представленной в виде координат. Может помещаться в метаданных (в аннотации, в сводном табличном сопроводительном файле) и/или присутствовать на изображении в виде отметки области расположения простой геометрической фигурой.
С. Информации о наличии/отсутствии целевой патологической находки, содержащейся в метаданных (то есть в аннотации – сопроводительных файлах) и отсутствующей на изображении.
Классификация A, B, C для уровня 3 (обнаружение находки) предполагает вовлечение врачей-экспертов с целью поиска (наличие/отсутствие – С), локализации (В) и сегментации (А)13.
В случае локализации врачу необходимо обозначить координаты области интереса простой геометрической фигурой, в случае сегментации – обвести контур области интереса, т.е. создать пиксельную маску. Для уровня 2 (классификация находки) необходимо классифицировать находку, используя общепринятые шкалы (например, BI-RADS14, ASPECTS15). Для уровня 1 (подтвержденный диагноз) необходимы данные медицинской карты, позволяющие поставить диагноз.
Классификация отображает взаимосвязь:
– объемов и качества исходных данных;
– трудозатрат на подготовку;
– методик разметки и работы с первичными данными;
– диагностической ценности.
Стоит отметить, что данная классификация применима в случае поиска патологических находок. Для некоторых НД, например, при задаче сегментации анатомической структуры, подтверждение диагноза неприменимо, соответственно данную классификацию использовать нельзя.
Также разметку данных можно разделить на проспективную и ретроспективную, т.е. по времени их получения.
Проспективная разметка аналогично ретроспективной разметке представляет собой сбор элементов в соответствии с поставленной целью, при этом обязательным условием является проведение дополнительных манипуляций с элементами (например, постановка метки начала и окончания события, меток обнаружения признаков, обозначений патологий и т.п.). Этот вид разметки проводят с участием обученного медицинского персонала (зачастую квалифицированного врача в субспециализации размечаемого набора данных) путем ручного аннотирования содержания данных или их частей.
Ретроспективная разметка данных представляет собой сбор элементов в соответствии с метаданными, которые отбираются по поставленной цели. Такую разметку проводят путем минимальных трудозатрат: выгрузка данных происходит из медицинской информационной системы, которую может провести инженер (аналитик) без участия врача. При этом для каждого элемента (изображение, сигнальные данные и т.д.) набора данных устанавливают соответствие с медицинской информацией (диагноз, результаты лабораторного тестирования и т.п.).
Также разметка характеризуется следующими параметрами:
1. Уровень разметки: пациент, серия, набор изображений, изображение.
Примеры:
– на уровне пациента: у пациентки с диагнозом злокачественного новообразования (ЗНО) молочной железы разметка проводится на основании маммографии и гистологического исследования;
– на уровне серии (у той же пациентки): маммография, прямая и боковая проекции;
– на уровне изображения: прямая проекция правой молочной железы.
2. Тип разметки: бинарная, мультикласс, мультилейбл.
Примеры:
– бинарная разметка: норма/патология;
– мультиклассовая разметка: норма/патология/технический дефект;
– мультилейбл разметка: лейбл «Признаки эмфиземы легкого», лейбл «Процент поражения легкого».
3. Характер разметки: бинарная, категориальная, регрессионная.
Примеры:
– бинарная: наличие признаков патологии/отсутствие признаков патологии;
– категориальная: категория BI-RADS для маммографии;
– регрессионная: процент поражения легкого при COVID-19.
Контрольные вопросы
1. Какие бывают методы верификации данных?
2. Какие бывают виды разметки данных по диагностической ценности?
3. Как классифицируется разметка данных в зависимости от времени получения данных?
4. Перечислите параметры разметки.
5. Какие бывают уровни разметки данных? Приведите примеры.
Глава 2. ЖИЗНЕННЫЙ ЦИКЛ НАБОРОВ МЕДИЦИНСКИХ ДАННЫХ
Жизненный цикл – развитие системы, продукции, услуги, проекта или другой создаваемой изготовителем сущности – от замысла до вывода из эксплуатации.
Жизненный цикл данных – последовательность этапов, которую конкретная порция данных проходит от начального этапа создания или получения до момента архивации или удаления [6].
Жизненный цикл наборов данных состоит из следующих этапов:
– инициирования;
– планирования;
– формирования;
– этап регистрации и публикации;
– использования;
– смены версии;
– удаления и архивации.
Последовательность и взаимосвязь этих этапов представлена на рисунке 3.
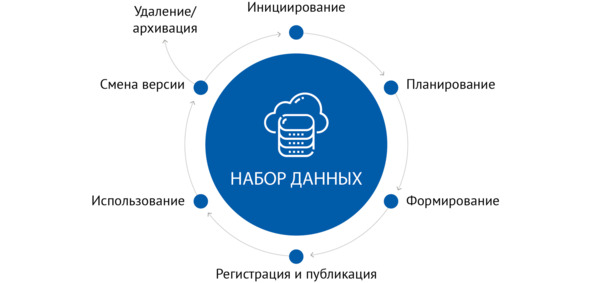
Рисунок 3 – Жизненный цикл наборов данных
Этап инициирования
Данный этап начинается с момента возникновения потребности или идеи создания НД, поэтому первое, с чем необходимо определиться – это цель их создания. На основании цели создания НД разработана классификация по типам:
I. Проведение тестирований для оценки функционала (функциональное тестирование) и оценки метрик диагностической точности, настройки ПО на основе ТИИ (калибровочное тестирование) [7].
II. «Самотестирование техническое» – проведение самостоятельной проверки разработчиками способности ПО на основе ТИИ обрабатывать исследования с диагностических устройств разных производителей и моделей [8].
III. «Самотестирование диагностическое» – проведение самостоятельной проверки корректности клинической интерпретации исследований ПО на основе ТИИ [9].
IV. Выполнение клинических испытаний – оценка безопасности и эффективности медицинского изделия [4,10].
V. Выполнение технических испытаний – оценка соответствия характеристик ПО на основе ТИИ требованиям нормативно-правовой, технической и эксплуатационной документации[11].
VI. Проведение разметки текстовых протоколов с помощью программ автоматизированного анализа текстов.
VII. Проведение научных исследований [12].
VIII. Разработка ПО на основе ТИИ: обучение и дообучение [13].
После определения цели создания НД формируются или используются ранее подготовленные базовые диагностические требования (БДТ) и базовые функциональные требования (БФТ) [14]. БДТ – это требования к содержащейся в информации НД, необходимой для решения поставленных задач и достижения цели (модальность исследования, целевая патология, критерии отнесения исследований к классам и т.д.). Процесс создания БДТ описан в главе 3, подпараграф 3.1.1. БФТ – это описание технических особенностей отображения результатов клинических исследований (серия изображений, толщина срезов, окно визуализации и т.д.). Процесс создания БФТ описан в главе 3, подпараграф 3.1.2.
БДТ и БФТ – основные документы для формирования технического задания (ТЗ), которое в свою очередь является основным документом, регламентирующим и структурирующим разработку НД. Процесс создания ТЗ описан в главе 3, подпараграф 3.1.3.
Этап планирования
На этапе планирования определяются сроки подготовки НД, финансовые и людские ресурсы (назначаются исполнители, а именно врачи-разметчики, специалисты, ответственные за сборку НД и формирование сопровождающей документации, руководитель проекта), необходимые для подготовки НД, определяются риски (технические, административные и т.д.), которые могут повлиять на выполнение работы. При определении содержания работ, осуществляемых конкретным специалистом, проводится декомпозиция ТЗ на создание НД и уточняются требования к составу, количеству исследований, типам и способам разметки для каждого из задействованных специалистов (если это необходимо для выполнения работы).
Этап формирования
На данном этапе происходит непосредственно процесс создания НД: сбор данных, их разметка, структурирование, анонимизация, формирование файлов данных, разметки и сопроводительного текстового файла (readme-файла). Все файлы помещаются в хранилище данных. Подробный алгоритм формирования НД описан в главе 3 (параграф 3.3 «Этап формирования набора данных»).
Этап регистрации и публикации
На этапе регистрации вся информация о НД вносится в реестр. Полностью формируется так называемая карточка НД, где указываются все клинические, популяционные, технические параметры, параметры разметки, область применения, а также сформированные название и идентификатор НД.
Завершающим этапом процесса создания НД является его публикация – помещение структурированного набора файлов в отдельную директорию хранилища с регламентированным уровнем доступа.
По уровню доступа НД разделяются на общедоступные (открытые), ограниченного доступа (закрытые) и закрытые с общедоступными примерами. Общедоступные НД размещаются в открытом доступе (так называемые библиотеки НД) и предназначены для использования разработчиками ПО на основе ТИИ для проведения обучения, тестирования и/или валидации своей разработки.
Конец ознакомительного фрагмента.
Текст предоставлен ООО «Литрес».
Прочитайте эту книгу целиком, купив полную легальную версию на Литрес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.
Примечания
1
Приказ Министерства труда и социальной защиты Российской Федерации от 07.11.2017 №768н «Об утверждении профессионального стандарта „Специалист в области организации здравоохранения и общественного здоровья“».
2
Приказ Министерства труда и социальной защиты Российской Федерации от 19.03.2019 №160н «Об утверждении профессионального стандарта „Врач-рентгенолог“».
3
Приказ Министерства труда и социальной защиты Российской Федерации от 02.08.2021 №531н «Об утверждении профессионального стандарта „Специалист по тестированию в области информационных технологий“».
4
Гусев А. В. Перспективы нейронных сетей и глубокого машинного обучения в создании решений для здравоохранения // Врач и информационные технологии. 2017. №3. С. 92—105 URL: https://www.idmz.ru/jurnali/vrach-i-informatsionnye-tekhnologii/2017/3/perspektivy-neironnykh-setei-i-glubokogo-mashinnogo-obucheniia-v-sozdanii-reshenii-dlia-zdravookhraneniia.
5
Гусев А. В., Добриднюк С. Л. Искусственный интеллект в медицине и здравоохранении // Информационное общество. 2017. №4—5. С. 78—93.
6
Соболева С. У., Голиков В. В., Тажибов А. А. Информационные технологии в здравоохранении: особенности отраслевого применения // E-Management. State University of Management, 2021. Т. 4, №2. С. 37—43.
7
Dash S., Shakyawar S. K., Sharma M. et al. Big data in healthcare: management, analysis and future prospects // J Big Data. SpringerOpen. 2019. Vol. 6, №1. P. 1—25.
8
Shakhabov I. V., Melnikov Yu. Yu., Smyshlyaev A. V. Development of digital technologies in healthcare during the COVID-19 pandemic // Scientific Review. Medical Sciences. 2020. №6. P. 66—71.
9
Henriksen E. L. Carlsen F., Vejborg I. M. et al. The efficacy of using computer-aided detection (CAD) for detection of breast cancer in mammography screening: a systematic review // Acta radiol. 2019. Vol. 60, №1. P. 13—18.
10
Lauritzen A. D., Rodríguez-Ruiz A., von Euler-Chelpin M. C. et al. An Artificial Intelligence—based Mammography Screening Protocol for Breast Cancer: Outcome and Radiologist Workload // Radiology. 2022. Vol. 304, №1. P. 41—49.
11
Морозов С. П., Гаврилов А. В., Архипов И. В. [и др.]. Влияние технологий искусственного интеллекта на длительность описаний результатов компьютерной томографии пациентов с COVID-19 в стационарном звене здравоохранения // Профилактическая медицина. 2022. Т. 25, №1. С. 14—20.
12
Свидетельство о государственной регистрации программы для ЭВМ №2020664321 Российская Федерация. MedLabel – автоматизированный анализ медицинских протоколов: заявл. 11.11.2020 / Морозов С. П., Андрейченко А. Е., Кирпичев Ю. С. [и др.]; заявитель ГБУЗ «НПКЦ ДиТ ДЗМ».
13
Willemink M. J., Koszek W. A., Hardell C., et al. Preparing medical imaging data for machine learning // Radiology. 2020. Vol. 295, №1. P. 4—15
14
BI-RADS – Breast Imaging Reporting and Data System – стандартизированная шкала оценки результатов маммографии, УЗИ и МРТ по степени риска наличия злокачественных образований молочной железы. Breast Imaging Reporting & Data System | American College of Radiology [Internet]. [cited 2023 Apr 8]. Available from: https://www.acr.org/Clinical-Resources/Reporting-and-Data-Systems/Bi-Rads.
15
ASPECTS (Alberta Stroke Program Early CT Score) – шкала качественной топографической оценки изменений, выявляемых при КТ у пациентов с инсультом головного мозга; Pexman J. H., Barber P. A., Hill M., et al. Use of the Alberta Stroke Program Early CT Score (ASPECTS) for assessing CT scans in patients with acute stroke // AJNR Am J Neuroradiol. 2001. Vol. 22, №8. Р. 1534—1542.