


Полная версия
Глоссариум по искусственному интеллекту и информационным технологиям
«М»
Маркер (Token) в языковой модели – это элементарная единица, на которой модель обучается и делает прогнозы.
Марковская модель (Markov model) — это статистическая модель, имитирующая работу процесса, похожего на марковский процесс с неизвестными параметрами, задачей которой является определение неизвестных параметров на основе наблюдаемых данных.
Марковский процесс (Markov process) – это случайный процесс, эволюция которого после любого заданного значения временного параметра t не зависит от эволюции, предшествовавшей t, при фиксированных параметрах процесса67.
Массив данных (датасет) – это идентифицируемая совокупность данных, к которой можно получить доступ или скачать в одном или нескольких форматах68.
Масштабируемость (Scalability) – это способность системы, сети или процесса справляться с увеличением рабочей нагрузки (увеличивать свою производительность) при добавлении ресурсов (обычно аппаратных).
Машина опорных векторов (Support Vector Machine) – это популярная модель обучения с учителем, разработанная Владимиром Вапником и используемая как для классификации данных, так и для регрессии. Тем не менее, он обычно используется для задач классификации, построения гиперплоскости, где расстояние между двумя классами точек данных максимально. Эта гиперплоскость известна как граница решения, разделяющая классы точек данных по обе стороны от плоскости.
Машина Тьюринга (Turing machine) – это математическая модель вычислений, определяющая абстрактную машину, которая манипулирует символами на полосе ленты в соответствии с таблицей правил. Несмотря на простоту модели, для любого компьютерного алгоритма можно построить машину Тьюринга, способную имитировать логику этого алгоритма.
Машинное восприятие (Machine perception) – это способность системы получать и интерпретировать данные из внешнего мира аналогично тому, как люди используют наши органы чувств. Обычно это делается с подключенным оборудованием, хотя можно использовать и программное обеспечение.
Машинное зрение (Machine Vision) – это применение общего набора методов, позволяющих компьютерам видеть, для промышленности и производства.
Машинное обучение (Machine Learning) – это область исследования, которая дает компьютерам возможность учиться без явного программирования». Также под машинным обучением понимают технологии автоматического обучения алгоритмов искусственного интеллекта распознаванию и классификации на тестовых выборках объектов для повышения качества распознавания, обработки и анализа данных, прогнозирования. Также машинное обучение определяют, как одно из направлений (подмножеств) искусственного интеллекта, благодаря которому воплощается ключевое свойство интеллектуальных компьютерных систем – самообучение на основе анализа и обработки больших разнородных данных. Чем больше объем информации и ее разнообразие, тем проще искусственному интеллекту найти закономерности и тем точнее будет получаемый результат69,70,71,72,73.
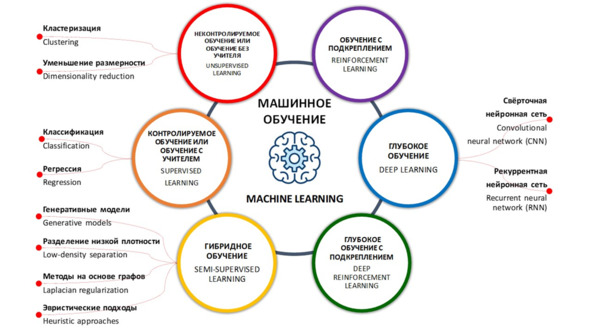
Машинное обучение Microsoft Azure (платформа автоматизации искусственного интеллекта) (Microsoft Azure Machine Learning) – это функция, которая предлагает расширенную облачную аналитику, предназначенную для упрощения машинного обучения для бизнеса. Бизнес-пользователи могут моделировать по-своему, используя лучшие в своем классе алгоритмы из пакетов Xbox, Bing, R или Python или добавляя собственный код R или Python. Затем готовую модель можно за считанные минуты развернуть в виде веб-службы, которая может подключаться к любым данным в любом месте. Его также можно опубликовать для сообщества в галерее продуктов или на рынке машинного обучения. В Machine Learning Marketplace доступны интерфейсы прикладного программирования (API) и готовые сервисы. Также, – это способность машин автоматизировать процесс обучения. Входными данными этого процесса обучения являются данные, а выходными данными – модель. Благодаря машинному обучению система может выполнять функцию обучения с данными, которые она принимает, и, таким образом, она становится все лучше в указанной функции.
Машинный разум (Machine intelligence) – это общий термин, охватывающий машинное обучение, глубокое обучение и классические алгоритмы обучения.
Машины опорных векторов или сети опорных векторов (Support-vector machines, Support-vector networks) – это контролируемые модели обучения с соответствующими алгоритмами обучения, которые анализируют данные для классификации и регрессионного анализа. Разработаны в AT&T Bell Laboratories Владимиром Вапником с коллегами в 1992 году. Машины опорных векторов являются одним из самых надежных методов прогнозирования, основанным на статистическом обучении или теории Вапника – Червоненкиса, предложенной Вапником (1982, 1995) и Червоненкисом (1974). Учитывая набор обучающих примеров, каждый из которых помечен как принадлежащий к одной из двух категорий, алгоритм обучения машины опорных векторов строит модель, которая относит новые примеры к той или иной категории, превращая ее в невероятностный двоичный линейный классификатор (хотя методы такие как масштабирование Платта, существуют для использования машин опорных векторов в вероятностной классификации). Машины опорных векторов сопоставляют обучающие примеры с точками в пространстве, чтобы максимизировать ширину разрыва между двумя категориями. Затем новые примеры сопоставляются с тем же пространством, и их принадлежность к категории определяется в зависимости от того, на какую сторону разрыва они попадают. В дополнение к выполнению линейной классификации SVM могут эффективно выполнять нелинейную классификацию, используя так называемый трюк ядра, неявно отображая свои входные данные в многомерные пространства признаков. Когда данные не размечены, обучение с учителем невозможно, и требуется подход к обучению без учителя, который пытается найти естественную кластеризацию данных в группы, а затем сопоставляет новые данные с этими сформированными группами. Алгоритм кластеризации опорных векторов, созданный Хавой Зигельманн и Владимиром Вапником, применяет статистику опорных векторов, разработанную в алгоритме машин опорных векторов, для категоризации неразмеченных данных74,75.
Мероприятия по информатизации (Informatization activities) – это предусмотренные мероприятия программ цифровой трансформации государственных органов, направленные на создание, развитие, эксплуатацию или использование информационно-коммуникационных технологий, а также на вывод из эксплуатации информационных систем и компонентов информационно-телекоммуникационной инфраструктуры.
Мероприятия программы цифровой трансформации, осуществляемые государственным органом (Measures of the digital transformation program carried out by a state body) – это объединенная единой целью совокупность действий государственного органа, в том числе мероприятий по информатизации, направленных на выполнение задач по оптимизации административных процессов предоставления государственных услуг и (или) исполнения государственных функций, созданию, развитию, вводу в эксплуатацию, эксплуатации или выводу из эксплуатации информационных систем или компонентов информационно-коммуникационных технологий, нормативно-правовому обеспечению указанных процессов или иных задач, решаемых в рамках цифровой трансформации.
Метод оперирования большими данными – это совокупность теоретических принципов и/или практических приемов для оперирования большими данными76.
Методология разработки и операции (DevOps, development & operations) – это набор методик, инструментов и философия культуры, которые позволяют автоматизировать и интегрировать между собой процессы команд разработки ПО и ИТ-команд. Особое внимание в DevOps уделяется расширению возможностей команд, их взаимодействию и сотрудничеству, а также автоматизации технологий. Под термином DevOps также понимают особый подход к организации команд разработки. Его суть в том, что разработчики, тестировщики и администраторы работают в едином потоке – не отвечают каждые за свой этап, а вместе работают над выходом продукта и стараются автоматизировать задачи своих отделов, чтобы код переходил между этапами без задержек. В DevOps ответственность за результат распределяется между всей командой77,78.
Методы эвристического поиска (Heuristic search techniques) – это методы, которые сужают поиск оптимальных решений проблемы за счет исключения неверных вариантов.
Механизм внимания (Attention mechanism) – это одно из ключевых нововведений в области нейронного машинного перевода. Внимание позволило моделям нейронного машинного перевода превзойти классические системы машинного перевода, основанные на переводе фраз. Основным узким местом в sequence-to-sequence обучении является то, что все содержимое исходной последовательности требуется сжать в вектор фиксированного размера. Механизм внимания облегчает эту задачу, так как позволяет декодеру оглядываться на скрытые состояния исходной последовательности, которые затем в виде средневзвешенного значения предоставляются в качестве дополнительных входных данных в декодер.
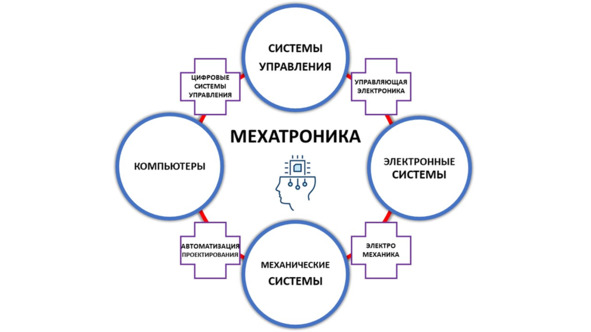
Мехатроника (Mechatronics) – это научно-техническая дисциплина, посвящённая созданию и эксплуатации электроприводов с программным управлением, которые обеспечивают высокоточные движения. Мехатронные узлы, блоки и системы строятся по технологиям, интегрирующим механику, электротехнику, силовую электронику, микропроцессорную технику, программное управление. Эти компактные модули применяются в самых разных системах, которые используют многие отрасли: авто- и авиастроение; космическая техника; производство спортивного оборудования; медтехника; бытовая техника; робототехника79.
Минимизация структурных рисков (Structural risk minimization, SRM) – это индуктивный принцип использования в машинном обучении. Обычно в машинном обучении обобщенная модель должна быть выбрана из конечного набора данных, что приводит к проблеме переобучения – модель становится слишком строго адаптированной к особенностям обучающего набора и плохо обобщается для новых данных. Принцип SRM решает эту проблему, уравновешивая сложность модели с ее успехом в подборе обучающих данных. Этот принцип был впервые изложен в статье 1974 года Владимира Вапника и Алексея Червоненкиса80.
Многозадачное обучение (Multitask learning) – это общий подход, при котором модели обучаются выполнению различных задач на одних и тех же параметрах. В нейронных сетях этого можно легко добиться, связав веса разных слоев. Идея многозадачного обучения была впервые предложена Ричем Каруаной в 1993 году и применялась для прогнозирования пневмонии, а также для создания системы следования дороге на беспилотных устройствах (Каруана, 1998). Фактически при многозадачном обучении модель стимулируют к созданию внутри себя такого представления данных, которые позволяет выполнить сразу много задач. Это особенно полезно для обучения общим низкоуровневым представлениям, на базе которых потом происходит «концентрация внимания» модели или в условиях ограниченного количества обучающих данных. Многозадачное обучение нейросетей для обработки естественного языка было впервые применено в 2008 году Коллобером и Уэстоном (Collobert & Weston, 2008).
Мобильное здравоохранение (Mobile healthcare, mHealth) – это ряд мобильных технологий, систем, сервисов и приложений, установленных на мобильных устройствах и использующихся в медицинских целях и для обеспечения здорового образа жизни человека и мотивации людей к здоровому образу жизни и формированию новой «цифровой» культуры здоровья.
Модель от последовательности к последовательности (Sequence-to-sequence model, seq2seq). Самая популярная задача на последовательность – это перевод: обычно с одного естественного языка на другой. За последние пару лет коммерческие системы стали на удивление хороши в машинном переводе – взгляните, например, на Google Translate, Yandex Translate, DeepL Translator, Bing Microsoft Translator. Сегодня мы узнаем об основной части этих систем81.
Модель убеждений, желаний и намерений (Belief-desire-intention software model) – это модель программирования интеллектуальных агентов. Образно модель описывает убеждения, желания и намерения каждого агента, однако непосредственно применительно к конкретной задаче агентного программирования. По сути, модель предоставляет механизм позволяющий разделить процесс выбора агентом плана (из набора планов или внешнего источника генерации планов) от процесса исполнения текущего плана, выбранного ранее. Как следствие, агенты, повинующиеся данной модели способны уравновешивать время, затрачиваемое ими на выбор и отсеивание будущих планов со временем исполнения выбранных планов. Процесс непосредственного синтеза планов (планирование) в модели не описывается и остаётся на откуп программного дизайнера или программиста82.
Модули векторной обработки (Intelligent Engines) – это поле выполнения операций умножения с плавающей запятой с минимальными задержками (DSP Engines) и специализированное поле/модуль AI Engines c высокой пропускной способностью, а также минимальными задержкам на выполнение операций и оптимальным уровнем энергопотребления, предназначенное для решения задач в области реализации искусственного интеллекта (AI inference) и цифровой обработки сигналов.
Мозговая технология (также самообучающаяся система ноу-хау) (Brain technology) – это технология, в которой используются последние открытия в области неврологии. Термин был впервые введен Лабораторией искусственного интеллекта в Цюрихе, Швейцария, в контексте проекта ROBOY. Brain Technology может использоваться в роботах, системах управления ноу-хау и любых других приложениях с возможностями самообучения. В частности, приложения Brain Technology позволяют визуализировать базовую архитектуру обучения, которую часто называют «картами ноу-хау».
Мозгоподобные вычисления (Brain-inspired computing) – это вычисления на мозгоподобных структурах, вычисления, использующие принципы работы мозга.
Мозгоподобные вычисления (Brain-inspired computing) – это вычисления использующие принципы работы мозга.
Мультиопыт (Multiexperience) – это процесс замены людей, понимающих технологии, на технологии, понимающие людей.
Мульти-опыт (Multi-experience) – это часть долгосрочного перехода от индивидуальных компьютеров, которые мы используем сегодня, к многопользовательским, мультисенсорным и многолокационным системам.
«Н»
Набор данных (Data set) – это совокупность данных, прошедших предварительную подготовку (обработку) в соответствии с требованиями законодательства Российской Федерации об информации, информационных технологиях и о защите информации и необходимых для разработки программного обеспечения на основе искусственного интеллекта (Национальная стратегия развития искусственного интеллекта на период до 2030 года).
Наивный байесовский классификатор (Naive Bayes classifier) – это простой вероятностный классификатор, основанный на применении теоремы Байеса со строгими (наивными) предположениями о независимости.
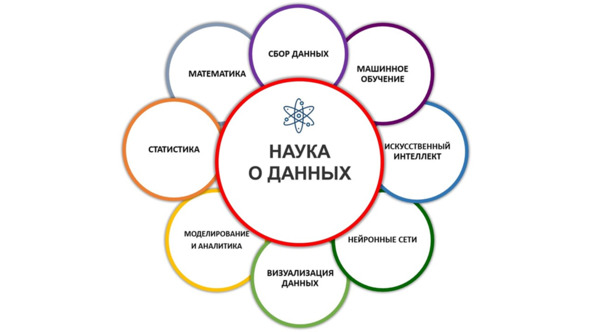
Наука о данных (Data science) – это область исследования, которая сочетает в себе опыт предметной области, навыки программирования и знания математики и статистики для извлечения осмысленной информации из данных. Специалисты по обработке и анализу данных применяют алгоритмы машинного обучения к числам, тексту, изображениям, видео, аудио и многому другому для создания систем искусственного интеллекта (ИИ) для выполнения задач, которые обычно требуют человеческого интеллекта. В свою очередь, эти системы генерируют информацию, которую аналитики и бизнес-пользователи могут преобразовать в ощутимую ценность для бизнеса. А также, Наука о данных определяется как междисциплинарная область, в которой используются научные методы, процессы, алгоритмы и системы для извлечения знаний и идей из структурированных и неструктурированных данных, а также для применения знаний и практических идей из данных в широком диапазоне областей применения. Наука о данных – это профессиональная деятельность, связанная с эффективным и максимально достоверным поиском закономерностей в данных, извлечение знаний из данных в обобщённой форме, а также их оформление в виде, пригодном для обработки заинтересованными сторонами (людьми, программными системами, управляющими устройствами) в целях принятия обоснованных решений. Также, – это процесс исследования, фильтрация, преобразование и моделирования данных с целью извлечения полезной информации и принятия решений83,84,85.
Небольшие данные (Small data) – это данные, представляемые в таких объеме и формате для понимания человеком, в каких они становятся доступными, информативными и действенными.
Нейрокомпьютер (Neural computer) – это цифровая и/или аналоговая компьютерная система, базирующаяся на нейронной сети и исполняющая нейросетевые алгоритмы.
Нейрология (нейронаука, Neuroscience) – это изучение того, как развивается нервная система, ее структура и функции. Нейробиологи сосредотачиваются на мозге и его влиянии на поведение и когнитивные функции. Неврология занимается не только нормальным функционированием нервной системы, но и тем, что происходит с нервной системой, когда у людей возникают неврологические, психические расстройства и нарушения развития нервной системы. Неврологию часто называют во множественном числе нейробиологией. Неврологию традиционно относят к разделу биологии. В наши дни это междисциплинарная наука, которая тесно связана с другими дисциплинами, такими как математика, лингвистика, инженерия, информатика, химия, философия, психология и медицина. Многие исследователи говорят, что нейробиология означает то же самое, что и нейробиология. Тем не менее, нейробиология рассматривает биологию нервной системы, в то время как неврология относится ко всему, что связано с нервной системой86.
Нейроморфная инженерия (Neuromorphic engineering) – это использование принципов построения биологических нервных систем при конструировании микросхем; концепция, предложенная Карвером Мидом (Carver Mead) в конце 1980-х гг. с целью создания искусственных нейронов, СБИС и систем, копирующих архитектуры нервных систем биологических объектов.
Нейроморфная сеть (Neuromorphic network) – это сеть, узлами которой являются нейроморфные устройства.
Нейроморфная теория (Neuromorphics) – это методология, технология, которая первоначально ставила своей целью реализовать биологические принципы в аналоговых управляющих системах и датчиках, а в настоящее время этот термин употребляется также и для описания аналоговых, цифровых и гибридных аппаратных и программных систем, реализующих модели ИНС.
Нейроморфное аппаратное обеспечение (Neuromorphic hardware) – это аппаратное обеспечение для систем ИИ, построенное на нейроморфной элементной базе.
Нейроморфное оборудование (Neuromorphic equipment) – это любое электрическое устройство, которое имитирует природные биологические структуры нервной системы человека.
Нейроморфные системы (Neuromorphic systems) – это реализация в кремнии систем, архитектура которых базируется на нейробиологии (дисциплина, изучающая физиологию, строение, развитие мозга и нервной системы); используют вычисления с массовым параллелизмом. Нейроморфные системы могут быть как цифровыми, так и аналоговыми, при этом роль синапсов играет либо программное обеспечение, либо мемристоры, которые могут хранить значение из некоторого диапазона величин, а не только традиционные единицу и ноль, что позволяет имитировать изменение силы связи (весов) между двумя синапсами. Изменение этих весов в моделируемых синапсах – это один из способов позволить нейроморфным системам учиться.
Нейроморфный ИИ (Neuromorphic AI, Neuromorphic artificial intelligence) – это системы ИИ, строящиеся по образу и подобию мозга человека, характеризующиеся громадным быстродействием на определённых видах задач (обработки и распознавания изображений, машинного обучения и др.) и на несколько порядков меньшим энергопотреблением, чем у сравнимых по производительности суперкомпьютеров.
Нейроморфный исследователь (Neuromorphic researcher) – это учёный-исследователь в области искусственных нейронных сетей.
Нейроморфный процессор (Neural processing unit, NPU) – это процессор, выполняющий нейрокомпьютерные (нейросетевые) вычисления.
Нейронная сеть (Artificial Neural Network) – это математическая модель, а также ее программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей – сетей нервных клеток живого организма.
Нейронная сеть AlexNet (AlexNet) – это название нейронной сети, победившей в конкурсе ImageNet Large Scale Visual Recognition Challenge в 2012 году. Она названа в честь Алекса Крижевского, в то время аспиранта компьютерных наук в Стэнфордском университете.
Нейронные сети прямого распространения (FeedForward Networks) – это нейронная сеть с многими слоями, где данные распространяются только вперёд.
Нейронный процессор (Neural processor) – это специализированный класс микропроцессоров и сопроцессоров (часто являющихся специализированной интегральной схемой), используемый для аппаратного ускорения работы алгоритмов искусственных нейронных сетей, компьютерного зрения, распознавания по голосу, машинного обучения и других методов искусственного интеллекта.
Нейронный сетевой процессор (Neural Network Processor, NNP) – это специализированный класс микропроцессоров и сопроцессоров (часто являющихся специализированной интегральной схемой), используемый для аппаратного ускорения работы алгоритмов искусственных нейронных сетей, компьютерного зрения, распознавания по голосу, машинного обучения и других методов искусственного интеллекта.
Нейротехнологии (Neurotechnologies) – это киберфизические системы, частично или полностью замещающие/дополняющие функционирование нервной системы биологического объекта, в том числе на основе искусственного интеллекта.
Неоконнекционизм (Neoconnectionism) – это подход в области когнитивистики и нейронауки, который заключается в компьютерном моделировании процессов обучения искусственными нейронными сетями, организованными и функционирующими по аналогии с биологической нервной системой.
Новые производственные технологии (New production technologies) – это технологии цифровизации производственных процессов, обеспечивающие повышение эффективности использования ресурсов, проектирования и изготовления индивидуализированных объектов, стоимость которых сопоставима со стоимостью товаров массового производства.
«О»
Обезличивание персональных данных (Depersonalization of personal data) – это действия, в результате которых становится невозможным без использования дополнительной информации определить принадлежность персональных данных конкретному субъекту персональных данных.
Обладатель информации (Information owner) – это лицо, самостоятельно создавшее информацию либо получившее на основании закона или договора право разрешать или ограничивать доступ к информации, определяемой по каким-либо признакам.
Облачная робототехника (Сloud robotics) – это область робототехники, которая пытается использовать облачные технологии, такие как облачные вычисления, облачное хранилище и другие интернет-технологии, основанные на преимуществах конвергентной инфраструктуры и общих сервисов для робототехники. При подключении к облаку роботы могут воспользоваться мощными вычислительными, накопительными и коммуникационными ресурсами современного центра обработки данных в облаке, который может обрабатывать и обмениваться информацией от различных роботов или агентов (других машин, интеллектуальных объектов, людей и т.д.). Люди также могут делегировать задачи роботам удаленно через сети. Технологии облачных вычислений позволяют наделять роботизированные системы мощными возможностями при одновременном снижении затрат за счет облачных технологий. Таким образом, можно создавать легкие, недорогие, умные роботы с интеллектуальным «мозгом» в облаке. «Мозг» состоит из центра обработки данных, базы знаний, планировщиков задач, глубокого обучения, обработки информации, моделей среды, поддержки связи и т.д.87.







