


Полная версия
Язык эмоций и эмоциональный слух. Избранные труды
Недаром поэтому язык музыки и пения – понятный всем на земле язык эмоций – звучит на всех международных фестивалях как язык, не знающий границ, содействуя взаимопониманию и дружбе между людьми.
«Наоборотный» язык Лады Самсоновой
Знакомьтесь. Перед вами улыбающаяся миловидная девушка, обладательница уникальной способности: она владеет «наоборотным языком». Его суть в том, что слова любой фразы Лада может произносить наоборот, т. е. как бы читать их, начиная с последней буквы к первой. При этом делает она это столь быстро и уверенно, что подвергает окружающих просто в изумление. Эти «наоборотные» процедуры Лада легко производит не только со знакомыми словами, но и с незнакомыми, которые она слышит впервые.
Мы пригласили Ладу Самсонову в нашу лабораторию невербальной коммуникации Института психологии Академии наук СССР, чтобы познакомиться более подробно с ее необычными способностями, тем более что в течение ряда лет, точнее с 1987 г., мы занимаемся изучением способностей людей воспринимать смысл слов и значение различных видов невербальной экстралингвистической информации (эмоциональной, индивидуально-личностной и др.) в условиях ее обратного, т. е. инвертированного во времени, предъявления слушателю. Практически это достигается путем прокручивания магнитофонной ленты с записью речевых и других звуков в обратном направлении.
Еще в 60-х годах французский исследователь А. Моль показал, что метод временного инвертирования (т. е. прокручивания магнитоленты в обратном направлении) разрушает для слушателя семантическую, т. е. собственно речевую, вербальную, информацию, но сохраняет, как он пишет, эстетическую информацию, к которой он, по сути его высказываний, причислял все виды невербальной информации образно-предметного (иконического) характера. Молем, однако, не было проделано детальное исследование на этот предмет разных видов экстралингвистической информации речи, что мы и проделали.
Согласно нашей гипотезе (основанной, кстати, на ряде экспериментальных фактов и другого рода), имеется принципиальное различие в механизмах обработки мозгом собственно речевой (вербальной) и невербальной (экстралингвистической) информации (см. разделы данной статьи «Человек и ЭВМ – проблемы взаимопонимания» и «Двухканальная природа речевого общения»). Различия эти, в частности, и должны были проявиться в особенностях восприятия мозгом как собственно речевой, так и разных видов экстралингвистической информации.
Первое, что мы сделали, – это попытались прокрутить наоборот для группы испытуемых (слушателей) пленку с записью уже знакомых читателю эмоционально окрашенных фраз, произнесенных О. Басилашвили, а также пленки с записями эмоционально окрашенных в разные тона голосов певцов.
Результаты показали, что восприятие наоборот практически не лишает возможности слушателей правильно воспринимать эмоциональную окраску по сравнению с нормой. Несколько сниженный общий процент правильных восприятий можно отнести за счет необычности «наоборотного» звучания речи и пения. Некоторая тренировка практически сглаживает эти различия.
Таким образом, человек, не понимая ни одного слова в «наоборотной» речи и пении, прекрасно и притом сходу (безо всякой тренировки) распознает язык эмоций в инвертированном во времени варианте.
Способен рядовой слушатель (по нашим данным) распознать в «наоборотном» звучании и другой вид экстралингвистической информации – возраст говорящего. Для этой цели были использованы те же самые эмоционально окрашенные фразы О. Басилашвили, а испытуемым давалось задание определить только возраст говорящего и больше ничего. Результаты показали, что слушатели в целом близко к истине определили возраст О. Басилашвили. Но при этом выяснилась любопытная деталь – возраст артиста, по оценкам слушателей, оказался зависимым от эмоциональной окраски его голоса (!): эмоции гнева и страха дали максимальный возраст (около 50 лет), а эмоции радости и нейтральное звучание привели к минимальным оценкам (около 39 лет). Поскольку разница по оценкам возраста немалая – около 10 лет – людям, у желающих выглядеть помоложе – а это прежде всего относится к прекрасному полу, – есть шанс «помолодеть», воспользовавшись знанием этой психологической закономерности.
Если же говорить серьезно, то здесь мы сталкиваемся с весьма важным законом взаимодействия и взаимовлияния различных видов экстралингвистической информации на уровне ее восприятия и обработки мозгом человека. Данные эти могут оказаться не бесполезным и в криминалистике в случае рассмотрения свидетельских показаний об опознании возраста человека по его голосу.
А способен ли человек узнать своего знакомого, если его голос будет звучать наоборот? Проведенные нами опыты показали, что слушатели – а их было 26 человек – прекрасно справились с этой задачей, определив по голосу (в среднем с точностью 86 %) 20 своих знакомых (10 мужчин и 10 женщин) и отличив их от двух совершенно незнакомых людей, голоса которых были специально включены в магнитофонную тестовую запись, прокручиваемую наоборот. Пол диктора при этом был неправильно воспринят всего лишь в 1 % случаев, что соответствует точности определения в этих условиях пола диктора по его голосу с надежностью 99 %!
Опрос испытуемых-слушателей показал, что при определении по «наоборотному» голосу своих знакомых и эмоций они в значительной мере ориентировались на сохраняющиеся для нашего слуха в этих условиях тембровые особенности голоса. Теоретические расчеты, а также экспериментальные их проверки показывают, что при инвертировании во времени интегральные спектры голоса, ответственные за индивидуально-эмоциональные особенности тембра, сохраняются. Это дает основание полагать, что способность слушателей к восприятию невербальных характеристик голоса основывается именно на интегральных, т. е. усредненных за определенное время, характеристиках спектра. Согласно современным научным представлениям, такой механизм целостного восприятия характерен для работы правого полушария мозга человека.
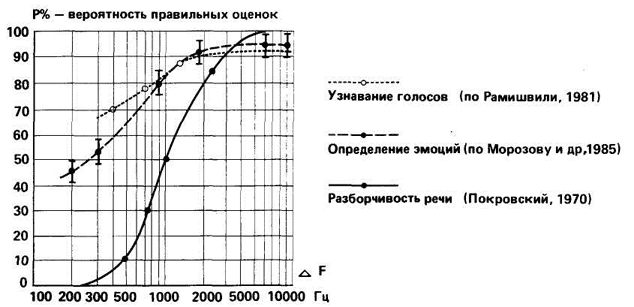
Рис. 6. Зависимость правильных оценок различных видов речевой информации от ограничения спектра высоких частот.
Экстралингвистическая информация голоса оказывается более помехоустойчивой (по сравнению с лингвистической) не только по отношению к действию шума, но и по отношению к частотному ограничению спектра. График показывает, что ограничение высоких частот до 300 Гц полностью разрушает лингвистическую информацию. Определение же эмоций в таком сигнале, так же как и узнавание диктора, в значительной степени сохраняется
Как уже упоминалось, речь при «наоборотном» звучании слушателю непонятна, что говорит о принципиально иных механизмах декодирования мозгом. Считается, что механизм этот заключается в тонком, детальном во времени посегментном (пофонемном, послоговом) анализе динамики формантной структуры речевого сигнала. Поскольку же динамика эта в «наоборотном» звучании искажена (инвертирована) во времени, то мозг, естественно, и не может декодировать речевую информацию в этих условиях.
Но необходимо уточнить: обычно не может, поскольку оказалось, что Лада Самсонова это делать может. Нам удалось также узнать, что «наоборотным языком» владеют и другие люди, правда, в разной степени совершенства. Один из них – молодой человек по имени Орест также был гостем нашей лаборатории, и мы записали на магнитофон его диалог с Ладой на этом необычном языке. Данные эти обрабатываются и составят предмет специальной работы.
Что же касается языка эмоций в «наоборотном» виде, то, как показали наши опыты, он доступен каждому из нас.
Двухканальная природа речевого общения
Одним из важнейших принципов работы мозга, отличающих его от многих технических систем, в частности ЭВМ (по крайней мере, старого типа), является принцип параллельной обработки многих разных видов информации, поступающей по разным анализаторным каналам (слух, зрение, кожно-тактильное, мышечное чувство и др.) и даже в пределах одного и того же канала. Применительно к звуковой речи мозг можно считать двухканальной системой, несмотря на кажущуюся одноканальность речевого акустического сигнала.
Таким образом, традиционная одноканальная схема речевой коммуникации (заимствованная в свое время у Шеннона) нуждается в принципиальной коррекции. В свете приведенных в этом разделе данных и других современных представлений, двухканальная природа звуковой речевой коммуникации иллюстрируется рисунком 6, где указанные каналы обозначены терминами «лингвистическая информация» и «экстралингвистическая информация». Экстралингвистический канал, в свою очередь, состоит из множества субканалов по характеру разных видов этого рода информации.
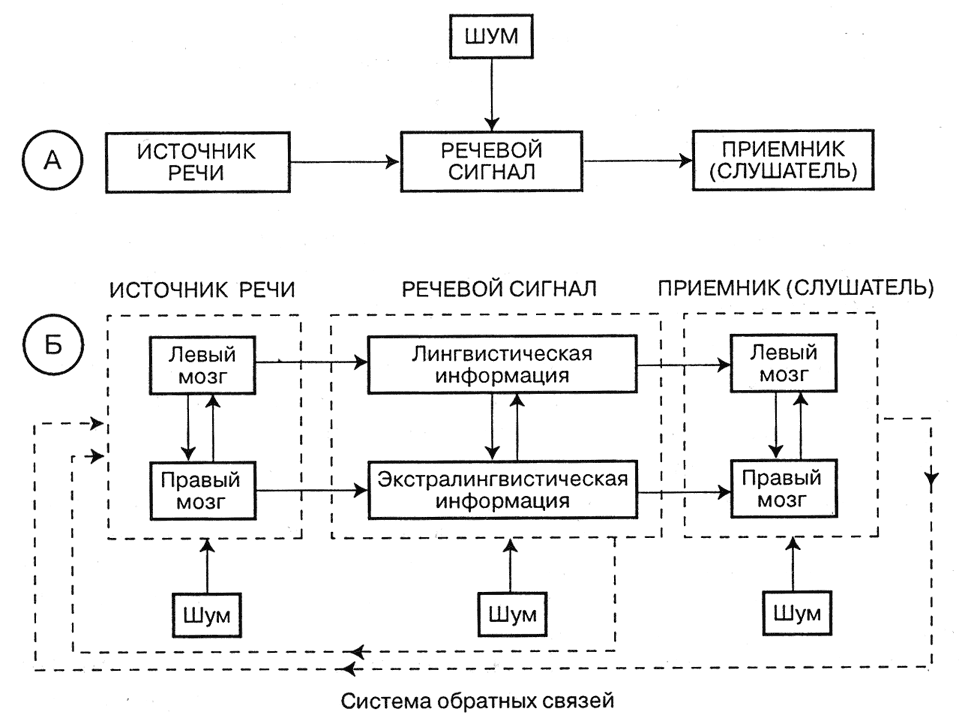
Рис. 7. Традиционная схема речевой коммуникации, представленная одним каналом (А), и схема речевой коммуникации, подчеркивающая ее двухканальную природу
В мозгу человека осуществляется функциональное разделение этих каналов по принципам обработки информации: левое (лингвистическое) полушарие осуществляет посегментный анализ речевого сигнала, ориентируясь на тонкую динамику его формантной структуры в микроинтервалах времени, а правое (экстралингвистическое) полушарие использует целостный принцип анализа на основе сравнения интегрального акустического образа сигнала с хранящимися в памяти паттернами (эталонами) образцов этого вида информации.
Двухканальный принцип работы мозга проявляется не только в условиях восприятия речи, но и в процессе формирования (порождения) речевого высказывания в форме принципиально разных функций больших полушарий мозга в этом процессе.
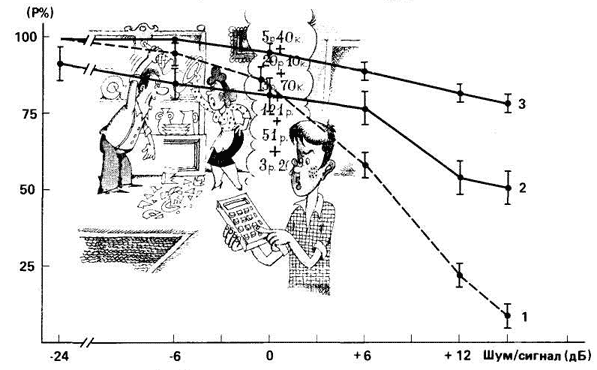
Рис. 8. Вероятность (Р, %) правильного восприятия различных видов речевой информации при увеличении соотношения шум/сигнал (дБ): 1 – лингвистической, 2 – эмоциональной, 3 – половой принадлежности диктора.
Помехоустойчивость экстралингвистических видов информации (эмоциональной и о половой принадлежности диктора) намного выше, чем лингвистической (речь). При действии сильного шума (при соотношении сигнал/шум=+16 дБ) лингвистическая информация полностью разрушается (слушатели не могут разобрать ни одного слова), но восприятие эмоций возможно с вероятностью более 50 %, а пола диктора – более 80 %
Объективной основой разделения мозгом каналов лингвистической и экстралингвистической коммуникации являются различия в акустических средствах и принципах кодирования этих двух видов речевой информации. Если для вербальной информации определяющим является динамика формантной структуры сигнала, то для экстралингвистической, как показали наши исследования, особую роль приобретают динамика основного тона голоса и другие особенности просодической организации речи. Таким образом, лингвистический и экстралингвистический каналы оказываются обособленными (по целому ряду критериев) во всех звеньях системы речевой коммуникации. По отношению к действию шума эта обособленность проявляется в разной помехоустойчивости лингвистической и экстралингвистической информации: помехоустойчивость экстралингвистической информации оказывается выше (рисунок 7).
Несомненны также различия между указанными каналами и в эволюционно-историческом аспекте: экстралингвистическая коммуникация является значительно более древней по сравнению с лингвистической. Возникновение в процессе эволюции слова как весьма совершенного средства передачи любых видов информации не привело, однако, к умалению эволюционно древней формы экстралингвистической коммуникации. Она продолжает сосуществовать наряду со словом, существенно дополняя и видоизменяя его смысл, а во многих случаях претендуя на самостоятельность. В огромном большинстве ситуаций речевого общения более важным является не столько ЧТО говорит человек, сколько КАК говорит и КТО говорит. Доминирующая роль экстралингвистической информации представляется очевидной в таких специфических видах звуковой коммуникации, как искусство сценической речи и пения. Важнейшим и почти неизученным свойством двухканальной системы речевой коммуникации является взаимодействие каналов лингвистической и экстралингвистической информации, появляющейся во всех звеньях данной системы и на всех этапах обработки речевой информации мозгом.
Человек и ЭВМ – проблемы взаимопонимания
Наиболее удобным, оптимальным, с точки зрения человека, было бы введение информации в ЭВМ не при помощи клавиатуры, а непосредственно с голоса, т. е. естественным речевым средством общения между людьми. Однако сегодня ЭВМ, как известно, не понимает речь человека в должной мере и с должной надежностью, и пользователю нужно прибегать к услугам целого штата «переводчиков» (программистов, операторов), осуществляющих ввод информации в ЭВМ на особом, понятном для ЭВМ языке, а также дешифрующих выданную машиной информацию.
Создание машин 5-го поколения, надежно понимающих речь любого человека, а также говорящих машин является глобальной задачей мировой науки, в решении которой значительные успехи принадлежат Японии, США, Франции. Однако задача эта оказалась настолько трудной, что полностью ее решить пока что не удалось. Например, машина легко распознает речь одного человека или нескольких знакомых ей дикторов, но не желает распознавать незнакомых, понимает речь взрослых и не хочет понимать детей. Если же и удается расширить круг дикторов, то тут же приходится ограничивать объем словаря. Даже могучие современные ЭВМ не в состоянии пока что решить в полной мере такую детскую задачу, как письмо под диктовку. Пусть даже знакомый машине диктор будет читать знакомый ей текст, но простуженным голосом, или не очень внятно, или в шуме – машина его не поймет.
Специалист по данной проблеме доктор технических наук М. Сулуквадзе, работающий в Институте систем управления Академии наук Грузинской ССР, считает, что «автоматическое распознавание речи следует считать одной из наиболее сложных проблем технической кибернетики. Мы не уверены, что она будет полностью решена и через 50 лет, то есть к 2034 году. Под термином „полностью“ подразумевается уровень восприятия и понимания речи человеком в реальных условиях его речевого взаимодействия с другими людьми».

Рис. 9. Раритет
Причина столь упорного «нежелания» ЭВМ научиться в совершенстве понимать речь кроется в индивидуальных и эмоциональных особенностях речи людей, сильно искажающих ту фонетическую структуру стандартного речевого сигнала, на распознавание которого заранее настраивается машина. Так, известно, что речевая информация кодируется формантной структурой (частотой формант и их динамикой). Но частота особенно первых формант существенно зависит от частоты основного тона голоса: повышается при повышении голоса и снижается при понижении основного тона речи. Изменения во времени основного тона голоса – это важнейшее средство эмоциональной выразительности (интонации голоса), и происходят они в связи с эмоциями в пределах до одной, полутора и даже двух октав (!), как это наблюдается при сильном эмоциональном возбуждении. Это и приводит к сильнейшей деформации всей спектральной структуры речи и непониманию речи машиной. По данным Г. Фанта, женские и детские голоса, имеющие повышенную, по сравнению с мужскими, частоту основного тона, характеризуются и повышенными формантными частотами (в среднем на 17–25 %).
Очевидно, в мозгу есть механизм, учитывающий информацию о повышении средних частот формант в связи с повышением основного тона голоса (высота голоса). Потому-то нам практически безразлично, на какой высоте основного тона голоса произносятся слова: произносит ли их мужской, женский или детский голос – разборчивость, понятность речи обеспечиваются.
Но перечисленные трудности – это лишь малая толика всех их, стоящих на пути обучения ЭВМ пониманию речи. Образно говоря, все виды речевой информации – лингвистической и экстралингвистической – как бы «растворены» в звуке голоса человека. Наш слух не испытывает затруднений в их разделении и учете, а машина «затрудняется». Поэтому можно надеяться, что изучение индивидуально-эмоциональных особенностей речи и механизмов, на которые опирается наш слух и мозг при их разделении, позволит наконец окончательно решить и проблему ее автоматического распознавания. Может быть, здесь пригодятся данные о том, что для восприятия и переработки логической и эмоциональной информации речи в мозгу человека имеются два специализированных и вместе с тем взаимодействующих отдела: левое полушарие мозга – для логики, правое – для эмоций. Кстати, в одной из работ под редакцией виднейшего американского специалиста по автоматическому распознаванию речи Уайна Ли описаны алгоритм и устройство распознавания речи, основанные на принципах работы правого полушария мозга (т. е. целостного, а не посегментного анализа, с учетом просодических и экстралингвистических характеристик речевого сигнала).
Взаимодействие человека с компьютером предполагает создание на базе ЭВМ говорящих роботов. Все, конечно, слышали по радио в научно-популярных передачах лишенный каких-либо эмоций голос робота. Безэмоциональность – характерное его свойство, которое и проявляется в голосе. А почему, собственно, робот и его голос должны быть безэмоциональными? Нельзя ли «оживить» его голос интонациями человеческой речи? Ведь эмоциональная окраска голоса делает его эстетически более приятным, психологически совместимым с восприятием человека, а кроме того, она отнюдь не бесполезный акустический аккомпанемент речи, а несет очень нужную информацию, например, о степени важности сообщения, грозящей опасности и т. п.
Вдохнуть эмоции в бездушный мозг робота – одна из задач кибернетической науки, связанная с выделением и формализацией инвариантных акустических признаков, ответственных за эмоциональную окраску звука.
Ясно, что «оживление» речи робота – одна из многих технических задач, решить которую нельзя без знания алфавита акустического языка эмоций. Но, чтобы заложить этот алфавит в электронный мозг робота, необходимо сначала выявить, потом формализовать признаки, ответственные за эмоциональность голоса.
Таким образом, решение проблемы полного взаимопонимания человека и ЭВМ требует эмоционализации компьютера. Необходимо, чтобы робот, так же как и человек, услышав, например, фразу «Я очень рад вас видеть!», произнесенную не нейтрально, а насмешливым голосом, мог бы не только четко воспринять слова (в чем он сейчас явно затрудняется), но и понять эмоциональную интонацию, отрицающую смысл слов. Робот должен понимать наш язык эмоций.
Трудно переоценить практическое значение такого рода автомата, например, для контроля психологического состояния космонавтов, летчиков-испытателей и многих других операторов, которые по характеру своей работы находятся в сложной экстремальной обстановке и от точности действий которых зависит успех дела. Уже есть попытки создания машины, реагирующей на эмоции в голосе человека. Одна из них на основе оценки темпо-ритмических характеристик речи принадлежит группе инженеров, работающих в содружестве с фонетистом Э. Л. Носенко, о чем они сообщили на симпозиуме «Речь, эмоции и личность». На аналогичное устройство, но на основе динамики основного тона получили авторское свидетельство ленинградские ученые (Галунов, Манёров, 1981). Под руководством П. В. Симонова и М. В. Фролова внедрено устройство для регистрации эмоций авиаторов и т. д.
Рис. 10. Проблема человека – проблема робота
Машину-автомат, безошибочно опознающую личность человека по его голосу, наверное, охотно возьмут на службу и криминалисты, ведь в ее беспристрастности и объективности трудно усомниться. Над теоретическими основами создания такой машины успешно трудится грузинский ученый Г. С. Рамишвили.
Заключение
В заключение отметим, что представленные в статье данные о восприятии человеком эмоциональной интонации голоса как одного из важнейших средств экстралингвистической коммуникации впервые получены нами с применением модели не только актерской, но и вокальной речи (пения). Комплекс этих исследований позволил выдвинуть представление об эмоциональном слухе как специфической системе обработки этого рода информации в мозгу человека, входящей в структуру экстралингвистической коммуникации и имеющей древнейшие основы. В ряде работ нами показано, что степень развитости эмоционального слуха может служить одним из объективных критериев принадлежности человека к художественному типу личности (по И. П. Павлову). Практической реализацией этих исследований явилось внедрение разработанных нами тестов и методик для профотбора лиц художественных профессий.
Представление о речевой коммуникации как о двухканальной системе является, несомненно, плодотворным в бионическом смысле, т. е. для создания новых, более совершенных систем автоматического анализа и синтеза речи с помощью ЭВМ. Можно с уверенностью сказать, что дальнейшие успехи в решении проблемы автоматического анализа и синтеза речи будут зависеть от того, насколько полно удастся техническими средствами смоделировать принцип парной работы полушарий головного мозга человека с учетом функциональной специализации каждого из них при восприятии и переработке (а также генерировании) разных видов речевой информации: собственно речевой (лингвистической) и экстралингвистической.
II. Вокальная речь как язык эмоций[3]
Экспериментальные исследования
1. Основные задачи
Акустический сигнал вокальной речи несет значительно больше эмоциональной информации по сравнению с обычной речью. Это обстоятельство предопределено самой природой вокальной речи и не требует особых доказательств. В этой связи вокальная речь представляется исключительно удобным объектом для изучения эмоционально-выразительных средств голоса человека.
Акустические средства выражения эмоций в обычной речи в последнее время начинают привлекать внимание исследователей во все большей и большей степени (Sedlaček, Sychra, 1962; Попов и др., 1966; Williams, Stevens, 1972; Бондарко и др., 1975; Галунов и др., 1975; Курашвили и др., 1975). В ноябре 1974 г. в Ленинграде состоялся 1-й Всесоюзный симпозиум «Речь и эмоции», привлекший многих специалистов разных профилей. Вместе с тем акустические средства выражения эмоций в пении не изучены, и нами сделаны лишь самые первые шаги в этом направлении (Котляр, Морозов, 1975а, 1975б, 1976; Морозов, 1976б).
Основными задачами главы являются: 1) разработка метода количественной оценки эмоциональной выразительности пения разных исполнителей; 2) количественная оценка способностей слушателей к восприятию эмоциональной выразительности вокальной речи; 3) анализ акустических признаков вокально-речевого сигнала, обусловливающих передачу слушателю эмоционального содержания пения.
Выделение любых акустических коррелят эмоциональной выразительности речевого сигнала встречает определенные методические трудности: сложность получения исходного материала, большая вариабельность акустических средств выражения эмоций, зависимость этих средств от лексического материала и т. п.
Известно, что характер эмоциональной выразительности вокального произведения в основном уже предопределен содержанием поэтического текста и музыкой композитора. Однако большой вклад в интерпретацию эмоционального содержания вокального произведения вносит певец-исполнитель. Справедливо поэтому считается, что песню или любое другое вокальное произведение создает триумвират: поэт, композитор и певец. Это положение существенно для обоснования методического подхода, избранного нами в настоящей работе с целью получения экспериментального материала и решения поставленных задач.
2. Метод эмоционально-семантической дивергенции
Для изучения эмоционально-выразительной функции обычной речи применяются четыре основных метода: 1) анализ образцов речи человека, находящегося в естественных эмоциональных состояниях, в частности вызванных стрессовыми условиями; 2) клинический метод, основанный на использовании болезненных психических состояний человека, при которых речь приобретает эмоциональный характер; 3) метод гипнотического внушения эмоционального состояния; 4) метод актерского перевоплощения.
В настоящей работе был использован метод актерского перевоплощения в двух вариантах: 1) метод изучения естественной вокальной речи, т. е. анализ фраз из вокальных произведений, заведомо несущих ту или иную эмоциональную информацию, определяемую содержанием самого произведения и способностями исполнителя; таким методом анализировались акустические средства выражения эмоций в голосе Ф. Шаляпина; 2) метод, названный нами методом эмоционально-семантической дивергенции. Преимуществом первого метода является его естественность. Преимуществом второго – возможность выделить акустические признаки эмоций в наиболее чистом виде.

