


Полная версия
Как предсказать курс доллара. Поиск доходной стратегии с языком R
Мой.Массив[3,3,2]
> Мой.Массив[3,3,2]
[1] 24
Таблицы данных, которые в отличие от матриц могут состоять из различных типов данных, широко используются в R. Таблицы данных создаются при помощи функции data.frame(). Покажем, как это делается на конкретном примере. Сначала создадим три вектора данных, из которых один будет текстовый, а два других цифровых:
> Успеваемость <-c('Отличники', 'Хорошисты' , 'Троечники', 'Двоечники')
> Успеваемость
[1] "Отличники" "Хорошисты" "Троечники" "Двоечники"
> Студенты<-c(2, 5,10,2)
> Студенты
[1] 2 5 10 2
> Студентки <-c(3,7,14,1)
> Студентки
[1] 3 7 14 1
Теперь создаем таблицу с помощью функции data.frame, которую назовем Моя.Таблица:
> Моя.Таблица <– data.frame(Успеваемость,Студенты, Студентки)
> Моя.Таблица
Успеваемость Студенты Студентки
1 Отличники 2 3
2 Хорошисты 5 7
3 Троечники 10 14
4 Двоечники 2 1
# узнаем является ли Моя.Таблица таблицей:
> is.data.frame(Моя.Таблица)
# по-русски: таблица.ли(Моя.Таблица)
[1] TRUE
# по-русски ответ: ИСТИНА, то есть этот объект является таблицей
Далее проверим структуру данных Моя.Таблица с помощью следующей функции:
> str(Моя.Таблица)
# по-русски: структура(Моя.Таблица)
'data.frame': 4 obs. of 3 variables:
$ Успеваемость: Factor w/ 4 levels "Двоечники","Отличники",..: 2 4 3 1
$ Студенты : num 2 5 10 2
$ Студентки : num 3 7 14 1
# по-русски: 'data.frame'– таблица
# 4 obs. of 3 variables – 4 наблюдения из 3 переменных
# знак $ обозначет переменные, включенные в таблицу
# Factor w/ 4 levels – фактор из 4 уровней
# num – количественные данные
Отдельный элемент таблицы можно извлечь, обозначив его положение (номер строки и номер столбца) в квадратных скобках:
> Моя.Таблица[3,1]
[1] Троечники
Levels: Двоечники Отличники Троечники Хорошисты
Внизу из текстового элемента Моя.Таблица есть следующая строка: «Levels: Двоечники Отличники Троечники Хорошисты». Levels в переводе на русский язык означает Уровни. Так называемые «Уровни» (Levels) присваиваются факторам. Фактор – это векторный объект, кодирующий категориальные данные (классы), в состав которых входят как номинальные, так и порядковые данные. Номинальные данные – это качественные данные, которые отражают условные коды количественно не измеряемых категорий, которые также не подлежат ранжированию или упорядочиванию. В качестве примера номинальных данных можно привести индексы отделений связи, поскольку они служат только для их идентификации. По отношению к номинальным данным возможны только операции «равенство-неравенство».
В отличие от номинальных порядковые данные могут быть ранжированы как в порядке убывания, так и увеличения какого-либо их качества. Но в отличие от обычных количественных данных, которые можно выразить в конкретных единицах и к которым можно применить широкий круг алгебраических операций, к порядковым данным можно применить лишь операции «равенство-неравенство», а также «больше-меньше». Порядковые данные используются в том случае, когда порядок ранжирования элементов по какому-то критерию важен, а вот количественные различия между различными рангами этих элементов не поддаются точной оценке.
Например, такие ответы респондентов на вопрос социолога, как: «согласен», «частично согласен», «нет могу сказать, согласен или не согласен», «частично не согласен», «не согласен», – можно ранжировать по степени их согласия или степени их несогласия, в то время как количественную разницу между вариантами этих ответов трудно оценить в каких-то конкретных единицах. Следовательно, эти данные являются порядковыми или ранжируемыми. Впрочем, иногда порядковым данным могут присваиваться какие-то условные порядковые числа, но и в этом случае количественная разница между различными рангами одной и той же последовательности носит весьма условный характер. Например, порядковыми данными являются пятибалльные оценки знаний учащихся, поскольку они не могут быть сгенерированы методом измерения в конкретных единицах, а получены методом достаточно субъективного оценивания.
Созданная нами переменная Успеваемость относится к числу ранжируемых, но по умолчанию уровни фактора в R присваиваются текстовому вектору в алфавитном порядке. Поскольку переменная Успеваемость является порядковой, то такая градация в этом случае не подходит. Поэтому сначала проверим тип данных переменной Успеваемость, а затем присвоим значение различных уровней фактора в порядке возрастания успеваемости с помощью следующей команды:
> class(Успеваемость)
[1] "character"
# тип данных – текстовый
> Успеваемость <– factor(Успеваемость, order=TRUE, levels=c('Двоечники', 'Троечники', 'Хорошисты', 'Отличники'))
# превращает вектор Успеваемость в упорядоченный фактор
# число уровней фактора задается при помощи аргумента levels
> Успеваемость
[1] Отличники Хорошисты Троечники Двоечники
# уровни фактора в порядке их возрастания
Levels: Двоечники < Троечники < Хорошисты < Отличники
> class(Успеваемость)
[1] "ordered" "factor"
# тип данных – упорядоченный фактор
Список в R представляет собой упорядоченный набор объектов с различными типами данных. В результате под одним своим именем списки могут включать векторы, матрицы, таблицы и другие списки. Список можно создать при помощи функции list():
> Мой.Список <– list(Моя.Таблица, Успеваемость, Матрица1,Матрица2)
# по-русски: Мой.Список <– список(Моя.Таблица, Успеваемость, Матрица1,Матрица2)
> Мой.Список
[[1]]
Успеваемость Студенты Студентки
1 Отличники 2 3
2 Хорошисты 5 7
3 Троечники 10 14
4 Двоечники 2 1
[[2]]
[1] Отличники Хорошисты Троечники Двоечники
Levels: Двоечники < Троечники < Хорошисты < Отличники
[[3]]
[,1] [,2] [,3] [,4] [,5]
[1,] 1 4 7 10 13
[2,] 2 5 8 11 14
[3,] 3 6 9 12 15
[[4]]
[,1] [,2] [,3]
[1,] 1 6 11
[2,] 2 7 12
[3,] 3 8 13
[4,] 4 9 14
[5,] 5 10 15
Теперь проверим структуру данных Моя.Таблица с помощью следующей функции:
> str(Мой.Список)
List of 4 # список из объектов
$ :'data.frame': 4 obs. of 3 variables:
..$ Успеваемость: Factor w/ 4 levels "Двоечники","Отличники",..: 2 4 3 1
..$ Студенты : num [1:4] 2 5 10 2
..$ Студентки : num [1:4] 3 7 14 1
$ : Ord.factor w/ 4 levels "Двоечники"<"Троечники"<..: 4 3 2 1
$ : int [1:3, 1:5] 1 2 3 4 5 6 7 8 9 10 …
$ : num [1:5, 1:3] 1 2 3 4 5 16 17 8 19 20 …
# характеризуется тип данных по каждой переменной $ (объекту) списка
Теперь попробуем поработать в RStudio как с обычным калькулятором. С этой целью подсчитаем, насколько вырос курс американского доллара к рублю по итогам торгов 17 декабря 2014 года. Обратите внимание, что при работе с языком R дробная часть числа отделяется точкой, а не запятой.
Согласно данным Банка России, официальный курс доллара США, установленный на 18 декабря 2014 г., равнялся 67.7851 руб. Поскольку Центробанк каждый рабочий день по итогам утренних торгов на Московской межбанковской валютной биржи устанавливает официальные курсы валют, которые вступают в силу лишь на следующий день, то, следовательно, официальный курс доллара на 18 декабря 2014 г. по сути является его текущим курсом по итогам торгов, прошедших 17 декабря 2014 г. В свою очередь, по итогам торгов от 16 декабря 2014 г. курс доллара равнялся 61.1512 руб., а потому к моменту их закрытия 17 декабря 2014 г. американская валюта подорожала до 67.7851 руб.
Давайте с помощью R поработаем с этими цифрами. Для того, чтобы выяснить, например, насколько рублей и во сколько раз за один день подорожала американская валюта, нужно, во-первых, от второй цифры отнять первую, а, во-вторых, вторую цифру поделить на первую. Иначе говоря, нам необходимо выполнить два следующих простейших действия: 1). 67.7851 – 61.1512 и 2). 67.7851/61.1512.
С этой целью последовательно щелкнем мышкой в верхней левой части RStudio по опциям File/New File/R Script, а затем введем с клавиатуры вышеуказанные цифры и алгебраические символы в редакторе кода. Затем выделим их мышкой и нажмем на клавиатуре кнопки Ctrl и Enter (Ввод). В результате в консоли (нижней левой части) RStudio появятся не только введенные нами математические выражения, но и ответы – см. рис. 3. Отправить на консоль эти выражения можно также последовательно щелкнув в верху, в левой части RStudio, по опциям Code/ Run Selected Line(s) (Код/Отправить на консоль выбранные строки).
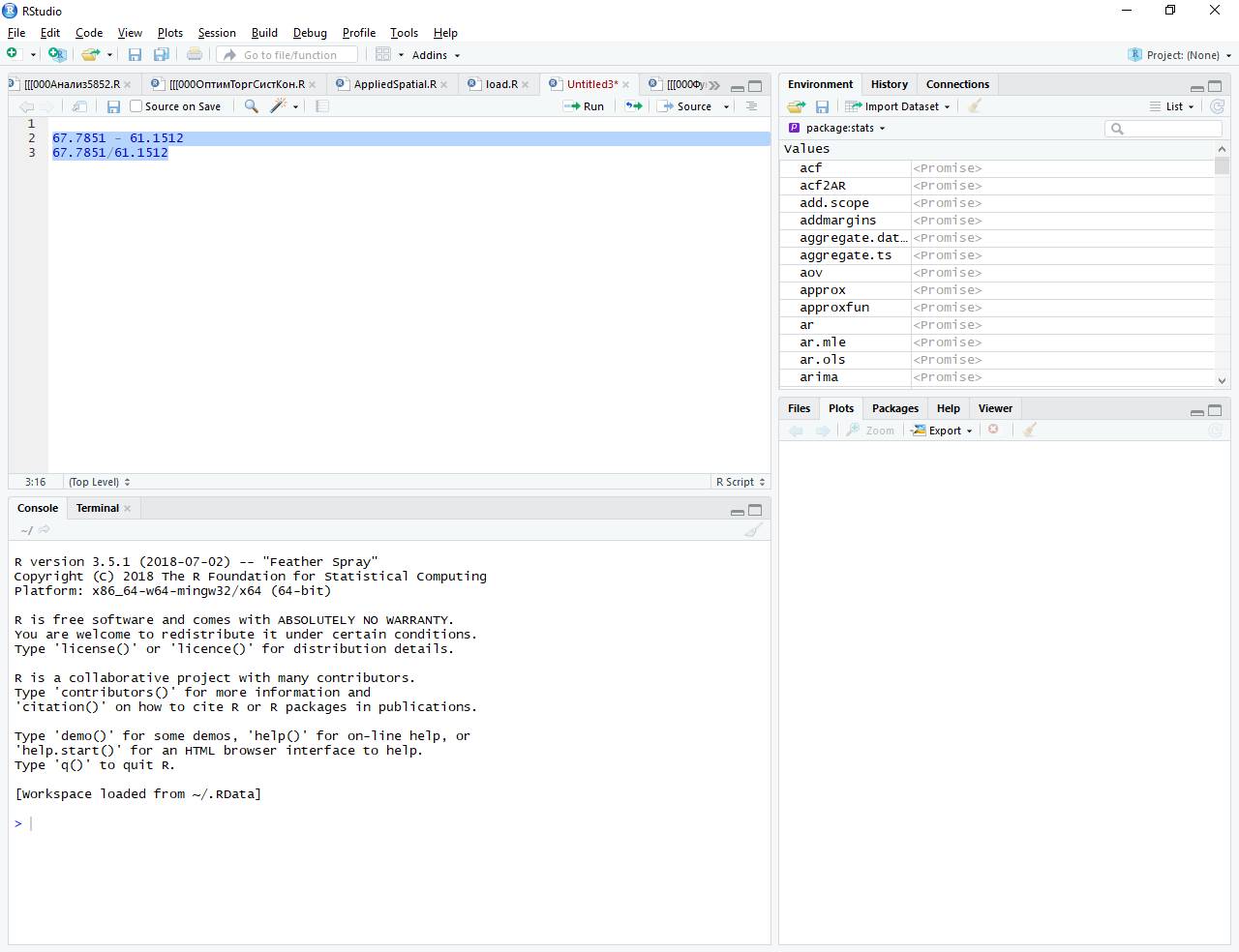
Рис. 3
В результате в консоли появятся следующие два выражения:
> 67.7851 – 61.1512
[1] 6.6339
> 67.7851/61.1512
[1] 1.108484
При этом после символа > в начале абзаца даны введенные нами в редакторе кода выражения, а после [1] даются полученные ответы: [1]6.6339 и [1] 1.108484. Таким образом по итогам утренних торгов, прошедших 17 декабря 2014 г., курс доллара вырос на 6.6339 руб. или в 1.108484 раза. Почему выводимые результаты в R начинаются с [1]? Это объясняется тем, что R по умолчанию рассматривает любые данные как массив данных. В данном случае выводимое число – это состоящий из одного элемента вектор, который и нумеруется соответствующей порядковой цифрой [1]. В том случае, когда вектор состоит из множества элементов, занимающих сразу несколько строк, тогда в начале каждой строки в квадратных скобках выдается порядковый номер (подсчет ведется от начала вектора) первого элемента каждой строки.
В R помимо уже использовавшихся нами для вычитания и деления символов « – » и « / » применяются также символы «+», «*», «^» (или «**»), соответственно, для сложения, умножения и возведения в степень. Например, если умножить число 1.108484 на 100 и отнять 100, то тогда получим: 1.108484*100 -100=10. 8484%. Таким образом с помощью этой операции мы выясним, что по итогам утренних торгов, прошедших 17 декабря 2014 г., курс доллара по сравнению с торгами предыдущего дня вырос на 10. 85%.
R имеет встроенную систему помощи, которая содержит подробные разъяснения, а также ссылки на литературу и примеры для каждой функции из установленных пакетов. Правда, все эти справки даются на английском языке. Например, если пользователь хочет получить справку по функции lm, с помощью которой в R решаются уравнения регрессии, то с этой целью ему надо ввести команду ?lm, либо help(lm). В результате он получит справочный файл по этой функции. Но если пользователю необходимо получить информацию об этой функции, содержащуюся во всех имеющихся справочных файлах, то в этом случае надо ввести команду help.search (lm) или ??lm.
Команда example(lm) дается в том случае, когда пользователь хочет ознакомиться с конкретными примерами по работе с этой функцией, с ее помощью можно также ознакомиться и с примерами по другим функциям, если внутри скобок вместо lm указать их название. Команда RSiteSearch(“lm”) позволяет получить справочные материалы по функции lm, имеющиеся в онлайн-руководствах и в заархивированных рассылках. Команда apropos("lm", mode="function") даст список всех функций, в которых есть название lm. Вполне естественно, что если в скобках после apropos вместо lm указать, например, foo, то тогда можно получить аналогичную информацию о foo. Список всех доступных руководств по загруженным пакетам можно получить с помощью команды vignette(). Ну а если запустить команду help.start(), то в правой нижней части RStudio появится обширная справочная литература по R. В первую очередь, из этого списка пользователю, знающему английский язык, можно посоветовать внимательно познакомиться с пособием «An Introduction to R» («Введение в язык R»). Кроме того, тем, кто владеет английским языком, весьма полезно будет также проштудировать еще и книгу Andrie de Vries, Joris Meys «R For Dummies» (Андри де Фриз, Джорис Мейс «R для чайников»), в которой весьма доступно излагаются основные азы работы с языком.
Конец ознакомительного фрагмента.
Текст предоставлен ООО «ЛитРес».
Прочитайте эту книгу целиком, купив полную легальную версию на ЛитРес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.







