


Полная версия
Нейронные сети. Эволюция
Приращение:
∆s = s(t+∆t) – s(t) = t + ∆t – t = ∆t
Производная:
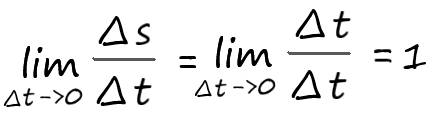
Получается, что производная от переменной:
t′ = 0
Правила дифференцирования и дифференцирование сложных функций
Дифференцирование суммы
(u+v)′ = u′ + v′, где u и v – функции.
Пусть f(x) = u(x) + v(x). Тогда:
∆f = f(x+∆x) – f(x) = u(x+∆x) + v(x+∆x) – u(x) – v(x) = u(x) + ∆u + v(x) + ∆v – u(x) – v(x) = ∆u + ∆v
Тогда имеем:

Дроби ∆u/∆х и ∆v/∆х при ∆х->0 стремятся соответственно к u′(x) и v′ (x). Сумма этих дробей стремится к сумме u′(x) + v′ (x).
f′(x) = u′ (x) + v′ (x)
Дифференцирование произведения
(u*v)′ = u′ v + v′u, где u и v – функции
Разберем, почему это так. Обозначим f(x) = u(x) * v(x). Тогда:
∆f = f(x+∆x) – f(x) = u(x+∆x) * v(x+∆x) – u(x) * v(x) = (u(x) + ∆u) * (v(x) + ∆v) – u(x) * v(x) = u(x)v(x) + v(x)∆u + u(x)∆v + ∆u∆v – u(x)v(x) = v(x)∆u + u(x)∆v + ∆u∆v
Далее имеем:
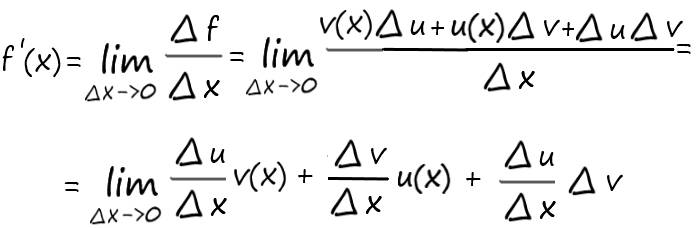
Первое слагаемое стремиться к u′(x) v(x). Второе слагаемое стремиться к v′(x)* u(x). А третье, в дроби ∆u/∆x, в пределе даст число u′(x), а поскольку множитель ∆v стремиться к нулю, то и вся эта дробь обратится в ноль. А следовательно, в результате получаем:
f′(x) = u′ (x) v(x) + v′ (x) u(x)
Из этого правила, легко убедиться, что:
(c*u)′ = c′ u + c u′ = c u′
Поскольку, с – константа, поэтому ее производная равна нулю (c′ = 0).
Зная это правило мы без труда, найдем изменение скорости второго примера.
Применим к выражению правило дифференцирование суммы:
s′ (t) = (0,2t) ′ + (1,5) ′
Теперь по порядку, возьмём выражение – (0,2t) ′. Как брать производную произведения константы и переменной мы знаем:
(0,2t) ′ = 0,2
А производная самой константы равна нулю – (1,5) ′ = 0.
Следовательно, скорость изменения скорости, второго примера:
s′ (t) = 0,2
Что совпадает с нашим ответом, полученном ранее во втором примере.
Дифференцирование сложной функции
Допустим, что в некоторой функции, y сама является функцией:
f = y²
y = x²+x
Представим дифференцирование этой функции в виде:
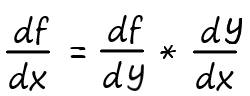
Нахождение производной в этом случае, осуществляется в два этапа.
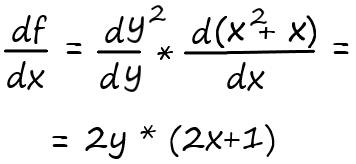
Мы знаем, как решить производную типа: dy²/dy = 2y
А также знаем, как решать производную суммы: х² + х = (х²)′ + х′ = 2х+1
Тогда:
2(x²+x) * (2х+1) = (2х²+2х) * (2х+1) = 4х³+6х²+2х
Я надеюсь, вам удалось понять, в чем состоит суть дифференциального исчисления.
Используя описанные, методы дифференцирования выражений, вы сможете понять механизм работы метода градиентного спуска.
В качестве небольшого дополнения, приведу список наиболее распространённых табличных производных:
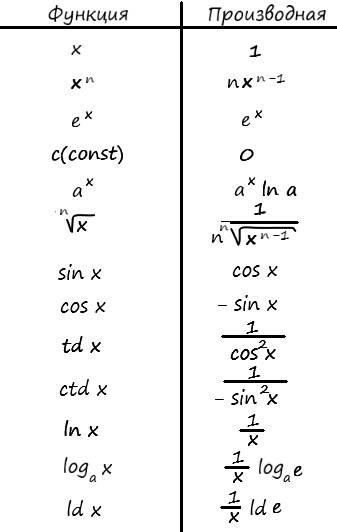
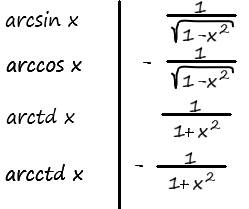

Зачем нам дифференцировать функции
Еще раз вспомним как мы спускаемся по склону. Что в кромешной тьме, мы хотим попасть к его подножью, имея в своем арсенале слабенький фонарик.
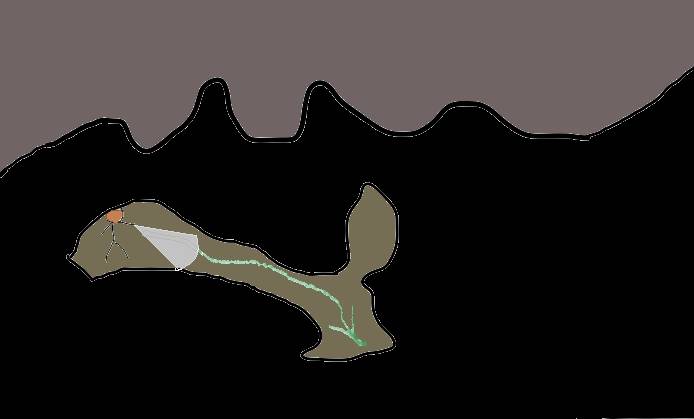
Опишем эту ситуацию, по аналогии с математическим языком. Для этого проиллюстрируем график метода градиентного спуска, но на этот раз применительно к более сложной функции, зависящей от двух параметров. График такой функции можно представить в трех измерениях, где высота представляет значение функции:
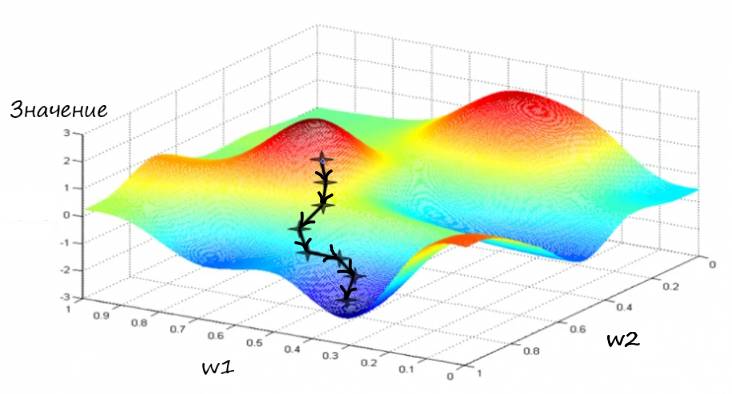
К слову, отобразить визуально такую функцию, с более чем двумя параметрами, как видите, будет довольно проблематично, но идея нахождения минимума методом градиентного спуска останется ровно такой же.
Этот слайд отлично показывает всю суть метода градиентного спуска. Очень хорошо видно, как функция ошибки объединяет весовые коэффициенты, как она заставляет работать их согласованно. Двигаясь в сторону минимума функции ошибки, мы можем видеть координаты весов, которые необходимо изменять в соответствии с координатами точки – которая движется вниз.
Представим ось значение, как ось ошибка. Очень хорошо видно, что функция ошибки общая для всех значений весов. Соответственно – координаты точки значения ошибки, при определенных значениях весовых коэффициентов, тоже общие.
При нахождении производной функции ошибки (угол наклона спуска в точке), по каждому из весовых коэффициентов, находим новую точку функции ошибки, которая обязательно стремиться двигаться в направлении её уменьшения. Тем самым, находим вектор направления.
А обновляя веса в соответствии со своим входом, на величину угла наклона, находим новые координаты этих коэффициентов. Проекции этих новых координат на ось ошибки (значение низ лежащей точки на графике), приводят в ту самую новую точку функции ошибки.
Как происходит обновление весовых коэффициентов?
Для ответа на этот вопрос, изобразим наш гипотетический рельеф в двумерной плоскости (гипотетический – потому что функция ошибки, зависящая от аргумента весовых коэффициентов, нам не известна). Где значение высоты будет ошибка, а за координаты по горизонтали нахождения точки в данный момент, будет отвечать весовой коэффициент.
Тьму, через которую невозможно разглядеть даже то, что находится под ногами, можно сравнить с тем, что нам не известна функция ошибки. Так как, даже при двух, постоянно изменяющихся, параметрах неизвестных в функции ошибки, провести её точную кривую на координатной плоскости не представляется возможным. Мы можем лишь вычислить её значение в точке, по весовому коэффициенту.
Свет от фонаря, можно сравнить с производной – которая показывает скорость изменения ошибки (где в пределах видимости фонаря, круче склон, чтоб сделать шаг в его направлении). Следуя из основного понятия производной – измерения изменения одной величины, когда изменяется вторая, применительно к нашей ситуации, можно сказать что мы измеряем изменение величины ошибки, когда изменяются величины весовых коэффициентов.
А шаг, в свою очередь, отлично подходит на роль обновления нашего весового коэффициента, в сторону уменьшения ошибки.
Вычислив производную в точке, мы вычислим наклон функции ошибки, который нам нужно знать, чтобы начать градиентный спуск к минимуму:
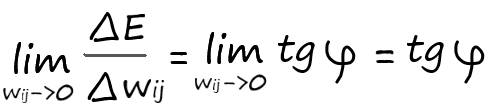
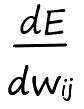
Ij – определитель веса, в соответствии со своим входом. Если это вход x1 – то его весовой коэффициент обозначается как – w11, а у входа х2 – обозначается как -w21. Чем круче наклон касательной, тем больше скорость изменения ошибки, тем больше шаг.
Запишем в явном виде функцию ошибки, которая представляет собой сумму возведенных в квадрат разностей между целевым и фактическим значениями:
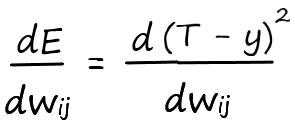
Разобьем пример на более простые части, как мы это делали при дифференцировании сложных функций:
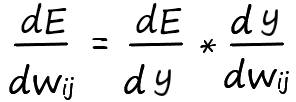
Продифференцируем обе части поочередно:
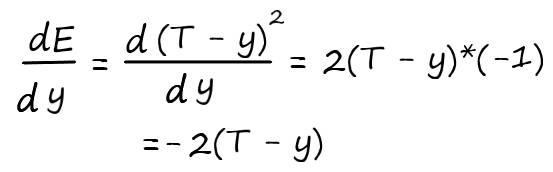
Так как выход нейрона – f(x) = y, а взвешенная сумма – у = ∑I wij*xi, где xi – известная величина (константа), а весовые коэффициенты wij – переменная, производная по которой, дает как мы знаем единицу, то взвешенную сумму можно разбить на сумму простых множителей:

Откуда нетрудно найти:
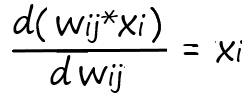
Значит, для того чтобы обновить весовой коэффициент по своей связи:
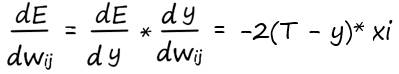
Прежде чем записать окончательный ответ, избавимся от множителя 2 в начале выражения. Мы спокойно можем это сделать, поскольку нас интересует только направление градиента функции ошибки. Не столь важно, какой множитель будет стоять в начале этого выражения, 1, 2 или любой другой (лишь немного потеряем в масштабировании, направление останется прежним). Поэтому для простоты избавимся от неё, и запишем окончательный вид производной ошибки:
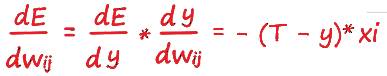
Всё получилось! Это и есть то выражение, которое мы искали. Это ключ к тренировке эволюционировавшего нейрона.
Как мы обновляем весовые коэффициенты
Найдя производную ошибки, вычислив тем самым наклон функции ошибки (подсветив фонариком, подходящий участок для спуска), нам необходимо обновить наш вес в сторону уменьшения ошибки (сделать шаг в сторону подсвеченного фонарем участка). Затем повторяем те же действия, но уже с новыми (обновлёнными) значениями.
Для понимания как мы будем обновлять наши коэффициенты (делать шаги в нужном направлении), прибегнем к помощи так уже нам хорошо знакомой – иллюстрации. Напомню, величина шага зависит от крутизны наклона прямой (tgφ). А значит величина, на которую мы обновляем наши веса, в соответствии со своим входом, и будет величиной производной по функции ошибки:
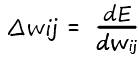
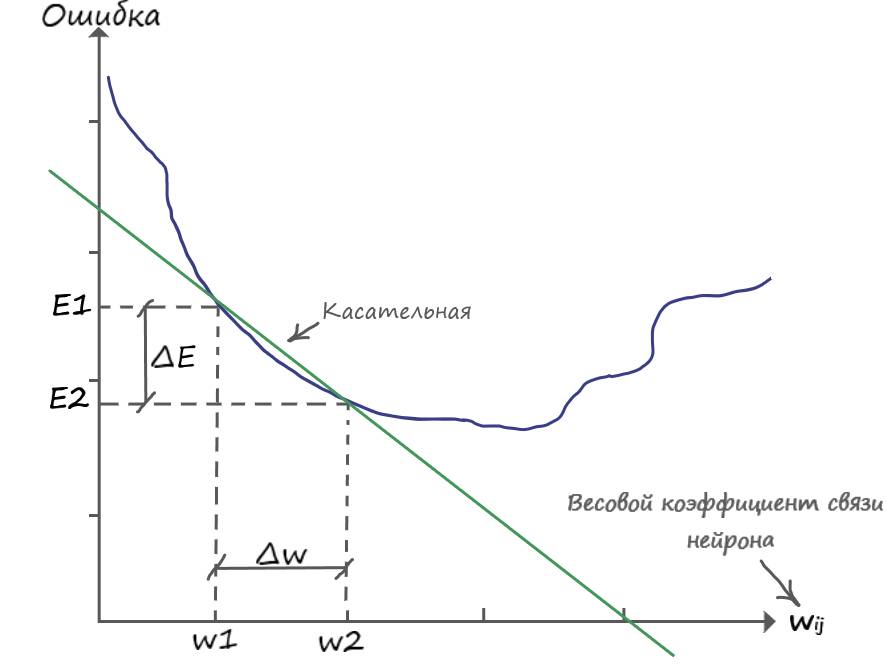
Вот теперь иллюстрируем:
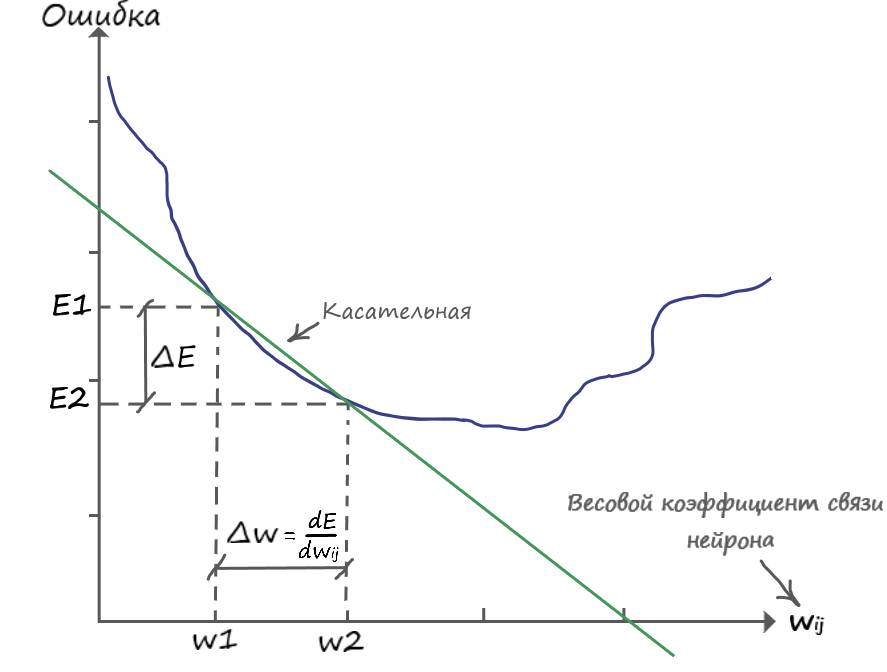
Из графика видно, что для того чтобы обновить вес в большую сторону, до значения (w2), нужно к старому значению (w1) прибавить дельту (∆w), откуда: (w2 = =w1+∆w). Приравняв (∆w) к производной ошибки (величину которой уже знаем), мы спускаемся на эту величину в сторону уменьшения ошибки.
Так же замечаем, что (E2 – E1 = -∆E) и (w2 – w1 = ∆w), откуда делаем вывод:
∆w = -∆E/∆w
Ничего не напоминает? Это почти то же, что и дельта линейного классификатора (∆А = E/х), подтверждение того что наша эволюция прошла с поэтапным улучшением математического моделирования. Таким же образом, как и с обновлением коэффициента (А = А+∆А), линейного классификатора, обновляем весовые коэффициенты:
новый wij = старый wij -(– ∆E/∆w)
Знак минус, для того чтобы обновить вес в большую сторону, для уменьшения ошибки. На примере графика – от w1 до w2.
В общем виде выражение записывается как:
новый wij = старый wij – dE/dwij
Еще одно подтверждение, постепенного, на основе старого аппарата, хода эволюции, в сторону улучшения классификации искусственного нейрона.
Теперь, зайдем с другой стороны функции ошибки:

Снова замечаем, что (E2 – E1 = ∆E) и (w2 – w1 = ∆w), откуда делаем вывод:
∆w = ∆E/∆w
В этом случае, для обновления весового коэффициента, в сторону снижения функции ошибки, а значит до значения находящееся левее (w1), необходимо от значения (w1) вычесть дельту (∆w):
новый wij = старый wij - ∆E/∆w
Получается, что независимо от того, какого знака производная ошибки от весового коэффициента по входу, вычитая из старого значения – значение этой производной, мы движемся в сторону уменьшения функции ошибки. Откуда можно сделать вывод, что последнее выражение, общее для всех возможных случаев обновления градиента.
Запишем еще раз, обновление весовых коэффициентов в общем виде:
новый wij = старый wij – dE/dwij
Но мы забыли еще об одной важной особенности… Сглаживания! Без сглаживания величины дельты обновления, наши шаги будут слишком большие. Мы подобно кенгуру, будем прыгать на большие расстояния и можем перескочить минимум ошибки! Используем прошлый опыт, чтоб устранить этот недочёт.
Вспоминаем старое выражение при нахождении сглаженного значения дельты линейного классификатора: ∆А = L*(Е/х). Где (L) – скорость обучения, необходимая для того, чтобы мы делали спуск, постепенно, небольшими шашками.
Ну и наконец, давайте запишем окончательный вариант выражения при обновлении весовых коэффициентов:
новый wij = старый wij – L*(dE/dwij)
Еще раз можем убедиться, в постепенном улучшении свойств, в ходе эволюции искусственного нейрона. Много из того что реализовывали ранее остается, лишь небольшая часть подверглась эволюционному улучшению.
Ложный минимум
Если еще раз взглянуть на трехмерную поверхность, можно увидеть, что метод градиентного спуска может привести в другую долину, которая расположена правее, где минимум значения будет меньше относительно той долины, куда попали мы сейчас, т.е. эта долина не является самой глубокой.
На следующей иллюстрации показано несколько вариантов градиентного спуска, один из которых приводит к ложному минимуму.
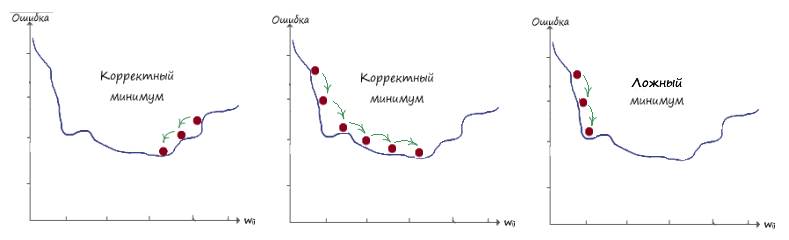
Поздравляю! Мы прошли самую основу в теории нейронных сетей – метод градиентного спуска. Освоив этот материал, в дальнейшем, изучение теории искусственных нейронных сетей, не будет представлять для вас значимого труда.
Как работает эволюционировавший нейрон
Ну вот и настало время проверить практически, все наши умозаключения, касающиеся работы нашего искусственного нейрона, после первой эволюции. Для этого прибегнем к помощи Python, но сначала покажем наш список с данными, с которого мы это всё затеяли:
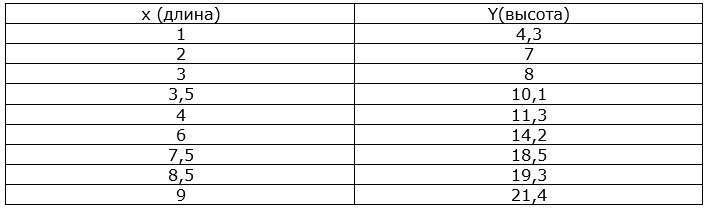
Если по координатам построить точки на плоскости, то мы заметим, что их значения лежат возле значений графика функции – y = 2x + 2,5.
Программа
import random
# Инициализируем любым числом крутизны наклона прямой w1 = A
w1 = 0.4
w1_vis = w1 # Запоминаем начальное значение крутизны наклона
# Инициализируем параметр w2 = b – отвечающий за точку прохождения прямой через ос Y
w2 = random.uniform(-4, 4)
w2_vis = w2 # Запоминаем начальное значение параметра
# Вывод данных начальной прямой
print('Начальная прямая: ', w1, '* X + ', w2)
# Скорость обучения
lr = 0.001
# Зададим количество эпох
epochs = 3000
# Создадим массив (выборку входных данных) входных данных x1
arr_x1 = [1, 2, 3, 3.5, 4, 6, 7.5, 8.5, 9]
# Значение входных данных второго входа всегда равно 1
x2 = 1
# Создадим массив значений (целевых значений)
arr_y = [4.3, 7, 8.0, 10.1, 11.3, 14.2, 18.5, 19.3, 21.4]
# Прогон по выборке
for e in range(epochs):
for i in range(len(arr_x1)): # len(arr) – функция возвращает длину массива
# Получить x координату точки
x1 = arr_x1[i]
# Получить расчетную y, координату точки
y = w1 * x1 + w2
# Получить целевую Y, координату точки
target_Y = arr_y[i]
# Ошибка E = -(целевое значение – выход нейрона)
E = – (target_Y – y)
# Меняем вес при x, в соответствии с правилом обновления веса
w1 -= lr * E * x1
# Меняем вес при x2 = 1
#w2 -= rate * E * x2 # Т.к. x2 = 1, то этот множитель можно не писать
w2 -= lr * E
# Вывод данных готовой прямой
print('Готовая прямая: ', w1, '* X + ', w2)
Данный код, как и все другие, вы можете скачать по ссылке: https://github.com/CaniaCan/neuralmaster
Опишем код программы:
В самом начале программы импортируем модуль для работы со случайными числами:
import random
При помощи которого, случайным числом, создаем весовой коэффициент параметра (w2 = b) – отвечающий за точку прохождения прямой через ос Y:
w2 = random.uniform(-4, 4)
Метод модуля random – uniform(from, to), генерирует случайное вещественное число от from до to включительно.
В нашей программе, как видно, не так много изменений, по сравнению с той что мы написали до этого. Мы добавили второй вход (х2 = 1), со своим весовым коэффициентом (w2). Коэффициент (А) – переименовали в весовой коэффициент (w1), параметр (b) – в весовой коэффициент (w2). Ну и конечно же, реализовали новую улучшенную функцию ошибки, и обновление весовых коэффициентов по методу градиентного спуска.
В результате чего, наш эволюционировавший нейрон, теперь гораздо лучше справляется с задачей классификации. Теперь он может классифицировать данные по двум входам, тем самым получая линейный классификатор с пересечением прямой по всей оси Y, а не только строго в точке нуля.
Давайте взглянем на результат чтобы убедиться в этом: