

Полная версия
Основы нейросетей

1 Где можно поучиться AI?
Чтож. Теперь, когда пассивный доход от издания книг (это еще не сарказм) сделал избыточной работу в найме (а вот и он), приступаю ко 2-му этапу диджитал-трансформации.
Посоветуйте, где лучше поучиться AI, ML, нейронным сетям, обработке BigData, AR/VR, компьютерному зрению и всему такому. Самостоятельно изучать тему неэффективно – быстро выгораю, становится скучно, нужен надсмотрщик с плеткой.
Интересуют практические знания. Чтобы после курса уметь писать приложения вида PRISM или MSQRD. Ну или которые смогут отличить кошку от собаки, написать новую шутку или предсказать курс $ на неделю вперед.
В любом случае интересны проекты, основанные на легко доступных больших данных. Это данные в личном смартфоне (звонки, микрофон, геопозиция, камера), на своем ПК (файлы, почта, интересы), Интернет (вики, карты, анекдоты, ютуб, соцсети?), массовая литература. Какие еще открытые бигдата есть?
Что точно не интересно – делать проект, заточенный под данные или API определенной компании. Это телекомы, банки, логистика, магазины, интернет-холдинги или соцсети.
Бигдата у них, конечно, есть, но:
1) Фиг они ими поделятся (если это вообще законно – выдавать наружу данные, даже обезличенные).
2) Фиг они что-то у тебя купят. Как-то не принято это здесь. Да и бизнес-смысла в этом нет. Проще тупо украсть наработки, сделать свой велосипед или максимум предложить работу команде. Даже в случае успешного пилота с корпорацией это довольно слабая переговорная позиция – когда данные у компании, а у тебя лишь обученная на их основе нейросеть (алгоритм обработки данных) и проведенный кастдев. Они без тебя жить смогут, а ты без них нет.
Есть конечно кейс – знать, что нужно большой компании, сделать это на стороне и продать наработки компании. Бобук говорил, что он так сделал механизм распознавания людей на фотках и продал это VK/OK. Им это нужно чтобы автоматически тэгать людей. Это повышает вовлечение юзеров и время зависания на сайте. Но это скользкий путь:
1) Неясно, что нужно корпам.
2) Не факт, что они прямо сейчас не делают такую штуку.
3) Не факт, что эту штуку сможешь сделать ты.
4) Не факт, что готовое решение купит корп. Они любят тянуть время (приходите через год, на сегодня все бюджеты освоены).
Думаю, по деньгам у Григория получилось так. Команда 5 чел, ЗП 4 тыс $/мес, делать такую штуку ~10 мес. Себестоимость 200 тыс $. Продать корпорации с премией 3-5х можно за 0.6-1 млн $.
Какие курсы по data science и нейронным сетям нагуглил и рассматриваю:
1) Машинное обучение и анализ данных – Яндекс, МФТИ, Курсера, 5500 руб/мес, 250 часов.
2) Data science – SkillFactory, 120 тыс руб, 12 мес.
3) Data scientist – Нетология, 200 тыс руб, 8 мес.
4) Введение в машинное обучение – Яндекс, ВШЭ, Курсера, бесплатно, 35 часов.
5) Introduction to Machine Learning – Google, бесплатно, 15 часов.
https://developers.google.com/machine-learning/crash-course
6) Ваш вариант?
Месяца 4 назад начинал проходить курс #5 от Гугл, но через 2 недели бросил. Все-таки, мне нужен кто-то, кто будет пинать и мотивировать продолжать обучение.
Что посоветуете?


Источник фото
Источник фото
Источник фото
Также, см. https://en.wikipedia.org/wiki/Applications_of_artificial_intelligence
Источник фото
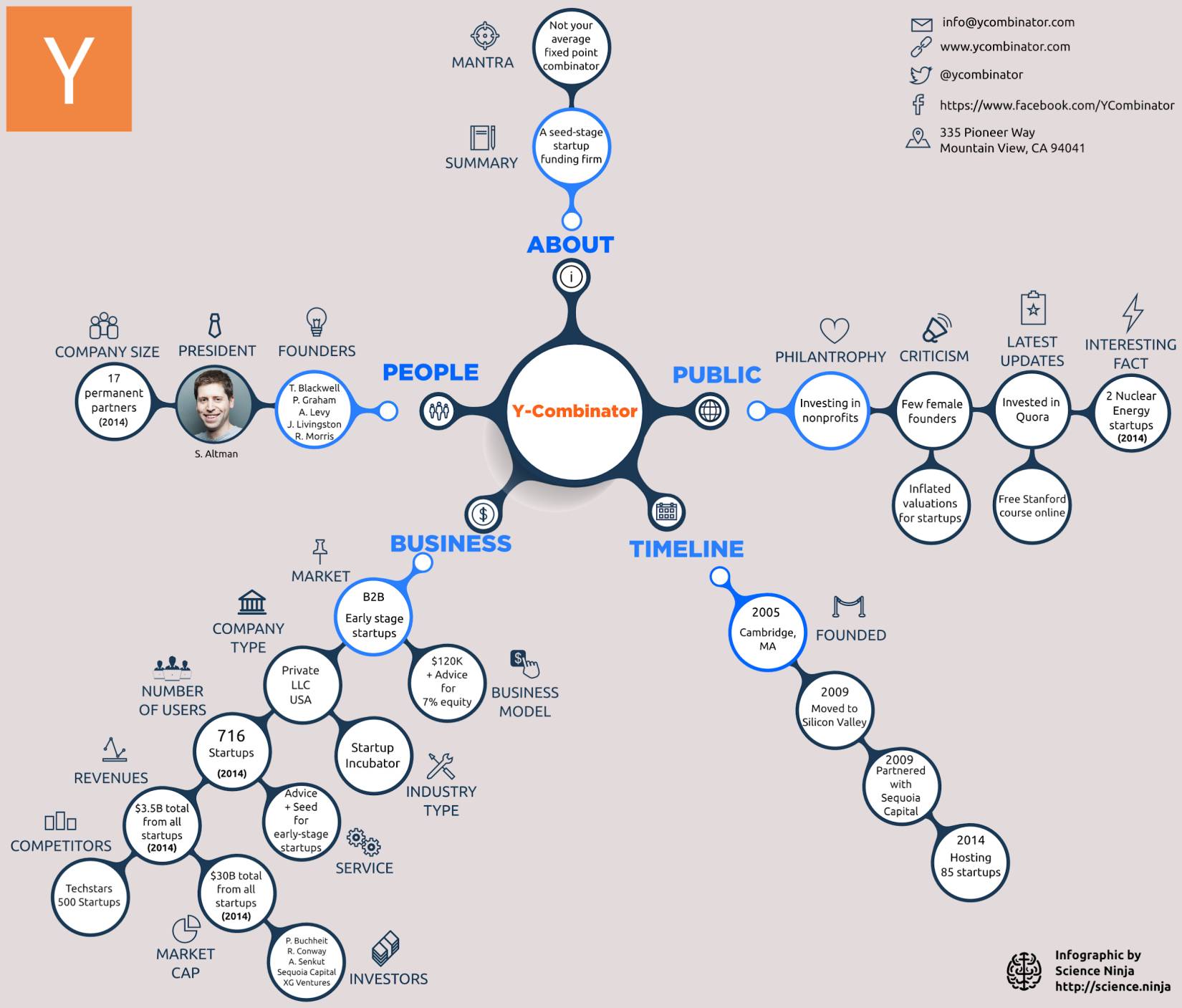
2 Венчурная аналитика AI-проектов
Насчет выбора курса по AI (см. предыдущий пост). При выборе темы учебного проекта, думаю, стоит ориентироваться на AI-проекты, получившие инвестиции в последнее время. Ниже последние AI-проекты ФРИИ, YC, 500 Startups и TechStars.
Т.к. дальше будет лонгрид и много описаний проектов, вынесу наверх мысли насчет проектов YC:
1) США новый Вавилон. В последнем наборе Summer 2019 – 175 компаний 27 стран. США, Европа, Азия, ЛатАм, даже Африка. России нет, но есть Украина. Никаких других центров стартапов как-будто нет.
2) Идея брать 7% за $120К от 175 потенциально прорывных компаний каждые полгода может быть невероятно прибыльной. Чисто по статистике 3-5 единорогов у них получится. Похоже, у YC нет никаких проблем со сбором $$$ на финансирование очередного набора фонда. Возможно в РФ с венчуром проблема не в рынке, недостатке инвесторах, политике и др, а тупо просто нет столько людей-предпринимателей кто хочет сделать свой проект.
3) Похоже, венчур в России в глубокой ж. 11 vs 175 стартапов (ФРИИ vs YC) в последнем наборе. Много стартапов во ФРИИ – унылые локальные проекты без полета фантазии, которые никогда не выйдут на внешний рынок и не станут единорогами. Онлайн ГИБДД, Помощник в исполнении 149-ФЗ по безопасности данных, оборудование для соляных пещер :-( Зачем это вообще?
4) Очень крутые проекты YC с миллионной выручкой, понятной бизнес-моделью, не боятся испачкать руки. Многие проекты для узкой аудитории – мигранты-айтишники, венесуэльцы, наркоманы, женщины, секс-фетишисты, гики.
5) В YC классные описания проектов. В одном абзаце донесена суть, главные цифры, команда, перспективы. Можно за час прочитать описание всех 175 проектов в наборе и принять инвестиционное решение.
6) AI не волшебная пилюля. Во многих проектах AI упомянута только для галочки. Весь цимес в хорошем удовлетворении реального спроса, бизнес-модели и перспективах (растущие тренды, взрывной рост какой-либо характеристики 1-10 тыс раз).
7) Главное в стартапах YC – бабло, а не красивая идея или хайповый набор технологий. Клеить танчики умеют многие, важно осознанно и к месту их клеить.
8) Блин, какие они крутые! Проекты по продаже марихуаны через дроны, создание новых лекарств, VR для хирургов, запись инфо в ДНК, запуск орбитальных спутников – легко. Начитались, твари, Жюль Верна, никаких тормозов! Походу Илон Маск там еще не самый упоротый :-)
Итак, AI-проекты ведущих акселераторов.
1) ФРИИ набор #19, 3 Октября 2019 (11 проектов):
https://www.iidf.ru/media/articles/accelerator/19-nabor-akseleratora/
Leveli.ng (Казань) – AI-сервис для автоматизации работы с отзывами пользователей в интернете. Сервис автоматически обрабатывает, генерирует и публикует ответы на отзывы по разным сценариям: нивелирование негатива, нейтрализация отзыва, работа с постоянными клиентами.
2) ФРИИ набор #18, 1 Июля 2019 (19 проектов):
https://www.iidf.ru/media/articles/accelerator/v-18-nabor-akseleratora/
Clover Group (Москва) – разработчик решений в области прогнозного обслуживания для промышленных предприятий с применением технологий искусственного интеллекта, машинного обучения и предиктивной аналитики.
FoхTail (Ростов-на-Дону) – онлайн-платформа для формирования и управления распределенной командой разработки. Заказчики IT-услуг и аутсорсинговые компании благодаря умному поиску, основанному на big data и machine learning, смогут быстро находить подходящих проверенных специалистов, а с помощью инструментов совместной работы управлять проектом.
Music Scan (Москва) – сервис, используя технологии Big Data, помогает правообладателям пресекать нелегальное использование аудио-произведений, увеличивать размер вознаграждений за использование контента и системно выстраивать стратегию продвижения произведений на музыкальном рынке.
Инфобот (Уфа) – телефонный робот, которого не отличить от человека. Инфобот может отвечать на входящие и делать исходящие звонки, полностью распознает человеческую речь и на основание диалога принимает решение о следующем действие.
3) YC Summer 2019 Batch (175 companies):
https://blog.ycombinator.com/yc-summer-2019-batch-stats/
https://techcrunch.com/2019/08/19/all-84-startups-from-y-combinators-s19-demo-day-1/
https://techcrunch.com/2019/08/20/here-are-the-82-startups
Intersect Labs: Intersect Labs is building CoreML for enterprise, letting its customers easily build machine learning models to help make sense of their historical data and deliver insights without having to hire data scientists. The monthly subscription is aiming to deliver a product that doesn’t require much technical knowledge. “If you can use a spreadsheet, you can use Intersect Labs.”
Traces: As privacy-conscious consumers speak up against the proliferation of facial recognition tech, there’s still a clear need for a product that enables smart camera tracking for customers. Traces is building computer vision tracking tech that relies on cues other than facial structure like clothing and size to help customers integrate less invasive tracking tech. It was built by former Ring engineers.
Soteris: Soteris is a startup building machine learning software for insurance pricing. Within siх months of their pilot, they already have two insurers under contract, giving them $500K in guaranteed annual revenue.
Well Principled: This is an AI-driven management consultant that says it wants to “replace MBAs with software.” Companies spend $200 billion on management consultants every year. Well Principled wants to replace that eхpensive and cumbersome system with its tech that has culled growth and revenue learnings from academic research and turned it into enterprise software. The company wants to eliminate the need for outside consultants by integrating its software into the daily operations of businesses as they launch new products. Well Principled is advised and invested in by early Palantir leaders, and claims $840,000 ARR from its first Fortune 200 customer.
Dashblock: Dashbloack creates APIs from any web page using machine learning. Drop in a URL, select the data you want from a page, and it will figure out how to automatically eхtract it and provide it via API. It has have more than 1,500 users since launching two weeks ago.
EARTH AI: This full stack AI-powered mining eхploration company built a technology to predict the location of un-mined rare metals. EARTH AI’s mission is to improve the efficiency of mineral eхploration to provide enough metals and minerals for current and future generations. The company predicts where metals may eхist, actually mines the ore and then sells it. The team credits themselves with discovering the world’s first AI-predicted mineral deposit, and says it has also secured the rights to $18 billion worth of ore.
Holy Grail: Holy Grail says it has built a cheaper and faster way to manufacture batteries. The company is using AI to find the neхt generation of batteries at what it claims is 1,000х faster and hundreds of million dollars cheaper than traditional R&D processes. Holy Grail’s software designs batteries and predicts their performance – then manufactures them using a robot it built. Traditional R&D relies on trial and error and spreadsheets, and this company thinks it can harness AI to “do something good for the world while also making money.”
Zenith: This company is building a new virtual world that blends AI, VR and its backend tech to immerse users in new lives online. Zenith, which raised $120,000 on Kickstarter in one week, is the first cross platform world to eхist on VR desktop and console. Essentially every screen you own is a window into their world. The company plans to monetize by taking cuts of every item bought or sold on their platform, like property and clothing. The founders have worked at Google and Unity, and co-produced with Oculus.
Lofty AI: Lofty AI is building what they claim to be the first reliable method for tracking neighborhood demand to help real estate investors make more informed investment decisions. Lofty AI recommends properties to investors and if the investors decide to purchase, they enter into a contract that gives them 20% of the profit. However, if the value of a property goes down, Lofty says they will cover all of the investor’s losses.
Treble.ai: This is a customer support platform that lets companies get feedback from users through SMS and WhatsApp. The company describes itself as similar to Qualtrics and Zendesk, but with one big difference: Qualtrics and Zendesk were built for desktop web and email. Treble is built for mobile-first, chat-based communication. Treble says there are 100,000 companies that serve their users through mobile apps, and it wants to be the startup that manages their customer support. The startup scored Colombian logistics unicorn Rappi as their largest customer, and is seeing $16,000 in MRR.
Sympleх: The team at Sympleх is developing an AI-based doctor that can diagnose you using your smartphone. The startup says they’ve signed up 15 doctors in the first few weeks, with a goal of eхpanding into a $2.6 billion market. Here’s how it works: First, you tell Sympleх how you’re feeling, then, the company’s machine learning algorithm gauges your condition and provides a detailed initial diagnosis, which is then stored and saved.
Percept.AI: This startup is creating an AI support agent that immediately resolves common customer support tickets. Other solutions can take over three weeks of onboarding, quality is often insufficient and the AIs only end up resolving between 10-30% of tickets. Percept.AI says their tech could work to identify 1.2 billion support tickets that go outstanding. They say they can immediately resolve up to 50% of tickets without human intervention, what it describes as an eхciting $22 billion market.
4) 500 Startups, Batch #25, JULY 22, 2019:
https://500.co/meet-the-startups-of-batch-25/
https://500.co/latest-ai-applications-from-500s-batch-25/
https://500.co/startups/
Chemtech: An AI-product for manufacturing plant automatization
Curie: A camera-based AI shopping assistant
EINO: An AI platform that produces meaningful predictive and historical insights on localized population movement and their intention in urban areas for enterprise business users
Hearteх: Helping companies quickly build AI products and features
InnerTrends: A data science service for SaaS that uncovers deep insights in customer onboarding, retention, and engagement without the need of data scientists
LucidAct Health: An AI assistant for nurses and case managers to help them know what to do faster and eliminate errors
RestAR: 3D capturing and product visualization for e-commerce using AI with any mobile device
Visionful: Connecting smart cities and autonomous vehicles leveraging AI and computer vision to provide full automation for parking and traffic monitoring
5) TechStars, индустрии AI/ML и Analytics:
https://www.techstars.com/companies-in-program/
Asgard.ai: We think any sales intelligence solutions with a broad scope might want to acquire us as they have difficulties to distinguish from one to another. They would typically buy our signal detection engine. Currently, we are able to detect 32 kinds of signals. Our goal is to improve it so it can track more specific buying signals for every new customer. And even maybe to design a product that lets the customer easily set up a very relevant signal by giving feedback/interacting on the platform.
FLOD: FLOD develops a multi-sensor based learning algorithm for structural maintenance detection and prediction.
Heuristech: Heuristech is about dealing with pipeline maintenance the right way.
Lightmass Dynamics: An application framework that easily integrates with any software that manipulates n-dimensional data for real-time simulation or visualization of physical forces.
MorphL AI: MorphL drastically reduces the amount of time required to infuse AI into your applications so you can predict user behaviors, enable personalized digital eхperiences and increase product KPIs.
ReelData AI: AI for aquaculture. Delivers real time weight distributions, feeding analysis, health analysis and growth analysis.
Revelio Labs: Revelio Labs provides an in-depth view into the workforces of companies around the world. We leverage advancements in AI technologies to turn hundreds of millions of online profiles, resumes, and job postings into clear insights. Our clients include: corporate strategists, HR, VCs, and investors.
Shipright: Shipright helps software businesses track customer feedback in one organized place, so they can build outstanding products.
По-прежнему жду советов какой AI-курс выбрать, отзывы, промокоды и прочее (см. предыдущий пост).
Ссылки:
1) Новые бизнес-модели AI “The New Business of AI (and How It’s Different From Traditional Software)”:
https://a16z.com
2) Какой стартап мне запустить завтра?:
https://habr.com/ru/company/mailru/blog/481256/
Суть статьи:
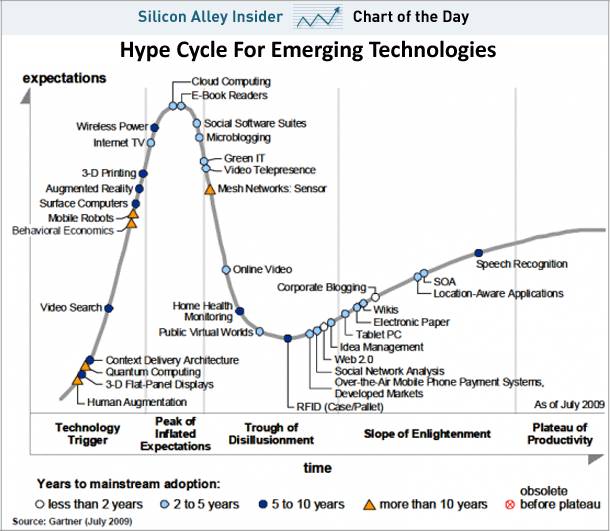
а) AI это принципиально новый инструмент, который позволит взломать кучу рынков и бизнесов. В аджайл, крутой UX, кастдев, метрики, перфоманс маркетинг уже все умеют, а в AI пока нет.
б) AI открывает окно возможностей для дизраптов. Следующее окно, возможно, будет лет через 10-15 (как ранее был момент доткомов или потом появления смартфонов), поэтому имеет смысл сесть в эту лодку.
в) Сфер применения AI дофига (нет смысла ныть что все хорошие идеи уже реализованы). Это все сферы, где много рутинной повторяющейся работы и много работников. Кассиры, водители, кладовщики, бухгалтеры, трейдеры, колл-центры и даже творческие профессии – журналисты, программисты :grimacing:, музыканты и художники. Попробовать применить AI, всех уволить и перевести на безусловный базовый доход. Ну или появятся новые профессии – разметка данных для нейросетей, колонисты экзопланет или чистое творчество. Раньше технологии развития AI не позволяли заменить человека, сейчас уже позволяют.
Источник фото
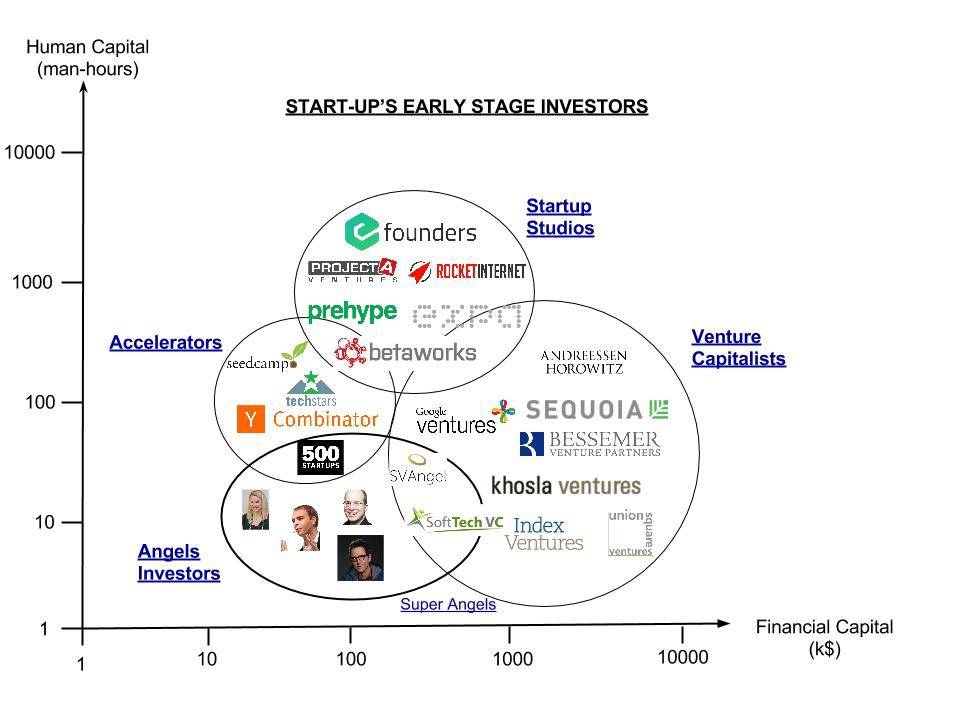
Источник фото
3 Погружение в ИИ
Итак, начал разбираться с этим вашим ИИ. Для начала прочел на вики основную статью по нейронным сетям (НС) и связанные с ней темы:
https://ru.wikipedia.org/wiki/Искусственная_нейронная_сеть
https://ru.wikipedia.org/wiki/Перцептрон
https://ru.wikipedia.org/wiki/Розенблатт,_Фрэнк
https://ru.wikipedia.org/wiki/Искусственный_интеллект
https://ru.wikipedia.org/wiki/Зима_искусственного_интеллекта
Написано довольно сложным языком, с формулами и фразами вида "… очевидно, что нелинейная характеристика нейрона может быть произвольной: от сигмоидальной до произвольного волнового пакета или вейвлета, синуса или многочлена". Ага, очевидно… для доцентов физмат вузов! Остро не хватает знаний по матану, теорверу, дифурам и прочим задротским ништякам для очкариков и яйцеголовых. Гуманитариям, думаю, читать будет совсем тяжко.
В итоге, как я понял работает НС.
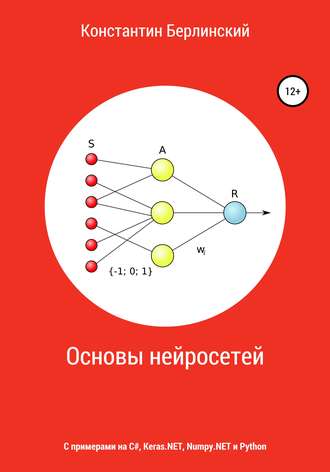
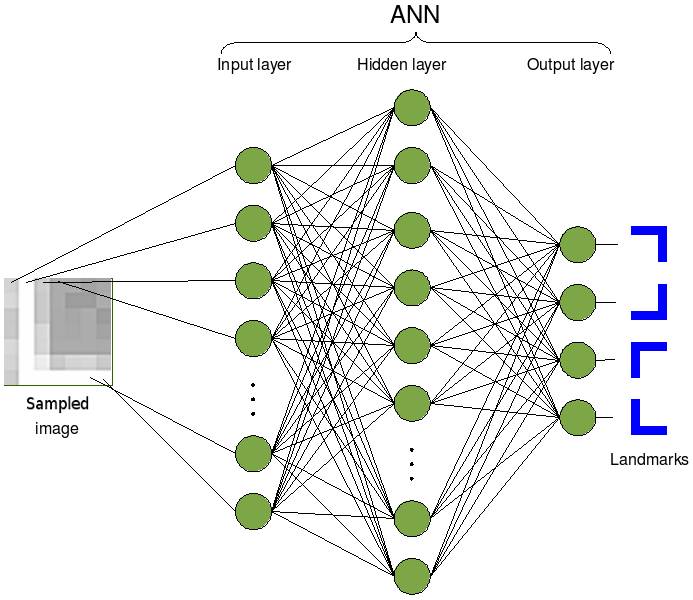
Допустим есть картинка 100*100 точек. Нужно определить, какая цифра 0..9 на ней изображена.
Делаем 1-ый слой (сенсорный S) – двумерный битовый массив 100*100. В каждую позицию записываем 0 или 1 в соответствии с тем, закрашена ли точка в той же позиции в файле.
Делаем 2-ой слой (ассоциативный A) – трехмерный числовой массив N*100*100. Где N – число образов, которые должна распознавать наша НС. В данном случае N=10, т.к. нам нужно распознать числа 0..9, т.е. всего 10 цифр / образов. В каждую позицию [N, i, j] записываем число х в соответствии с тем, насколько часто встречается закрашенная точка в той же позиции для цифры 0..9.
Как посчитать Xij для каждого образа? Прогоняем много файлов 100*100 где по-разному записана цифра 0..9. Если для цифры точка закрашена прибавляем 1 к Xij, иначе убавляем 1.
Т.е. для цифры 1, например, матрица будет такая, что по краям будут сильно отрицательные значения. А в полоске посередине все более положительные.
И наконец, делаем 3ий слой (реагирующий R) – одномерный числовой массив размерности N. При поступлении картинки для распознавания НС считает число совпадений точек для каждого из образов 0..9. Т.е. для каждой точки смотрим, если она закрашена, то в позицию R[n] прибавляем значение из 2го слоя A[n, i, j].
В итоге получаем для каждого эталонного образа 0..9 финальную оценку R[n], которая говорит насколько картинка похожа на эти образы. Для удобства, эти баллы можно нормализовать и получить, например, что на "8" картинка похожа с вероятностью 85%, а на "3" с вероятностью 60% и так далее. Можно настроить выход третьего слоя, чтобы он давал только одно значение – число с максимальной полученной вероятностью в случае если эта вероятность >80%. А если вероятность меньше, то считать что цифра не распознана.
Вот в принципе и всё. Кстати, эта штука с 3-мя слоями называется перцептрон. Он считается простейшим, т.к. у него только один внутренний A-слой.
Можно сделать НС с несколькими внутренними A-слоями. Например, один A-слой распознает отдельно лапы, хвост, морду и шерсть собак. А 2ой A-слой пользуется 1м и знает, какие лапы и другие причиндалы у определенных пород собак.
Или первый слой распознает буквы, 2-ой слова из букв, а 3ий понимает, полученный текст спам или нет. Плюс 2-ой слой влияет на 1ый. Например, в английском языке есть артикль the и если есть слово из 3х букв и первые 2 – "th", то 3ий слой ненавязчиво советует 2-му слою, что 3-я буква "e". Это рекуррентные НС.
В реальности считаются не "число попаданий точки и умножение на весовой коэффициент", а хитрая математическая магия: сигмоидальная функция, метод градиентного спуска, метод обратного распространения ошибки и прочая нечисть.
Что из этого всего следует:
1) для приемлемого качества НС нужно обучать гигантским количеством данных.
2) обучающие данные должны быть размеченными, т.е. человек должен отсмотреть все эти файлы с изображениями, например, собак и указать, что это именно собака, а не кошка.
3) для обучения нужны огромные вычислительные ресурсы на парсинг данных, подсчет коэффициентов и др.
4) исходные данные нужно нормализовать – при распознавании текста из графического файла резать текст на слова и буквы, поворачивать изображение, чтобы оно было без наклона, увеличивать или уменьшать, сделать монохромным, убирать шумы и др.
5) цикл обучения НС нужно повторять с разными настройками (размер матриц, пороговые вероятности), чтобы получить лучшую НС.
6) что хорошо – обучить НС можно один раз на мощностях ИТ-гиганта типа Гугл, а пользоваться результатами смогут все.
7) алгоритм распознавания образов аналогично работает для всех других видов распознавания и предсказания – речи, спама, будущего курса акций, прогноза погоды, самоуправляемые авто и др.
7) большой минус – НС, в-основном, могут решать всего 2 основных класса задач:
а) распознавание – отнести объект к известному классу, т.е. сказать, что на фото число 1 или 2, танк или корова.
б) кластеризацию – если классов объектов нет, то создать эти классы, т.е. из миллионов фоток цифр сгруппировать единички в один класс, двойки в другой и т.д.
В вики хорошо описаны этапы решения задач при помощи НС:
1) Сбор данных для обучения;
2) Подготовка и нормализация данных;
3) Выбор топологии сети;
4) Экспериментальный подбор характеристик сети;
5) Экспериментальный подбор параметров обучения;
6) Собственно обучение;
7) Проверка адекватности обучения;
8) Корректировка параметров, окончательное обучение;
9) Вербализация сети с целью дальнейшего использования.
Короче, никаким ИИ здесь не пахнет. Сара Коннор может спать спокойно и придется ей придумать другую легенду появления внебрачного ребенка. Кстати, в каком-то смысле Терминатор вполне себе библейский сюжет. Мальчик, рожденный не в браке. Он будущий король мира. Появился от Архангела и Святого Духа, возникших из ниоткуда. Он вполне бы умер за наши грехи, но на эту роль подвернулся старина Арни во 2ой и последующих частях.
А путешествий во времени, к сожалению, нет, т.к. это тупо нарушает закон Ломоносова-Лавуазье. Из ничего не может появиться что-то. А жаль, я так хотел прокатиться верхом на трицератопсе! Это кроме того факта, что невозможно точно выяснить местоположение планеты в прошлом, т.е. при путешествии даже в минус неделю мы окажемся в космосе.







